本文主要是介绍【Pyhton爬虫一】requests与BeautifulSoup,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
requests与BeautifulSoup基础入门
1. 前言
最近在学习python爬虫,以前实现python爬虫,主要是使用较为底层的urllib和urllib2来实现的,这种方法最原始,编码起来也比较困难。而采用requests + BeautifulSoup的实现方案,可以简化代码的书写。如果有不好和错误的地方希望大佬指出。
2. 介绍
- 在使用这两个模块之前,需要对这两个模块做一些介绍:requests是基于urllib,采用 Apache2 Licensed 开源协议的 HTTP 库,比 urllib 更加方便。BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,实际上,它将html中的tag作为树节点进行解析。
- requests官方文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
- BeautifulSoup官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
3. 实现代码
首先是引入这2个库,这里我使用的是PyCharm编辑器,通过Settings→Project: WorkSpace→Project Interpreter寻找bs4和requests库。pip方法引入第三方库请自行百度。
先从最简单的开始,点进糗事百科首页
import requests # 导入requests模块
res = requests.get("http://www.qiushibaike.com") # 获取糗事百科首页
print (res.text) # print(res)打印的是响应码,print(res.text)打印的是首页的源代码
得到页面源码,如果发现页面文字是乱码,则是编码的原因,输出页面的编码
print (res.encoding)

如果不是UTF-8,可以设置为UTF-8
res.encoding = "utf-8"
点进一篇文章,按F12进入开发者工具,按住ctrl+shift+c或者是点击左上角的剪头选中页面中的文章
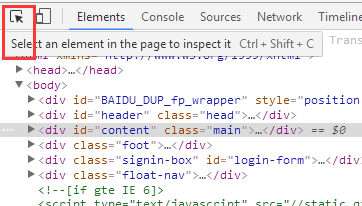
发现其class是content
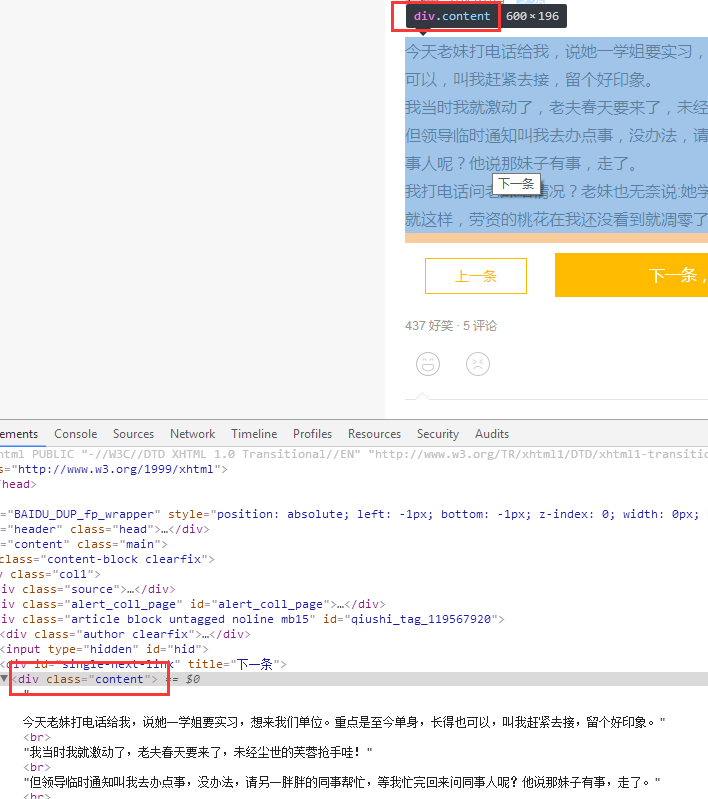
# 获取文章内容
import requests
from bs4 import BeautifulSoup
res = requests.get("https://www.qiushibaike.com/article/119567920")
soup = BeautifulSoup(res.text, "html.parser") # 把我们需要的内容放到BeautifulSoup中,html.parser是一个解析器
div = soup.find_all(class_="content")[0] # 找寻class为content的内容
print(div.text.strip()) # 输出文章内容

如果要获取首页一页的文章内容,则通过开发者工具查看首页,发现每个文章的页面class为article block untagged mb15 typs_xxxx
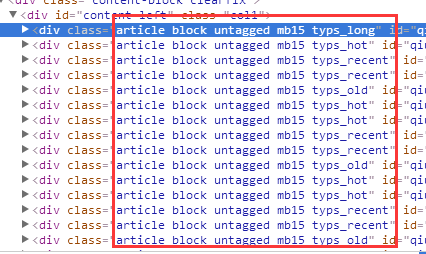
用re来匹配各种文章的class。
Python3正则表达式:http://www.runoob.com/python3/python3-reg-expressions.html
# 获取所有文章的内容
import requests
from bs4 import BeautifulSoup
import reres = requests.get("http://www.qiushibaike.com")
soup = BeautifulSoup(res.text, "html.parser")
divs = soup.find_all(class_=re.compile(r'article block untagged mb15 typs_(\w*)')) # 所有文章是一个数组
for div in divs: # 循环取出joke = div.span.get_text()print(joke.strip())print("------")
输出内容后发现有些内容读起来很奇怪,看页面发现有些是有图片的,图片的网页标签(HTML tag)是img。

所以我们要把有图片的文章过滤掉,发现有图片文章有个class为thumb,则我们把有图片的过滤掉
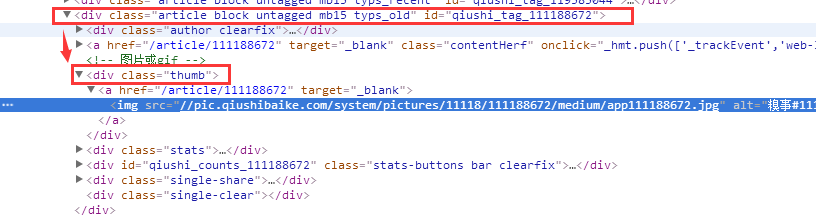
# 获取一页没有图片的文章
import requests
from bs4 import BeautifulSoup
import reres = requests.get("http://www.qiushibaike.com")
soup = BeautifulSoup(res.text, "html.parser")
divs = soup.find_all(class_=re.compile(r'article block untagged mb15 typs_(\w*)')) # 匹配class
for div in divs:if div.find_all(class_="thumb"): # 如果有图片则过滤continuejoke = div.span.get_text()print(joke.strip())print("------")
但是糗事百科有很多页,点击第二页发现网址为:https://www.qiushibaike.com/8hr/page/2/ ,点击第三页发现网址为:https://www.qiushibaike.com/8hr/page/3 ,所以我们只需要将网址最后的数字变动即可得到其他页面
# 获取前几页的文章
import requests
from bs4 import BeautifulSoup
import rebase_url = "https://www.qiushibaike.com/8hr/page/"
for num in range(1, 3): # 设置循环,让num分别等于1-3,获取前3页内容print('第{}页:'.format(num))res = requests.get(base_url + str(num)) # 这里对网址后面加上数字soup = BeautifulSoup(res.text, "html.parser")divs = soup.find_all(class_=re.compile(r'article block untagged mb15 typs_(\w*)'))for div in divs:if div.find_all(class_="thumb"):continuejoke = div.span.get_text()print(joke.strip())print("------")print("\n\n\n\n\n\n\n")
这篇关于【Pyhton爬虫一】requests与BeautifulSoup的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





