本文主要是介绍Elasticsearch:使用 SIMD 指令加速向量搜索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Chris Hegarty, Elastic Principal Engineer, Lucene PMC
翻译:杰瑞朱

多年来,Java 平台上运行的代码一直受益于自动向量化 —— HotSpot C2 编译器中的 superword 优化,将多个标量操作打包到 SIMD(单指令多数据)向量指令中。这很好,但是这些类型的优化有些脆弱,具有天然的复杂性限制,并且受到 Java 平台规范的约束(例如,浮点运算的严格排序)。这并不是说这样的优化不再有价值,只是在某些情况下,明确代码的写法可以获得明显更好的性能。Lucene 中支持向量搜索的低级底层操作就是这样一种情况。
本文将介绍 Lucene 向量搜索中使用的底层操作,它们如何在运行时可靠地编译为 SIMD 指令(例如 x64 上的 AVX 指令和 AArch64 上的 NEON 指令),以及这对性能有何影响。
底层操作
Lucene 向量搜索实现的核心在于查找两个向量之间的相似性时使用的三个底层操作:点积、平方和余弦距离。这些操作都有浮点和二进制变体。为了简洁起见,我们只看这些基本操作之一 —— 点积。界面很简单,如下所示:

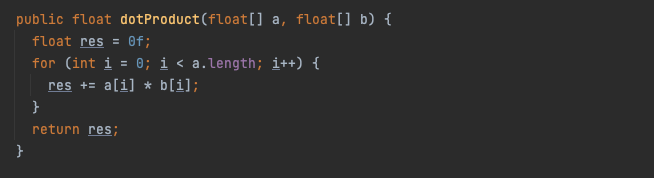
到目前为止,这些原始操作的背后是用标量(scalar)计算来实现的,并通过使用现有的技术(例如手动展开循环)来优化性能。如果你正在编写 Java 代码,这已经是最好的了 — 其余的我们留给 HotSpot 即时编译器来尽其所能进行优化(例如,自动向量化)。这是 dot 的简化标量实现产品,已删除展开(真正的实现可以在这里看到):
最近的变化是,JDK 现在提供了一个用于表达计算的 API,这些计算可以在运行时可靠地编译为 SIMD 指令。这是 OpenJDK 的项目 Panama 向量 API。当然,运行时生成的实际指令取决于底层平台支持的内容(例如 AVX2 或 AVX 512),但 API 的结构是为了满足这一点。同样,这是点积代码的简化版本,但这次使用 Panama 向量 API:
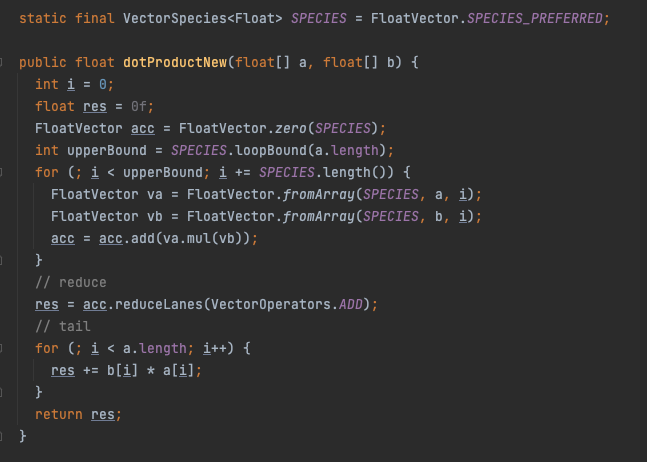
你可以看到代码有点冗长,但它是直观易懂的,并且很容易推理出它在运行时如何映射到硬件,因为你可以在代码中看到向量运算。VectorSpecies 包含元素类型(在我们的例子中为浮点数)和形状(向量的位大小)。优选的种类是平台的最大位大小之一。首先,有一个循环迭代输入,相乘并累加 SPECIES::length 一次元素。其次,汇总累加器向量。最后,一个标量循环处理任何剩余的“尾部”元素。
当我们在支持 AVX 512 的 CPU 上运行此代码时,我们看到 HotSpot C2 编译器发出 AVX 512 指令。高级向量扩展 (AVX) 已广泛使用,例如基于英特尔 Ice Lake 微架构的 CPU 和基于此类架构的云计算实例(例如 GCP 或 AWS)。AVX 512 指令一次跨过点积计算 16 个值;512 位大小 / 每个值 32 位 = 每次循环迭代 16 个值。当在支持 AVX2 的 CPU 上运行时,同一代码的一次循环迭代每次迭代都会跨过 8 个值。同样,NEON(128 位)每次循环迭代将跨过 4 个值。
要看到这一点,我们需要查看生成的代码。开始有趣的探索吧!
