simd专题

SimD:基于相似度距离的小目标检测标签分配
摘要 https://arxiv.org/pdf/2407.02394 由于物体尺寸有限且信息不足,小物体检测正成为计算机视觉领域最具挑战性的任务之一。标签分配策略是影响物体检测精度的关键因素。尽管已经存在一些针对小物体的有效标签分配策略,但大多数策略都集中在降低对边界框的敏感性以增加正样本数量上,并且需要设置一些固定的超参数。然而,更多的正样本并不一定会带来更好的检测结果,事实上,过多的正样本

ARM SIMD instruction -- movi
MOVI Move Immediate (vector). This instruction places an immediate constant into every vector element of the destination SIMD&FP register。 立即移动(向量)。此指令将一个立即常数放入目标SIMD&FP寄存器的每个向量元素中。
【Rust日报】 2019-05-23:性能强悍的 blake2b_simd 和 blake2s_simd 姐妹花
性能强悍的 blake2b_simd 和 blake2s_simd 姐妹花 BLAKE 和 BLAKE2 是密码学哈希函数,来源于 Dan Bernstein 的 ChaCha。特点是在64位机上,性能比 SHA-3, SHA-2, SHA-1, 和 MD5 等都高。属于目前最高性能的哈希函数之一。而这两个库的实现,也在追求性能的极致。 以下是一些性能评测数据: ╭─────────────
【Rust日报】2021-11-15 SIMD模块 nightly 已可用
std::simd nightly 可用 可以移植的 SIMD 模块. 该模块提供了一个可移植的不绑定于任何硬件架构的 SIMD 操作的抽象。目前 nightly-only. 原文链接: https://doc.rust-lang.org/nightly/std/simd/index.html 静态分析器 Rudra 在 Rust crates 中找到超过 200 个内存安全问题 Rudra是一

C++ SIMD性能优化
// 使用SIMD指令优化的向量加法//<mmintrin.h> MMX//<xmmintrin.h> SSE//<emmintrin.h> SSE2//<pmmintrin.h> SSE3//<tmmintrin.h> SSSE3//<smmintrin.h> SSE4.1//<nmmintrin.h> SSE4.2//<wmmintrin.h> AES//<immintrin

奇妙之旅:SIMD加速矩阵运算
奇妙之旅:SIMD加速矩阵运算 1.前言2.预备知识3.计算逻辑4.代码实战 1.前言 游戏会涉及到大量4x4的矩阵乘法运算,而乘法最简单直观的实现就是循环4×4×4次乘法,以及若干次加法,得到结果。 在计算量较少时,cpu并不是很紧张。然而游戏通常每秒伴随着大量运算,此时,计算的效率就显得尤为重要。 通过查阅文献,我发现了一种SIMD(Single Instruct

【ARMv8/ARMv9 硬件加速系列 1 -- SVE | NEON | SIMD | VFP | MVE | MPE 基础介绍】
文章目录 ARM 扩展功能介绍VFP (Vector Floating Point)SIMD (Single Instruction, Multiple Data)NEONSVE (Scalable Vector Extension)SME (Scalable Matrix Extension)CME (Compute Matrix Engine)MVE (M-profile Vector

SIMD:单指令多数据
计算机图形学技术 见 计算机图形学技术 单指令流多数据流是一种采用一个控制器来控制多个处理器,同时对一组数据中的每一个分别执行相同的操作从而实现空间上的并行性的技术。 在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元。现代CPU中还有SIMD寄存器,用以支持向量操作:假如我们需要对一个向量进行倍乘,SIMD指令就可以将一个向量的几个数据全都读取到寄存器中进行计算,而不是每
SIMD学习笔记2:高斯卷积计算优化
https://github.com/gredx/simd-parallel-conv https://zhuanlan.zhihu.com/p/419806079 https://www.cnblogs.com/Imageshop/p/9069650.html https://zhuanlan.zhihu.com/p/308004749 https://zhuanlan.zhihu.com/p/

