本文主要是介绍(自用)learnOpenGL-高级OpenGL-高级数据、高级glsl,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高级数据
这一节中,我们将讨论一些更有意思的缓冲函数,以及我们该如何使用纹理对象来储存大量的数据(纹理的部分还没有完成)。
先来回顾一下之前有关的缓冲内存,OpenGL中的缓冲只是一个管理特定内存块的对象,没有其它更多的功能了。在我们将它绑定到一个缓冲目标(Buffer Target)时,我们才赋予了其意义。当我们绑定一个缓冲到GL_ARRAY_BUFFER时,它就是一个顶点数组缓冲,但我们也可以很容易地将其绑定到GL_ELEMENT_ARRAY_BUFFER。OpenGL内部会为每个目标储存一个缓冲,并且会根据目标的不同,以不同的方式处理缓冲。
就像是VBO是在array-buffer上,EBO是在element-buffer上。
然后通过bufferdata来填充数据。
除了使用一次函数调用填充整个缓冲之外,我们也可以使用glBufferSubData,填充缓冲的特定区域。这个函数需要一个缓冲目标、一个偏移量、数据的大小和数据本身作为它的参数。
这个函数不同的地方在于,我们可以提供一个偏移量,指定从何处开始填充这个缓冲。这能够让我们插入或者更新缓冲内存的某一部分。要注意的是,缓冲需要有足够的已分配内存,所以对一个缓冲调用glBufferSubData之前必须要先调用glBufferData。
这什么意思?就是我们可以在渲染过程中去修改参数。
glBufferSubData(GL_ARRAY_BUFFER, 24, sizeof(data), &data); // 范围: [24, 24 + sizeof(data)]将数据导入缓冲的另外一种方法是,请求缓冲内存的指针,直接将数据复制到缓冲当中。通过调用glMapBuffer函数,OpenGL会返回当前绑定缓冲的内存指针,供我们操作:
float data[] = {0.5f, 1.0f, -0.35f...
};
glBindBuffer(GL_ARRAY_BUFFER, buffer);
// 获取指针
void *ptr = glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY);
// 复制数据到内存
memcpy(ptr, data, sizeof(data));
// 记得告诉OpenGL我们不再需要这个指针了
glUnmapBuffer(GL_ARRAY_BUFFER);如果要直接映射数据到缓冲,而不事先将其存储到临时内存中,glMapBuffer这个函数会很有用。比如说,你可以从文件中读取数据,并直接将它们复制到缓冲内存中。
分批顶点属性(储存顶点数据的两种方法)
通过glVertexAttribPointer,我们能够指定顶点数组缓冲内容的属性布局。不过呢,现在数据存放的方式是 一个顶点的位置等属性都放在一起。
我们还可以把顶点的位置放一起,法向放一起,纹理坐标放一起。使用glbuffersubdata
float positions[] = { ... };
float normals[] = { ... };
float tex[] = { ... };
// 填充缓冲
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(positions), &positions);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions), sizeof(normals), &normals);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions) + sizeof(normals), sizeof(tex), &tex);也就是当有这种分散的数据的时候,用这个更方便。
顶点属性也需要改变
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), 0);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)(sizeof(positions)));
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)(sizeof(positions) + sizeof(normals)));注意stride参数等于顶点属性的大小,因为下一个顶点属性向量能在3个(或2个)分量之后找到。
复制缓冲
当你的缓冲已经填充好数据之后,你可能会想与其它的缓冲共享其中的数据,或者想要将缓冲的内容复制到另一个缓冲当中。glCopyBufferSubData能够让我们相对容易地从一个缓冲中复制数据到另一个缓冲中。

glsl的内建变量
我们在写顶点和片段的时候已经碰到了内建变量了一个是gl_position和gl_fragcoord
不过在顶点着色器中还有其他的。
gl_PointSize
在loop中draw中我们一般都是用gl_triangls画三角形,我们可以用gl_point来画点,那么就需要在顶点着色器里面设置这个点的大小。
不过在顶点着色器中修改点的大小首先需要开启修改功能,然后再修改。
glEnable(GL_PROGRAM_POINT_SIZE);...
void main()
{gl_Position = projection * view * model * vec4(aPos, 1.0); gl_PointSize = gl_Position.z;
}例如将点的大小设置为裁剪空间位置的z值,也就是顶点距观察者的距离。点的大小会随着观察者距顶点距离变远而增大。这一点再粒子生成的技术中很有意思。
gl_VertexID
gl_Position和gl_PointSize都是输出变量,因为它们的值是作为顶点着色器的输出被读取的。我们可以对它们进行写入,来改变结果。顶点着色器还为我们提供了一个有趣的输入变量,我们只能对它进行读取,它叫做gl_VertexID。
整型变量gl_VertexID储存了正在绘制顶点的当前ID。当(使用glDrawElements)进行索引渲染的时候,这个变量会存储正在绘制顶点的当前索引。当(使用glDrawArrays)不使用索引进行绘制的时候,这个变量会储存从渲染调用开始的已处理顶点数量。
虽然现在它没有什么具体的用途,但知道我们能够访问这个信息总是好的。
gl_FragCoord
这个就是片段在viewpoint的坐标位置,z也就是对应的深度值。
我们现在来修改下x,y来实现一些其他效果。
gl_FragCoord的x和y分量是片段的窗口空间(Window-space)坐标,其原点为窗口的左下角。我们已经使用glViewport设定了一个800x600的窗口了,所以片段窗口空间坐标的x分量将在0到800之间,y分量在0到600之间。
通过利用片段着色器,我们可以根据片段的窗口坐标,计算出不同的颜色。gl_FragCoord的一个常见用处是用于对比不同片段计算的视觉输出效果,这在技术演示中可以经常看到。比如说,我们能够将屏幕分成两部分,在窗口的左侧渲染一种输出,在窗口的右侧渲染另一种输出。下面这个例子片段着色器会根据窗口坐标输出不同的颜色:
void main()
{ if(gl_FragCoord.x < 400)FragColor = vec4(1.0, 0.0, 0.0, 1.0);elseFragColor = vec4(0.0, 1.0, 0.0, 1.0);
}所以我们现在可以用两个不同的着色器,在屏幕的两边测试不同的光照技巧。
gl_FrontFacing
在面剔除里面提到了一个面的正向面和背向面,这里的gl_frontfacing就可以告诉我们现在这个面是正还是背,所以我们可以通过这个bool值来实现一个面的正背面的不同效果。
gl_FragDepth
在刚刚的fragcoord中,我们只能读取,不能修改。但是我们还是可以通过其他想法来修改的。
gl_fragdepth如果我们不去写入值的话,在输出的时候就会自动提取coord中的z。
然而,由我们自己设置深度值有一个很大的缺点,只要我们在片段着色器中对gl_FragDepth进行写入,OpenGL就会(像深度测试小节中讨论的那样)禁用所有的提前深度测试(Early Depth Testing)。它被禁用的原因是,OpenGL无法在片段着色器运行之前得知片段将拥有的深度值,因为片段着色器可能会完全修改这个深度值。