看看原生代码
以下是 dotProduct 的 HotSpot C2 编译器在支持 AVX 512 的 Rocket Lake 上运行时的反汇编。
下面的代码片段包含主循环体,其中 rcx 和 rdx 寄存器保存指向第一个和第二个浮点数组的地址。
- 首先,我们看到一条 vmovdqu32 指令,该指令将 512 位打包双字值从内存位置加载到 zmm0 寄存器中,即从偏移量到第一个 float[] 的 16 个值。
- 其次,我们看到一条 vmulps 指令,它将先前加载到 zmm0 中的打包单精度浮点值与内存位置中相应的打包双字值相乘 - 这是第二个 float[] 中偏移量的 16 个值,并存储生成的浮点值- zmm0中的点值。
- 第三,我们看到 vaddps 将 zmm0 中的 16 个打包单精度浮点值与 zmm4 相加,并将打包单精度浮点结果存储在 zmm4 中 - zmm4 是我们的循环累加器。
- 最后,有一个小的计算来递增并检查循环计数器。
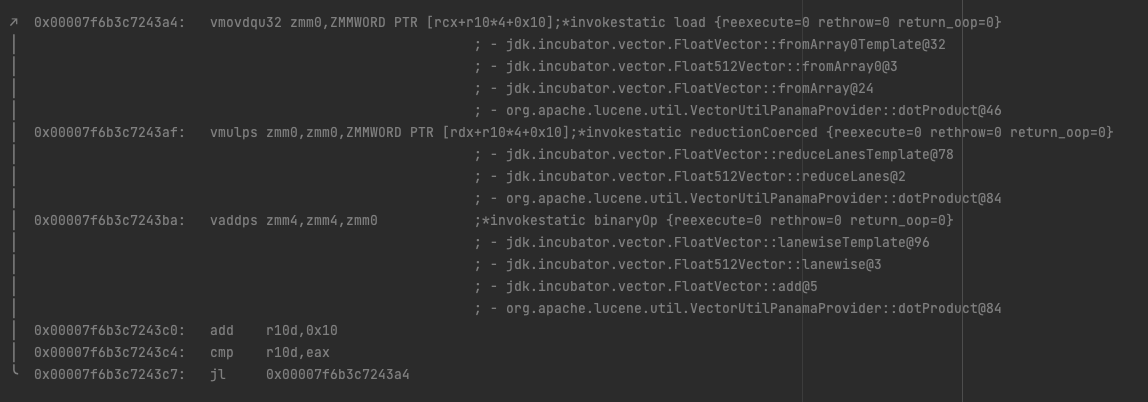
不要太担心反汇编的具体细节——提供它们是为了让人们更多地了解“幕后”发生的事情,但不需要非常充分的了解。事实上,上面的内容有些简化,因为实际发生的是 C2 展开循环,一次跨过 4 次迭代。
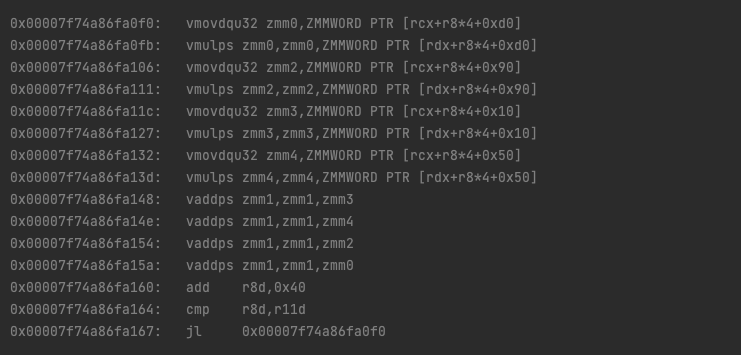
我们在每次迭代中使用更多的寄存器和指令。好的!更重要的是,我们的 Lucene 代码 手动也展开了循环,又是 4 倍(嗯...展开量很大)。
那么,这样能更快吗?
