本文主要是介绍07. BI - 量化交易,如何编写代码来利用 MACD 决定选股策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文为 「茶桁的 AI 秘籍 - BI 篇 第 07 篇」

文章目录
- MACD 指标
- 如何选股
Hi,你好。我是茶桁。
炒股票的同学应该知道指数吧?你们知道这个指数吗?MACD。
MACD 指标
我们看一下这个指数是什么。MACD 这个指数全称 Moving Average Convergence and Divergence。
它的原理是要计算两条线,一个叫 MA1,一个叫 MA2, 1 是短线,2 是长线。短线就是短期的平均值,比如说过去的 10 天。长线就是长期的平均值,比如说 20 天。这两条线之间也会有个差,这个差值称为 DIFF,这个差就可以知道现在是短期大,还是长期更高。DIFF 组成的线,我们称之为 MACD 线。
MACD 是一个重要特征,它可以帮你来去抉择进行买卖,选择一个适当的买入时刻和卖出的时刻,那这个买入和卖出的时刻我们就要找到一个比较可靠的一个特征。我们用的一个特征是通过 n 个周期的平滑值,n 个周期就是滑动窗口设为 n,它在滑动窗口里面的一个平均值。DIFF 的 n 周期的平滑移动平均线为 DEA。
那大家想想,为什么要用滑动窗口来去做一个平均值的计算?如果不用滑动窗口,我们就看过去一天会不会存在一些噪音的特征呢?有了滑动窗口,它的原理就是经过平滑可以过滤到一些异常的信号,尤其是那种突高突低的信号,这样得到的信号是相对有效的一个信号,这是好处。不好的地方就是滑动窗口毕竟是需要一定时间范围的窗口,所以有可能错失掉最好的买卖的时刻点。各有利弊,总体上来说还是更有价值来去做一个过滤的。
那怎么样去使用这个指标来判断什么时候买什么时候卖呢?
长期均线更能代表股票的实际价值,但是长期价值指的是什么价值呢?是长期的历史价值。我们所有的数据都是过去的历史,但是我们要决策的是未来,难点是未来是变化的,有的时候它存在不可测的因素。那么需要通过短线和长线帮你判断它的浮动情况。
股票是有惯性的,就像开车一样。如果是一个上升期,那它上升不是一两天的上升,可能是一个周期性的、阶段性的上升。下降也是一样,也是个阶段性的下降。
