本文主要是介绍Python爬虫编程思想(62): 项目实战:抓取酷狗网络红歌榜,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文的案例会使用requests抓取酷狗的网络红歌榜,并使用Beautiful Soup库的CSS选择器分析抓取到的HTML代码,并将提取的信息显示在Console上。
首先在Chrome浏览器中使用下面的URL打开网络红歌榜页面。
https://www.kugou.com/yy/rank/home/1- 23784.html?from=rank
页面效果如图1所示。
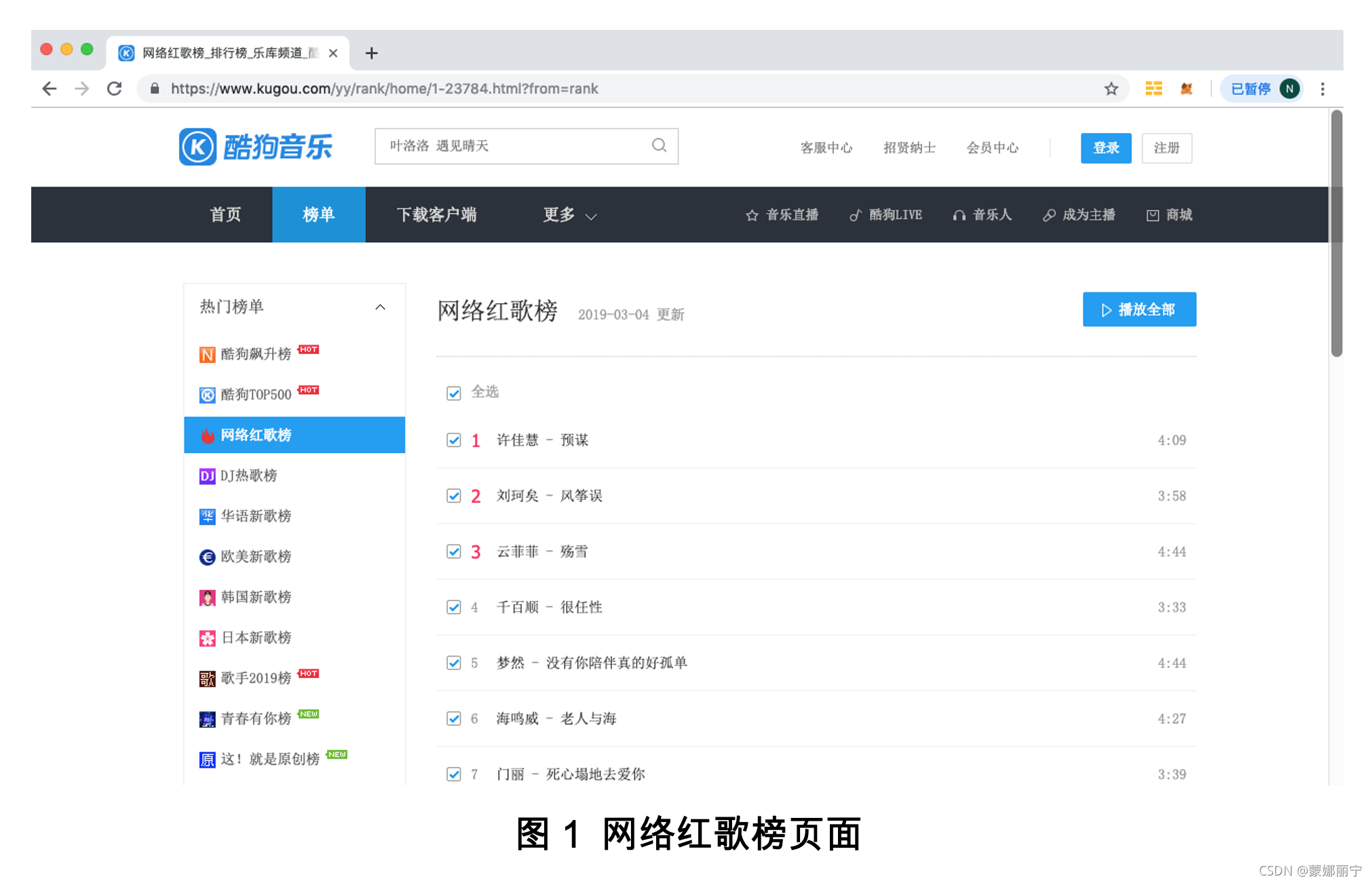
网络红歌榜页面下方并没有用于切换页面的数字导航条,不过从URL的样子可以尝试一下,例如1-
这篇关于Python爬虫编程思想(62): 项目实战:抓取酷狗网络红歌榜的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