为了评估重写此类低级操作的影响,我们求助于 JMH,这是对此类 Java 代码执行微基准测试的普遍接受的方法。在这里,我们使用了 Robert Muir 非常好用且方便的一组基准测试,使我们能够快速比较代码变体之前和之后。
请记住,SIMD 提供数据并行性,因此我们处理的数据越多,潜在的好处就越大。在我们的例子中,这与向量的维度大小直接相关——我们期望看到更大的维度大小带来的更大好处。让我们看看在支持 AVX 512 的 CPU 上运行时,具有 1024 维向量的点积的浮点变体;英特尔酷睿 i9-11900F @ 2.50GHz:

该基准测试每微秒的操作次数,因此越大越好。在这里,我们看到新点积的执行速度比旧点积快大约八倍。我们看到不同的低级底层操作(无论是浮点数还是二进制)都有类似的性能提升:

我们看到所有原始操作变体以及各种从小到大的维度大小都有显着的改进(这里没有显示,但可以在 Lucene PR 中看到)。这一切都很棒,但这与更高级别的工作负载有何关系?
放到宏观看看
微基准测试对于了解低级基元操作的执行情况非常重要,但这对宏观层面有何影响?为此,我们可以查看 Elasticsearch的向量搜索基准,即 SO Vector 和 Dense Vector。两个基准测试都显示出显着的改进,但让我们看看 SO Vector,因为它更有趣,因为它比 Dense Vector 具有更高的向量维度。