所以想要找到的是它在上升期的开始以及下降期的开始,决定你迈出的一个信号。这个信号可以把它用 DIFF 来去做个判断,向上突破就是短期抬头了,超过了长期均线就证明短期大盘在发力,大盘发力可以认为是一个好的买入信号。
差离值 DIFF 向上突破 MACD => 后市看好的买入信号
差离值 DIFF 向下突破 MACD => 后市看坏的卖出信号
差离值 DIFF 与 MACD 都呈现向上走势,而且有突破,是黄金交叉点 => 后市大好
差离值 DIFF 与 MACD 都呈现向下跌势,而且有跌破,是死亡交叉点 => 后市大坏
大体上可以这么去理解。
动量策略背后的逻辑就是认为我们的交易是有一个惯性,它不是立刻停止,所以你现在上升还会上升一个惯性周,下降也是一样。
MACD 指标:
- DIFF, DEA 和 MACD(即两条曲线 + 红绿柱)
- DIFF 即橙线,是对 K 线收盘价进行一系列计算的结果
- DEA 是蓝线,是在 DIFF 的基础上计算出来的
- MACD 柱 = (橙线 - 蓝线)* 2 = (快线 DIFF - DIFF 的 9 日加权移动均线 DEA) * 2
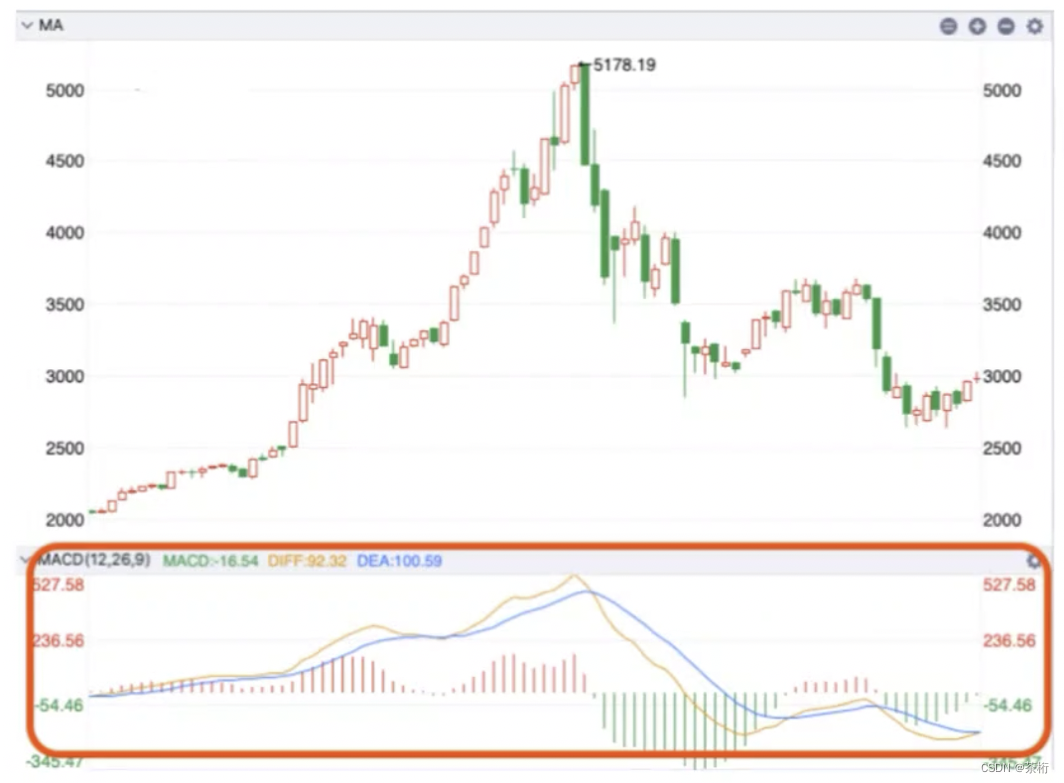
如上图,可以把 MACD 理解成移动平均线,这移动平均线是由两条线组成的,快和慢。快就是短期,慢就是长周期。
以这样一个数据为例,快线是我们的橙线,蓝线应该会更慢。当它们某一个时刻点如果快线向上走势刚刚超过了慢线,则要进行买入。刚刚超过的过程中它是有一个惯性的,它超过去会有个周期,所以它应该是买。
但是超过不会一直超过,他超过以后蓝线也会逐渐的上升,但是上拉的力量已经开始疲软了,到某一个会客点的时候,当橙线和蓝线又给它交合的时候,这个时刻是该买还是该卖呢?
我们在再一次发生交集的时候应该应该卖掉,为什么,大盘疲软了。不过大盘疲软以后马上要开始上升了,其实你没卖多久,后面又上去了,上去以后还要购买,这是按照 MACD 的一个指标来去给你的提示。
我们再来看这张图,标示一下买卖点:
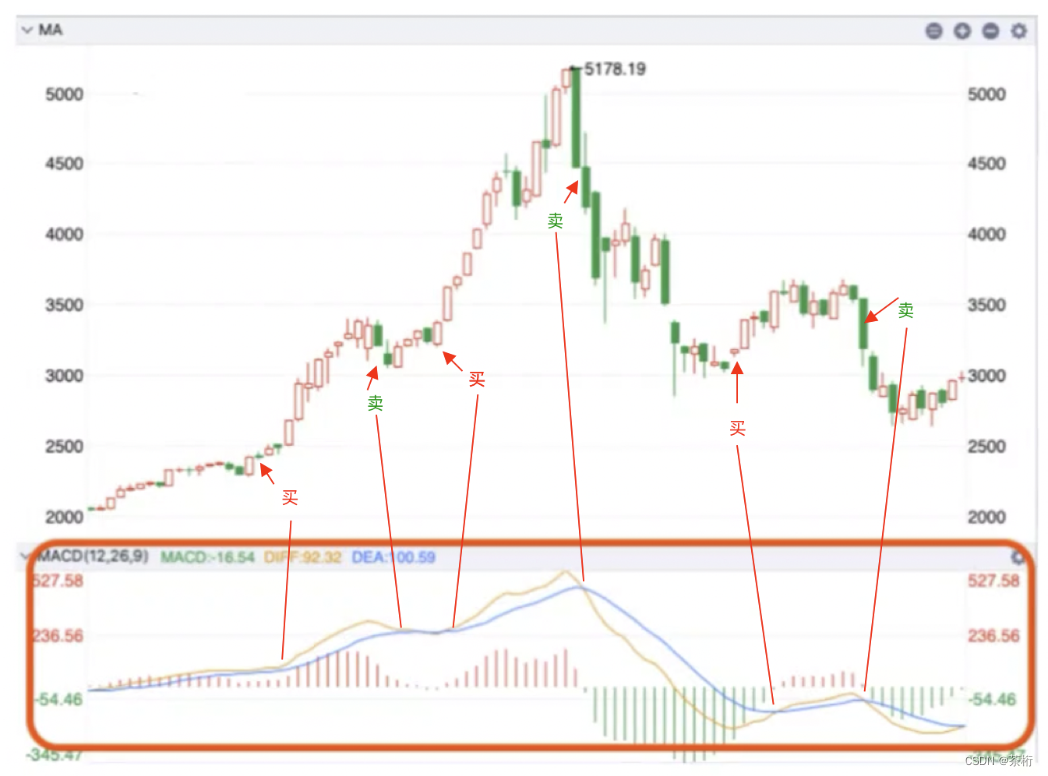
大体上对应一下,应该是如图这样。如果是这样的一个买卖信息,通过 MACD 线来做决策,在上面写的这个买卖的时刻点。现在我们想想,这样的交易策略是好还是坏呢?这样的一个标记策略能不能挣到钱?