接口块
在着色器中,我们都是通过out in uniform来传递单个变量。先来我们来用一个块来整体传数据,和之前的struct差不过,不过现在前面是in 或者out。
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoords;uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;out VS_OUT
{vec2 TexCoords;
} vs_out;void main()
{gl_Position = projection * view * model * vec4(aPos, 1.0); vs_out.TexCoords = aTexCoords;
} 这种在几何着色器中特别有用哦
uniform缓冲对象
在之前写loop中要不断地设置uniform特别麻烦,所以现在学一个简单的方法-uniform缓冲对象,当使用Uniform缓冲对象的时候,我们只需要设置相关的uniform一次。当然,我们仍需要手动设置每个着色器中不同的uniform。并且创建和配置Uniform缓冲对象会有一点繁琐。
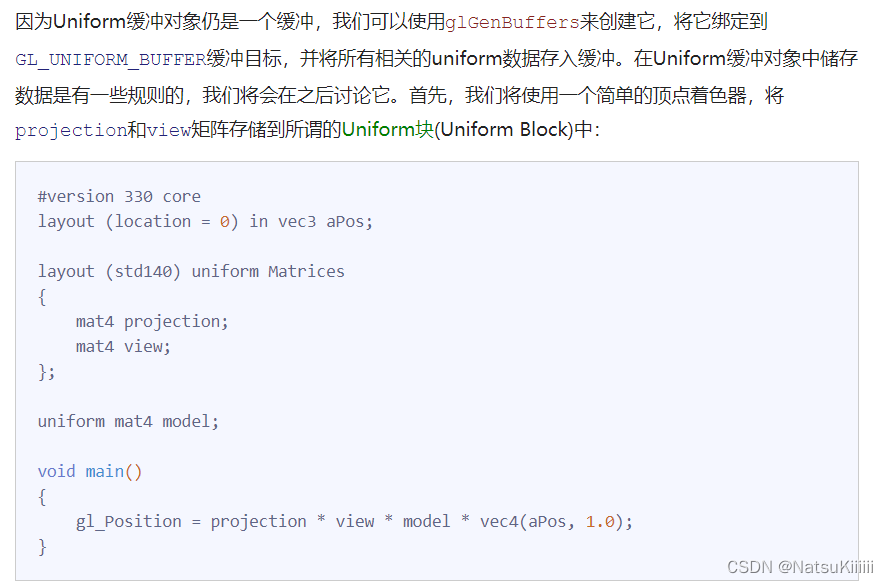
在前面的layout(std140)表示的意思就是这是了uniform块布局,表示的是这些数据在内存里面的排放顺序,所以我们可以自己手动算出这些量的偏移量是多少从而拿到。
如何使用呢
首先需要调用genbuffer来给我们创建一个缓冲对象,然后绑定到uniform-buffer上,并分配足够的内存给他。
unsigned int uboExampleBlock;
glGenBuffers(1, &uboExampleBlock);
glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
glBufferData(GL_UNIFORM_BUFFER, 152, NULL, GL_STATIC_DRAW); // 分配152字节的内存
glBindBuffer(GL_UNIFORM_BUFFER, 0);之后每次需要更新缓冲数据或者插入数据就是用glbuffersubdata来更新。

现在我需要往shader里面传数据了,但是我需要把对应的缓冲对象和shader对应好。在opengl里面uniform变量都是在一串绑定点上面的,a和b的matrices都在0号上,所以我们也需要把对应的缓冲对象绑在0号上。

这里是我们手动把shader里面的light变量放在2号上,然后接着把缓冲对象也放到2号上。

实战
我们把程序里面的vp矩阵都放进去,因为基本都没怎么变过。
这里我就先不改了。
这篇关于(自用)learnOpenGL-高级OpenGL-高级数据、高级glsl的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