SO Vector 基准测试使用 200 万个 768 维向量和带过滤的 kNN 来测试向量搜索性能。这些向量基于从 StackOverflow 帖子转储中导出的数据集。Elasticsearch 使用单节点集群在 GCP 上运行,在具有 8 个 vCPU、16GB RAM 和 1x300GiB SSD 磁盘的自定义 n2 实例上运行。该节点有一个固定到 Ice Lake 的 CPU 平台。
基准测试中存在很多预先存在的差异,但总的来说,我们看到了积极的改进:
- 索引吞吐量提高了约 30%。
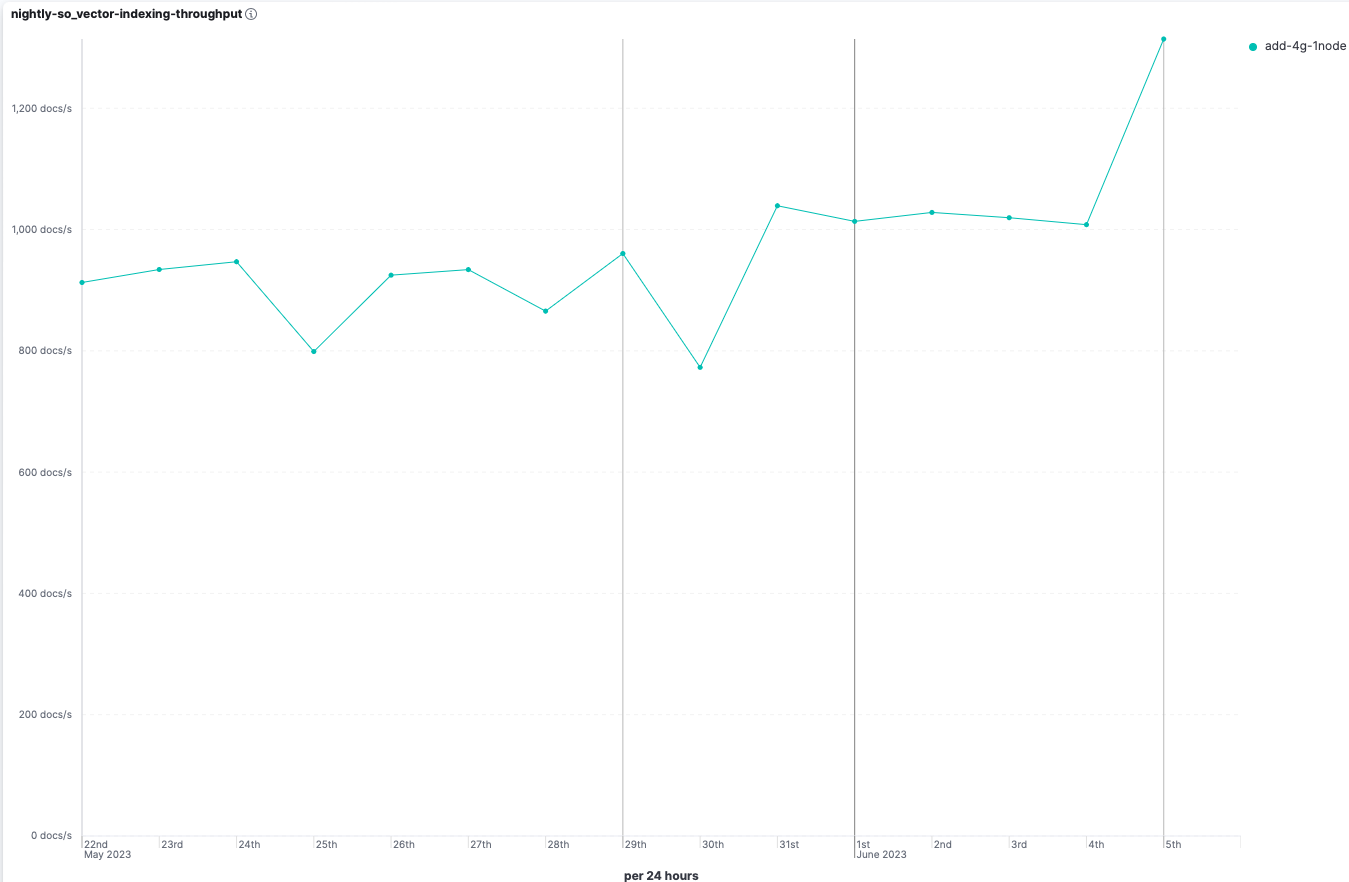
- 合并时间减少了约 40%。
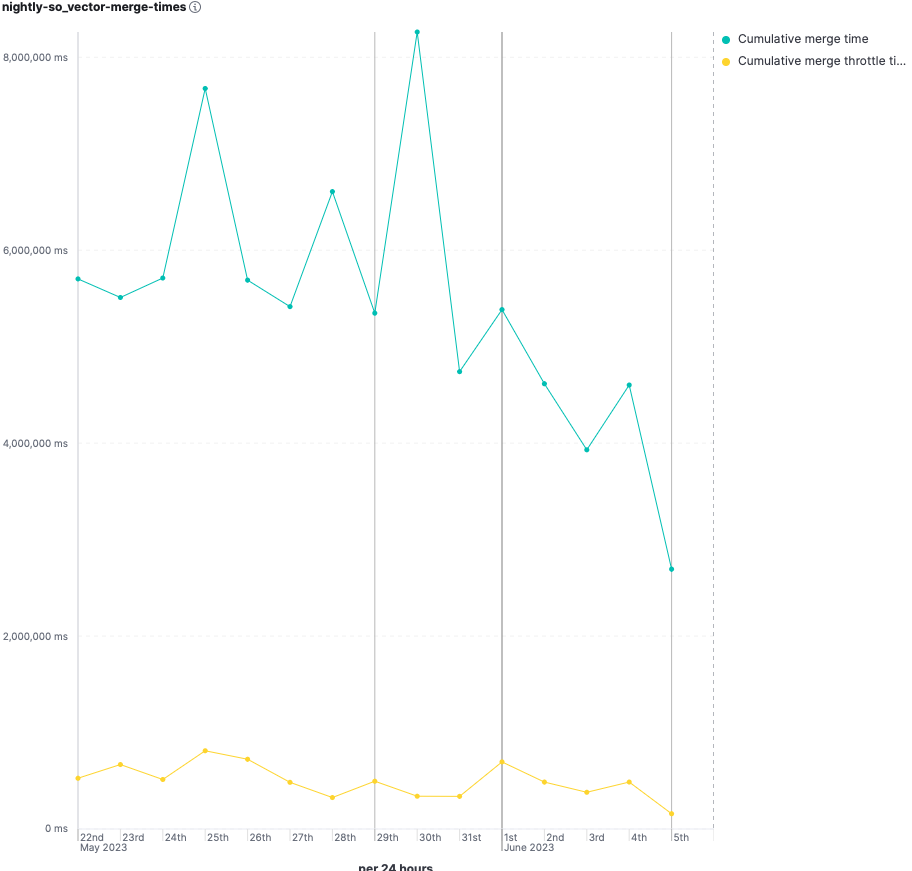
- 查询延迟显著改善。
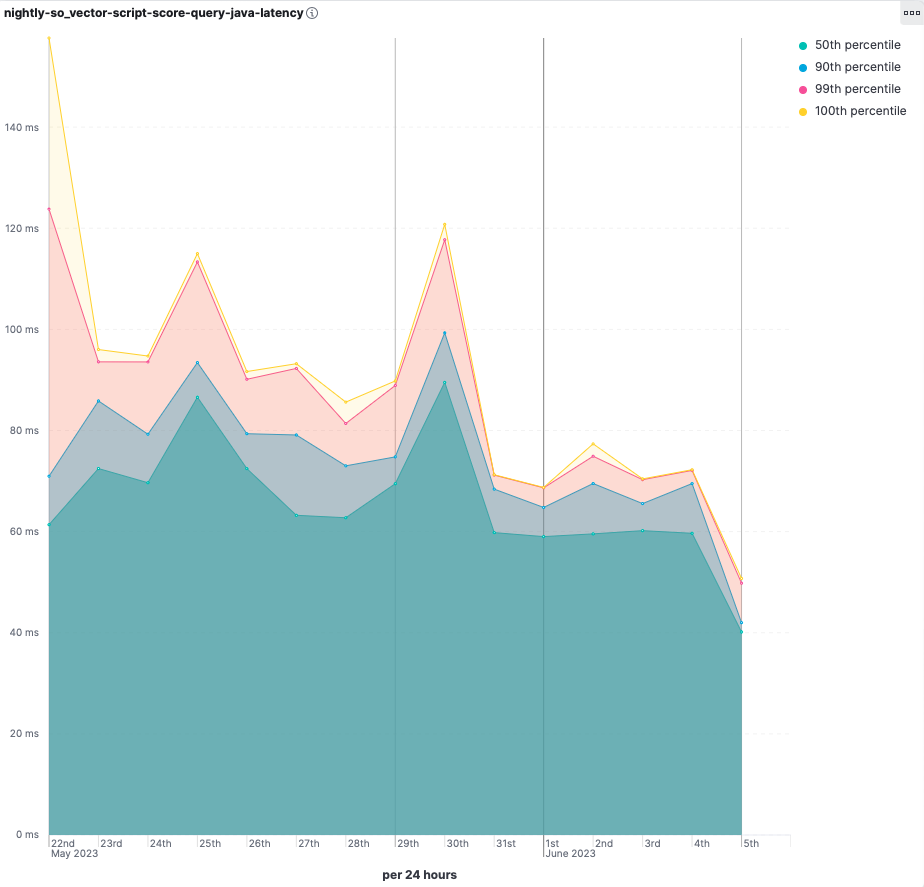
但是 Panama 向量 API 不是真正孵化中吗?
JDK Vector API 正在 Panama 项目中开发,目前已经孵化了一段时间。孵化状态并不反映其质量,而更多的是依赖 OpenJDK 中其他令人兴奋的工作(即值类型)的结果。Lucene 正在 “前沿” 开辟道路,并拥有一种利用 JDK 中非最终 API 的新颖方法 —— 通过构建包含 JDK 版本特定 API 的 “apijar” —— 感谢 Uwe。这是一种务实的做法,我们不会掉以轻心。与生活中的大多数事情一样,这是一个权衡。只有当潜在收益超过维护成本时,我们才会考虑采用非最终 JDK API。