从这个数据集上面来去看是好的,而在很多的其他情况下其实也是好的。但是也有些情况下可能是坏的,所以刚才这个策略不能说是完全 100%的一劳永逸。在某些情况下,它确实是可以帮你挣到钱。
我们来看,这个交易是从 2,000 多点一直到大盘 5,000 多点又下来。这个交易不能说多频繁,应该是属于一个长周期的交易,它有可能横跨了一两年之后。但是它是滞后的,MACD 是个移动平均线,看到平均,看到滑动窗口就会想到它的特征,计算没有那么的及时,因为毕竟需要一个时间段来去验证。可能需要有一个 10 天的周期,所以它是滞后的。因此就算挣钱也不会有多极致,但是总的来说还是不错的。
MACD 就告诉你在正确的时间做正确的事,这就是一个统计特征。具体在程序上面在这个策略上面怎么做呢?MACD 是要有一个快和慢的定义,快线现在是可以用 12 天,慢线用的是 26 天。为什么是 12 和 26,因为在早些年间我们那阵工作时间还是一周六天,所以当时的股票交易就是一周六天,那么半个月就是 12 天。半个月你就认为是一个快线特征,那一个月有可能就是 26 天。
当然现在工作日已经不是一周六天而是一周五天。(我知道你们想说什么,不用吐槽,以法定工作日为准,毕竟股市是严格按照法定日来的。)所以在实际的股票交易日里面如果你还是半个月和一个月,它应该已经变成 10 和 21。用哪一种方式都行,可以用 12 和 26,也可以用 10 和 21。
为什么有些人现在还用 12 和 26 来做快线和慢线的一个准则呢?原因就是因为我们已经形成了共识,已经把它当成快慢的一个标准。所以大家都会看这个特征,当看到这个特征的人数多了我们就会认为它是个重要的一个指标。当然你也可以采用 10 和 21 这个数值。
简单总结一下,DIFF 是这两个线的差值,当 DIFF 上穿 0 轴时,差值抬头了,就证明短线在开始突破,即 12 日均线与 26 日均线金叉。当 DIFF 下穿 0 轴时,已经开始疲软了,逐渐的弱下于整个长期的趋势了,即 12 日均线与 26 日均线死叉,死叉就是个卖的信号。
那么怎么去指导买卖呢?金叉、死叉其实就是一个很好的买卖信号,但这个信号是有前提的,它是在趋势行情,也就是动量行情。就说趋势是应该有一个惯性的,如果它是在震荡,震荡是随机的,它没有趋势,所以它的惯性特征没有这么明显。没有这么明显的过程中,金叉和死叉就有可能不是个有效的信号。
以上是在趋势行情里面来去做的,周期内的一个情况。
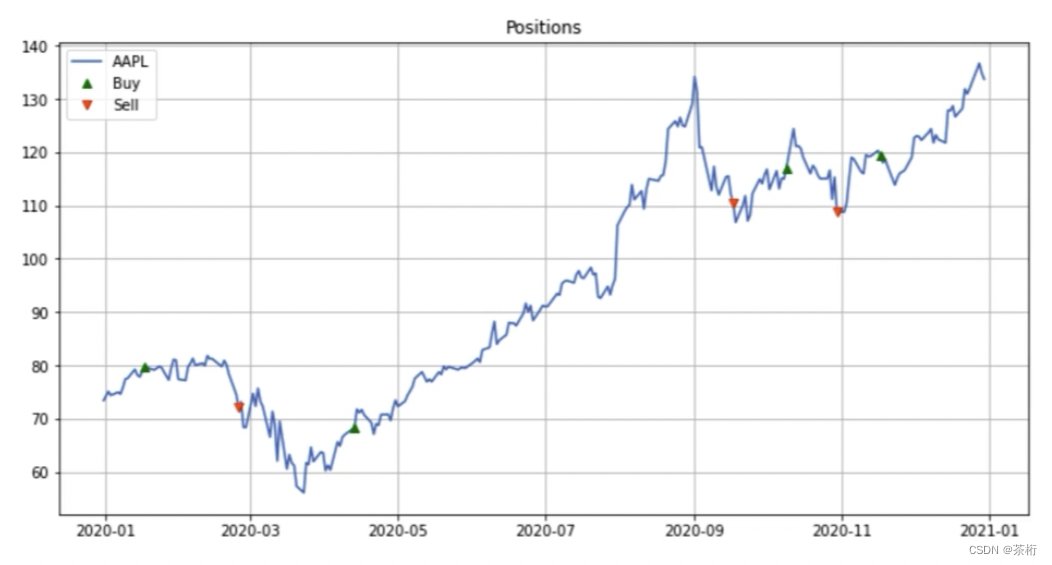
操作的过程我们可以看一看,可以对未来股票计算一下它的短期均线 MA1 和长期的均线 MA2,我们拿 AAPL 来举例,计算它的买卖时刻和信号,在股市中绘制买入和卖出的信号,包括 DIFF,MA1 和 MA2 曲线。