【整理】SIMD、MMX、SSE、AVX、3D Now!、neon——指令集大全
http://blog.csdn.net/conowen/article/details/7255920 SIMD SIMD单指令流多数据流(SingleInstruction Multiple Data,SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是
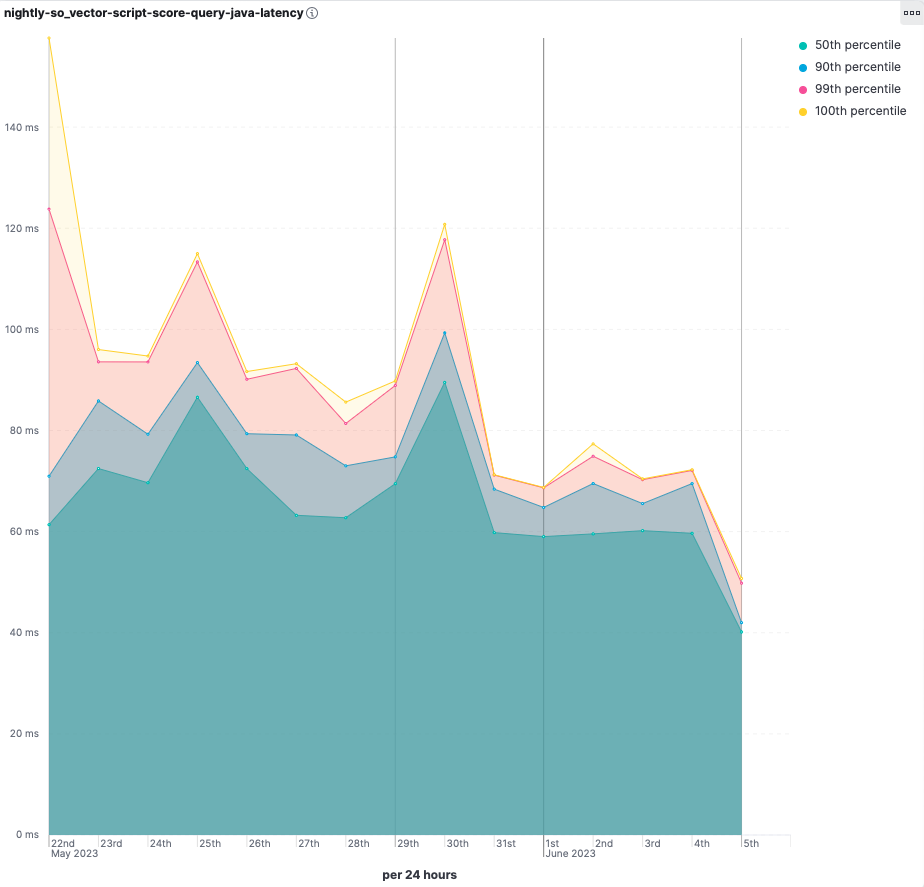
Elasticsearch:使用 SIMD 指令加速向量搜索
作者:Chris Hegarty, Elastic Principal Engineer, Lucene PMC 翻译:杰瑞朱 多年来,Java 平台上运行的代码一直受益于自动向量化 —— HotSpot C2 编译器中的 superword 优化,将多个标量操作打包到 SIMD(单指令多数据)向量指令中。这很好,但是这些类型的优化有些脆弱,具有天然的复杂性限制,并且受到 Java 平台规