Lucene 仍然具有这些低级底层操作的标量实现版本。更快的 Panama 实现可在 JDK 20 和即将推出的 JDK 21 上使用,而我们会在某些不适用的情况下回退到旧版 JDK 的标量实现。同样,在平衡潜在收益与维护成本时,仅支持最新的 JDK 版本是一个务实的选择。
总结
现在,我们可以使用 Panama 向量 API 编写可靠地利用硬件加速 SIMD 指令的 Java 代码。在 Lucene 9.7.0 中,我们添加了更快地实现向量搜索所使用的底层操作的功能。Elasticsearch 8.9.0 默认情况下开箱即用地启用了这种更快的实现,因此你无需执行任何操作即可获得改进的性能优势。我们在向量搜索基准测试中看到了显着的性能改进,并期望这能够转化为用户工作负载。
SIMD 指令并不新鲜,并且已经存在很长时间了。与往常一样,你需要进行自己的性能基准测试,以了解这对你的环境产生的影响。AVX 512 很酷,但它可能会遭受可怕的 “降频” 的困扰。总体而言,我们看到这一变化带来了全面的积极改进。
最后,我想感谢 Lucene PMC 成员 Robert Muir 和 Uwe Schindler,感谢他们愉快而富有成效的合作,促成了这一改进,没有他们,这一切就不会发生。
这篇关于Elasticsearch:使用 SIMD 指令加速向量搜索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