这就是教给大家一个工具怎么样去计算它的短期和长期的特征,基于它的这个特征来去决定你买入和卖出的一个时刻点,把这个时刻点绘制出来。你可以看有的时候也没这么好,比如图中绘制的这个买卖点也会造成一个亏损,比如第一个买点和第二个卖点之间,就是一个亏损的状态。整体上来说有赔有赚,总的来说挣的概率会更大一些。
那接下来,我们用 MACD 策略看一波代码。
首先,我们是要先实现咱们的 MACD 策略:
# 计算 df 的短期平均 ma1, 长期平均 ma2
def macd(df):
df['ma1'] = df['Close'].rolling(window=ma1, min_periods=1).mean()
df['ma2'] = df['Close'].rolling(window=ma2, min_periods=1).mean()df['diff'] = df['ma1'] - df['ma2']
df['dea'] = df['diff'].rolling(window=9, min_periods=1).mean()
return df
可以看到,滑动窗口用的 rolling 函数。滑动窗口就是计算它的快线和慢线,MA1 就是 12 天,MA2 是 26 天。用滑动窗口求 diff,diff 代表的含义是快线减慢线,看一看现在是在上面还是在下面。然后把 diff 求了一次均值。快线和慢线已经做过一次求均值,如果又做一次均值的应该是两次平滑,如果用两次平滑拿它做指标会过滤异常值,效果更好,就不容易出现那种噪音的浮动,因为我们用了两次以上值的过滤。你可以采用一次平滑,也可以采用两次平滑。一次平滑看的是 diff,两次平滑是看的 diff 处的滑动窗口的平均值,拿它来去做判断。
然后咱们来计算买卖时刻点的信号
def signal_compute(df):
df = macd(df)
df['positions'] = 0df['positions'][ma1:] = np.where(df['ma1'][ma1:] >= df['ma2'][ma1:],1,0)df['signals'] = df['positions'].diff()df['diff'] = df['ma1'] - df['ma2']
df['macd'] = 2 * (df['diff'] - df['dea'])return df
我们现在做的应该是一次平滑的信号, 就是说看它快线和慢线是不是大,如果大我们就认为现在应该持有,那我们就会把它的 positions 写成 1。
np.where是个条件判断, 如果它存在我们就写为 1, 如果它不存在写为 0.