听GPT 讲Rust源代码--library/portable-simd
File: rust/library/portable-simd/crates/core_simd/examples/spectral_norm.rs spectral_norm.rs是一个示例程序,它展示了如何使用Portable SIMD库中的SIMD(Single Instruction Multiple Data)功能来实现频谱规范化算法。该示例程序是Rust源代码中的一个文件,
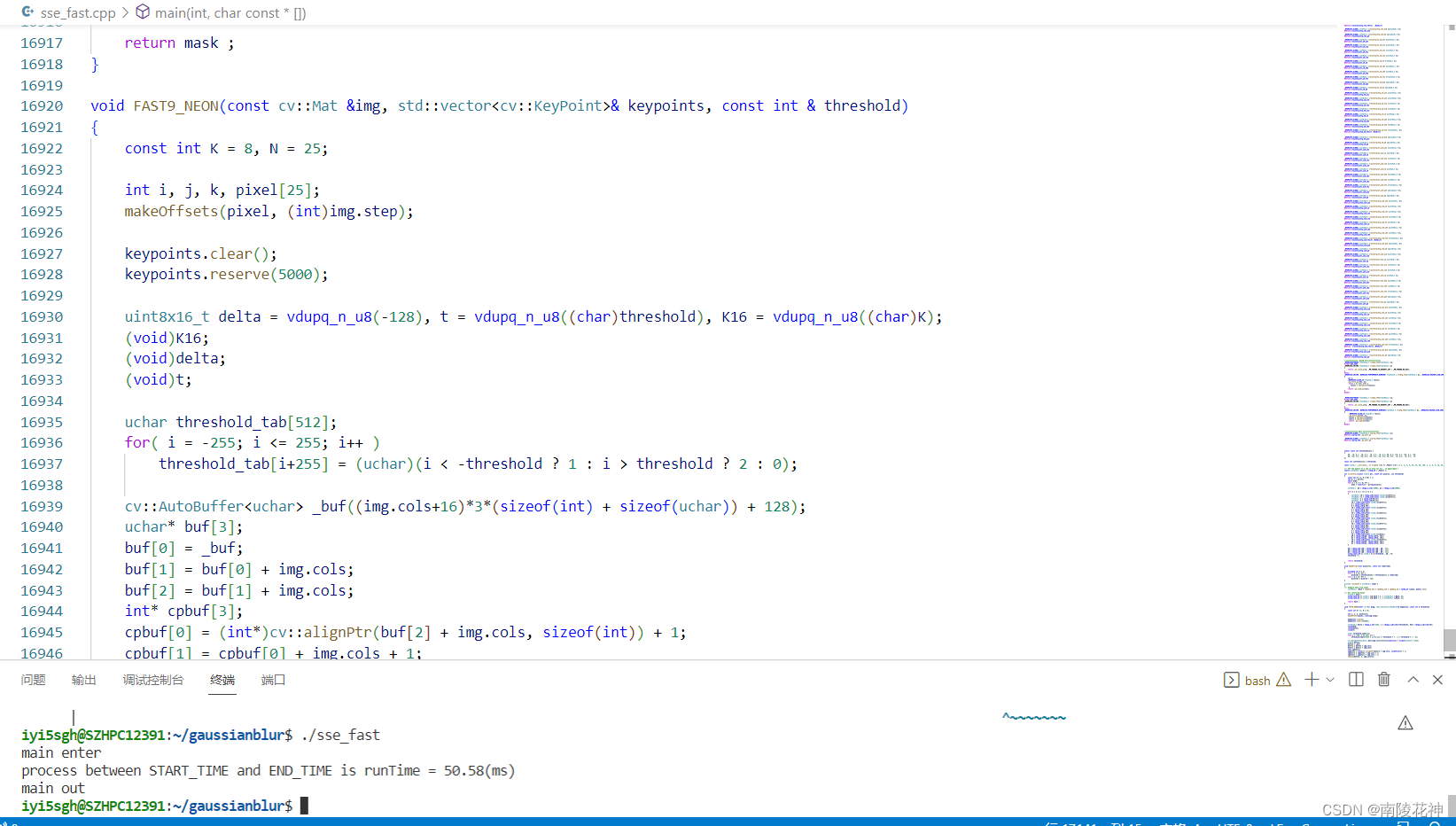
SIMD——请不要妄图优化opencv的函数
大纲 ORB-SLAM特征提取之SIMD优化一、优化手段1、NEON2、SSE 二、cv::gaussianblur函数优化三、cv::FAST函数优化四、原因分析 ORB-SLAM特征提取之SIMD优化 一、优化手段 1、NEON NEON是基于ARM架构的一种128位的SIMD(Single Instruction, Multiple Data,单指令、多数据)的拓展结
【整理】SIMD、MMX、SSE、AVX、3D Now!、neon
原文: http://blog.csdn.net/conowen/article/details/7255920 另外还有一个C++的参考:https://software.intel.com/zh-cn/articles/using-avx-without-writing-avx-code 解释得蛮清楚的。 SIMD SIMD单指令流多数据流(SingleInstruction