所以上面这个代码可以看到,短线抬头的时候你要持仓,那这个持仓是你当下的一个状态。什么时候做这个状态呢?我们还要看一看它先后的一个变化,如果之前是不持仓,position 等于 0,突然某一个时刻发生突变的过程中 position 从 0 到 1,这个时刻点是给你一个信号,从没有这只股票到拥有这只股票我要做的是个信号的处理,它应该就是个买的信号。
如果它的 position 一直都是 1,突然有一天它的 position 变成了 0,我们把它的这个 diff 求解出来应该变成了卖的信号。
所以怎么去筛出来这个买和卖呢?筛的过程实际上是求了一个diff(), 这个方法在 Pandas 里面代表前后相减,可以把买卖信号计算出来。
信号 position 无外乎就是 0 和 1 的关系,所以这两个趋势都可以计算出来了。
那其中一些 Python 的基础语法,大家应该在之前就应该掌握了。比如df[ma1], 这就是在 df 数据内去筛选快线特征,在快线特征里面筛的不是它的全量值,筛的是什么?[ma1:]代表的就是 12 天以后的。因为在 12 天之前我们还没有这个特征,在股票刚刚上线前,12 天之前其实是没有快线特征的,所以我们把它过滤掉了。不把它过滤掉,把它就写[ma1]其实理论上也是 OK 的。因为这两个为NaN, 其实是没有什么意义的一个特征。
总的来说,可以把它理解成就是 MA1 大于 MA2,就是快线和慢线的一个对比的情况。把这个对比情况喂给position,就可以知道要持仓还是不持仓。
signal 计算完成以后我们可以在图里面把 signal 给它绘制出来。
# 绘制回测结果
def plot(df, ticker):
# 绘制实际的股票收盘数据
fig = plt.figure(figsize=(12, 6))
ax = fig.add_subplot(111)
ax.plot(df.index, df['Close'], label=ticker)# 只显示时刻点,不显示折线图 => 设置 linewidth=0
ax.plot(df.loc[df['signals']==1].index, df['Close'][df['signals']==1], label='Buy', linewidth=0, marker='^', c='g')
ax.plot(df.loc[df['signals']==-1].index, df['Close'][df['signals']==-1], label='Sell', linewidth=0, marker='v', c='r')plt.legend(loc='best')
plt.grid(True)
plt.title('Positions')
plt.show()# 显示 diff,即 ma1-ma2
fig = plt.figure(figsize=(12, 6))
cx = fig.add_subplot(211)
df['diff'].plot(kind='bar', color='r')plt.legend(loc='best')
plt.grid(True)
plt.xticks([]) # 不显示 x 轴刻度# 绘制 ma1, ma2 曲线
bx = fig.add_subplot(212)
bx.plot(df.index, df['ma1'], label='ma1', color='orange')
bx.plot(df.index, df['ma2'], label='ma2', linestyle=':', color='blue')plt.legend(loc='best')
plt.grid(True)
plt.show()
signal 等于 1 就是需要进行持有,在上面写成一个 buy,建议你去购买。颜色用 green 绿色,signal 等于-1 就是不建议持有,写成了 sell,颜色呢写成了 r,就是红色。一会儿可以用这个函数打印出来。
具体在设置参数的时候设了 12 天和 26 天:
ma1 = 12
ma2 = 26slicer = 0data = yf.download(tickers='AAPL', start='2021-01-01', end='2021-12-31')
data.to_csv('dataset/AAPL_2021_MACD.csv')
# data
股票我们选用的是 AAPL,就是 apple 的股票。买卖时刻点可以分别帮你来计算出来,
print('买入信号:', df.loc[df['signals']==1].index)
# print('买入信号时的收盘价:',df['Close'][df['signals']==1])
print('卖出信号:', df.loc[df['signals']==-1].index)
# print('卖出信号时的收盘价:', df['Close'][df['signals']==-1])---
买入信号: DatetimeIndex(['2021-01-21', '2021-04-07', '2021-06-15', '2021-10-21'], dtype='datetime64[ns]', name='Date', freq=None)
卖出信号: DatetimeIndex(['2021-02-19', '2021-05-10', '2021-09-21'], dtype='datetime64[ns]', name='Date', freq=None)
告诉你说 1 月 21 号买, 4 月 7 号买,6 月 15 号,10 月 21 号买。这个买卖时间是交错的,买不会一直买,掉下来了,疲软的时候交叉的部分其实就是卖。所以可以把它理解成是 1 月 21 号买,2 月 19 号就卖了。之后 4 月 7 号买,5 月 10 号再卖掉…
来,我们将数据绘制出来:
plot(df, 'AAPL')
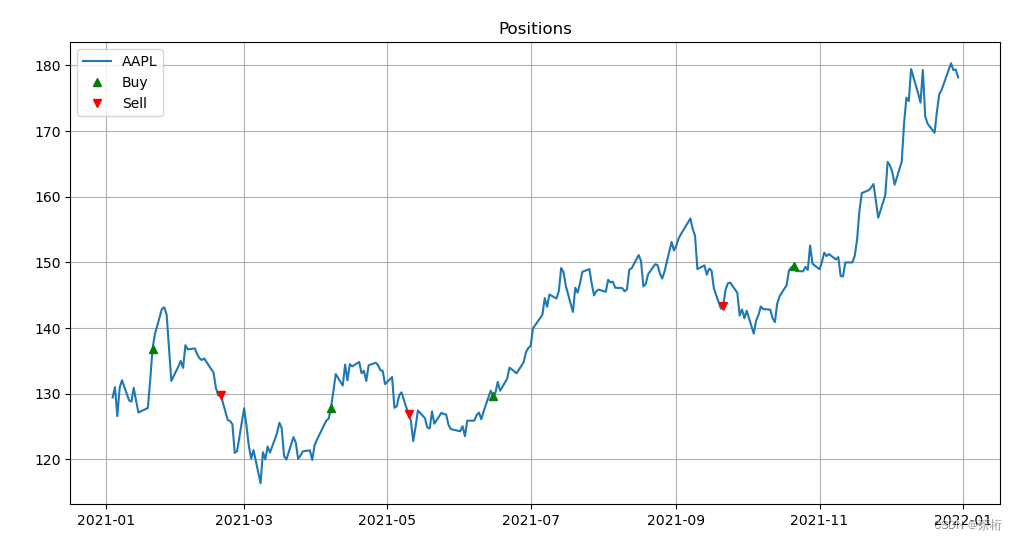
做的这个策略是历史复盘的一个情况,这是它的整个历史的一个数据,能看到他的复盘情况。
我们制定一个策略是想看它在过去一段时间的表现怎么样,如果它在过去一段时间表现好,那么你在未来时刻可以采用这个策略来去做一个实战。不过大家可以思考一下,过去表现好一定代表未来好吗?不一定,有可能会差。但是总的来说它还是过去一段时间一个好的验证。对于之前的这个时刻我们应该是在某一个时刻点到另一个时刻点,它的一段距离的情况就是 MA。而且 MA 是过去 12 天和 26 天。
我们现在就把它画出来了,下图就是它的 ma1 和 ma2,还有 diff 的图:
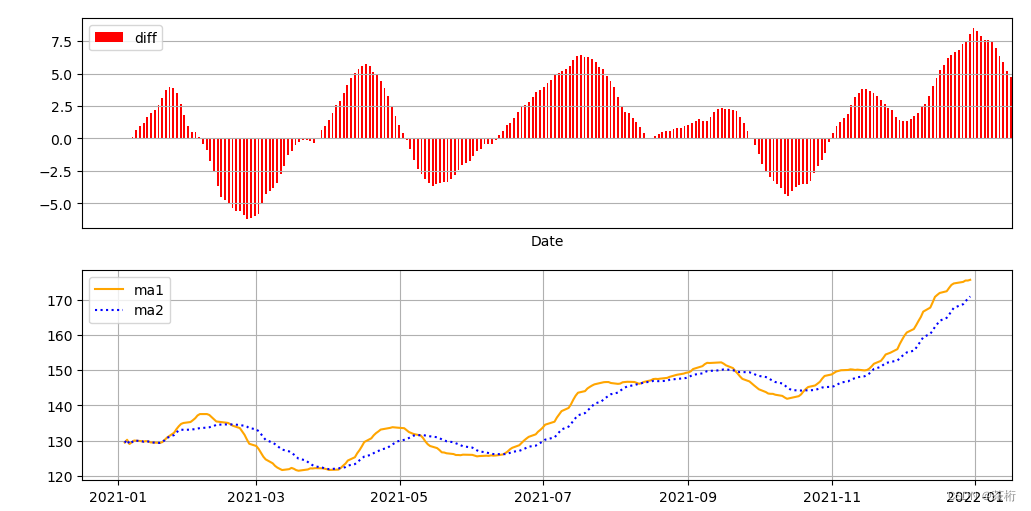
这个曲线可以看到,橙色是快线,它的运动的幅度会更大一点。以靠近 2021-07 在它之前的那个交叉点为例,橙色快线上升的时候这个点应该是买还是卖?这个点蓝色现在已经开始往上升了,所以理论上应该是要买会更好。然后一直都是可以买的,因为它都属于上升的波段。
在 2021-09 之后的第一个交叉点是不就卖掉了?卖掉以后再择时,择到下一个时刻再买。
所以在更上面那张图中,我们把它的买卖时刻标注了出来。
告诉你说 1 月 21 号买, 4 月 7 号买,6 月 15 号,10 月 21 号买。这个买卖时间是交错的,买不会一直买,掉下来了,疲软的时候交叉的部分其实就是卖。所以可以把它理解成是 1 月 21 号买,2 月 19 号就卖了。之后 4 月 7 号买,5 月 10 号再卖掉…
可以看到是 1 月 21 买了,2 月 19 号就卖了。4 月 7 号买了,持有了大概 1 个多月,然后就卖掉了。这张图就是 MACD 的一个买卖信号。
从这张图里面其实也能判断出来,整体上来说还是有亏钱的可能。比如第一个买点和第一个卖点之间,我们可以看到它就亏钱了,第一个小周期是赔钱了。1 月 21 号到 2 月 25 号之间是赔钱了。但是第三个买卖周期算是大赚了一笔,之后再买入并持有,一直是赚的。有赚有赔,总来说赚的可能性会略高一点。
我们来验证一下咱们的周期看看,用上节课中咱们对股票进行操作的函数来进行:
# 假设初始资金 10000
portfolio = dict()
portfolio['cash'] = 10000# 计算能买多少股
valid_num = int(portfolio['cash'] / df.iloc[0]['Open'])
valid_num---
74
设置完初始资金并计算我们可以买入的数量之后,我们就来操作下看看,先看第一个周期:
portfolio_buy(portfolio, '2021-01-21', 'AAPL', 70)