【ARMv8 SIMD和浮点指令编程】浮点加减乘除指令——四则运算
浮点指令有专门的加减乘除四则运算指令,比如 FADD、FSUB、FMUL、FDIV 等。 1 FADD (scalar) 浮点加法(标量)。该指令将两个源 SIMD&FP 寄存器的浮点值相加,并将结果写入目标 SIMD&FP 寄存器。 该指令可以产生浮点异常。根据 FPCR 中的设置,异常会导致在 FPSR 中设置标志,或者生成同步异常。 半精度 (ftype == 11)(FEAT_

【ARMv8 SIMD和浮点指令编程】NEON 存储指令——如何将数据从寄存器存储到内存?
和加载指令一样,NEON 有一系列的存储指令。比如 ST1、ST2、ST3、ST4。 1 ST1 (multiple structures) 从一个、两个、三个或四个寄存器存储多个单元素结构。该指令将元素从一个、两个、三个或四个 SIMD&FP 寄存器存储到内存,无需交错。每个寄存器的每个元素都被存储。 无偏移 一个寄存器 (opcode == 0111) ST1 { <Vt>.<T

【ARMv8 SIMD和浮点指令编程】NEON 通用数据处理指令——复制、反转、提取、转置...
NEON 通用数据处理指令包括以下指令(不限于): • DUP 将标量复制到向量的所有向量线。 • EXT 提取。 • REV16、REV32、REV64 反转向量中的元素。 • TBL、TBX 向量表查找。 • TRN 向量转置。 • UZP、ZIP 向量交叉存取和反向交叉存取。 1 DUP (element) 将向量元素复制为向量或标量。该指令将源 SIMD&FP

Rethinking SIMD Vectorization for In-Memory Databases 论文阅读笔记
Rethinking SIMD Vectorization for In-Memory Databases 论文阅读笔记 基本操作 selective store 将 vector lane 的一部分(根据 mask)写入连续内存 selective load 从连续内存读入到 vector lane 的一部分(根据 mask) selective gather 从非连续内存

并行笔记——SIMD编程
SIMD概念 Single Instruction Multiple Data 也就是单指令流和多数据流,对于多数据流进行相同的操作。 一个简单的例子就是向量的加减。 和MIMD的区别 SIMD拥有单个全局控制单元,而后者拥有多个控制单元+处理元素。 SIMD的应用 图像处理 音频 科学计算 基于数据的数据并行计算。 什么情况下适合应用SIMD 规律的数据访问模式:数据在内存中

Linux内核深入理解中断和异常(4):不可屏蔽中断NMI、浮点异常和SIMD
Linux内核深入理解中断和异常(4):不可屏蔽中断NMI、浮点异常和SIMD rtoax 2021年3月 本文介绍一下几种trap: //* External hardware asserts (外部设备断言)the non-maskable interrupt [pin] on the CPU.//* The processor receives a

SIMD 编程的优势与SIMD指令:SSE/AVX 与编程demo
资源:https://download.csdn.net/download/Rong_Toa/18745608 《Benefits of SIMD Programming | SIMD的优势》 目录 SIMD指令编程demo 正常代码 一次循环计算4次 使用SSE指令 使用AVX指令 性能对比 更多参考 SIMD指令编程demo 本文更新于 2018.10.24 本