portfolio_sell(portfolio, '2021-02-19', 'AAPL', 70)---
{'cash': 9724.899444580078, 'AAPL': 0}
果然是如我们预期的一样,第一个小周期内是亏钱的对吧?那我们来看看所有周期结束后,如果在年底卖出会怎么样。
# 买卖股票
portfolio_buy(portfolio, '2021-01-21', 'AAPL', 70)
portfolio_sell(portfolio, '2021-02-19', 'AAPL', 70)
portfolio_buy(portfolio, '2021-04-07', 'AAPL', 70)
portfolio_sell(portfolio, '2021-05-10', 'AAPL', 70)
portfolio_buy(portfolio, '2021-06-15', 'AAPL', 70)
portfolio_sell(portfolio, '2021-09-21', 'AAPL', 70)
portfolio_buy(portfolio, '2021-10-21', 'AAPL', 70)
portfolio_sell(portfolio, '2021-12-30', 'AAPL', 70)---
{'cash': 12797.898483276367, 'AAPL': 0}
当然我们为了简便,现在是手动的根据之前分析的买卖点来执行买卖操作,并没有完全用程序自动执行。不过我们可以看到,整体收益率是达到了近百分之二十八。这个是很棒的一个收益了对吧?
以上就是 MACD 的一个策略, 我简单给大家梳理一下。然后整个代码在我仓库里也有,大家可以自己去获取,你们可以做一个参考。
其实选股是非常重要一件事,买什么这第一个维度,第二个怎么买。怎么买又分了每一只股票的一个配额, 如果我们最初 1W 的资金,买 10 支股票,那么平均配额,每支股票分到 1000 块钱。
第三就是制定交易策略,交易策略是刚才介绍给大家的 MACD,MACD 算是指标之王,在炒股里面这个指标是使用频率最高的,也是所有人基本上必研究的一个指标。
我们可以通过 MACD 给你一些信号一个策略展示,就按照刚才这段代码,大家可以自己来去模拟一下。
择股优于择时,择股是你的格局。你去选了一个大的格局,后面是属于在格局里面的一个努力。你选了一个很好的赛道,这个赛道有一个很好的一个空间,所以你要选择一个好的股票有的时候才是第一个要位。
好的股票怎么选呢?用我们之前介绍的 jqdata 就可以, 那我们都知道,要选股首先是要先观察行业,我们看好一个行业之后再从中进行选择。那么就先将所有行业查询出来:
benchmark_date = '2023-08-25'
temp = jq.get_industries(date=benchmark_date)
选择这个日期也是因为我的这个账户并没有缴费,所以免费版的限制是到这一天为止。
好,那从这些查找出来的行业中,我们看看和计算机相关的产业都有哪些:
temp[temp['name'].str.contains('计算机')]
接着,我们获取一下这个行业版块内所有的股票:
pool = jq.get_industry_stocks('C39', date=benchmark_date)
pool---
['000016.XSHE',
...
'689009.XSHG']
这样就可以将这个版块内所有的股票代码获取到。
接着,我们就可以根据获取到的代码,来查看市盈率大于 0,那范围当然就是我们之前获取的,属于计算机行业这个版块的所有股票,然后我们让它们的 PE 从小到大进行一个排序:
q = jq.query(jq.valuation.code, jq.valuation.pe_ratio, jq.valuation.market_cap).filter(jq.valuation.pe_ratio > 0, jq.valuation.code.in_(pool)).order_by(jq.valuation.pe_ratio.asc())
df = jq.get_fundamentals(q, date=benchmark_date)
df---code pe_ratio market_cap
0 300390.XSHE 3.7676 224.1249
... ... ... ...
449 002161.XSHE 8955.4187 37.3577
当然我们想要查询一下我们获取的这么多股票的 PE 和 MC 均值大概为多少,这也可以大概了解一下这个版块的发展到底如何:
pe_mean = float(df['pe_ratio'].mean())
mc_mean = float(df['market_cap'].mean())
print('满足条件的股票: {}'.format(len(df)))
print('平均 PE: {}, 平均 MC: {}'.format(pe_mean, mc_mean))---
满足条件的股票: 450
平均 PE: 102.55968466666666, 平均 MC: 156.16871555555554
接着,我们来筛选我们想要投资的股票,那这个就是一个策略问题,在这里,我想要看看小于 PE 均值,且 PE 要大于 0, 然后大于 MC 均值的所有股票,再进行排序:
q = jq.query(jq.valuation.code, jq.valuation.pe_ratio).filter(jq.valuation.pe_ratio<pe_mean, jq.valuation.market_cap>mc_mean, jq.valuation.pe_ratio>0, jq.valuation.code.in_(pool)).order_by(jq.valuation.pe_ratio.asc())# 对于筛选出来的股票,查询 benchmark_date 的数据
df = jq.get_fundamentals(q, benchmark_date)
df---
code pe_ratio
0 300390.XSHE 3.7676
... ... ...
83 002436.XSHE 100.6802
那我们这样呢,还是获取了 84 支股票,似乎还是有点多是把?这里呢,就是教大家这么个意思,具体的选股策略,最终选取出自己心仪的那几支,大家还是需要去学习一下基础的股票知识。
好,那最后,我们将这 84 支股票打印出来,看看都有哪些:
print(df['code'].values)---
['300390.XSHE' ... '002436.XSHE']
如果我们想要进行一个长期的数据对比,也可以选中一个自己看重的指标,然后将其全部 down 下来进行观察,这里,我选中的指标还是 PE 值:
# 从 2023-1-1 到 2023-08-25 这些股票的数据
start_date = datetime(2023,1,1)
end_date = datetime(2023,8,25)# 获取制定的交易日范围
all_trade_days = jq.get_trade_days(start_date=start_date, end_date=end_date)for i in all_trade_days:
# 设置第 i 天的 PE 数据
df[i] = jq.get_fundamentals(q, i)['pe_ratio']
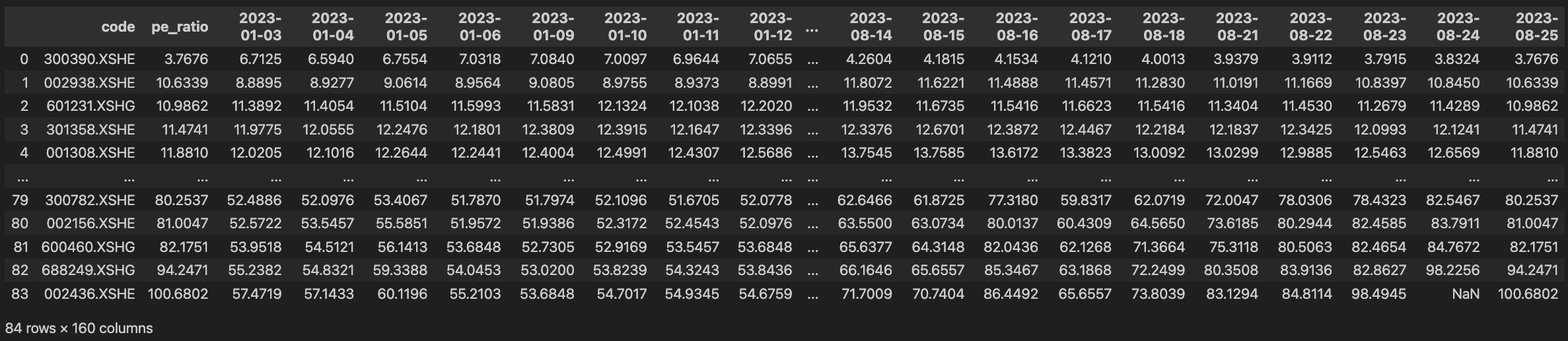
数据的 columns 就是日期,太多了我就不完全展示了。大家可以在本文之后自己操作一下看看。
在整个代码操作过程中,我保存了几个数据在 dataset 里,大家可以去我的代码仓库里直接拿来用,使用 read_csv 就可以,这样就不需要去从新去查询和获取数据了。
这篇关于07. BI - 量化交易,如何编写代码来利用 MACD 决定选股策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




