本文主要是介绍Python 数据分析实战——为什么销售额减少?酒卷隆治_案例1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# 为什么黑猫游戏的销售额会减少?

# 数据集
DAU : 每天至少来访问一次的用户数据
数据内容 数据类型 字段名
访问时间 string(字符串) log_data
应用名称 string(字符串) app_name
用户 ID int(数值) user_id
DPU: 每天至少消费1日元的用户数据
数据内容 数据类型 字段名
消费日期 string(字符串) log_data
应用名称 string(字符串) app_name
用户 ID int(数值) user_id
消费额 int(数值) Payment
INSTALL : 每个用户首次玩这个游戏的时间数据
数据内容 数据类型 字段名
首次使用的日期 string(字符串)
# 加载模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt # 导入数据
DAU = pd.read_csv("D:/data/datasource/数据分析实战_酒卷隆治/R/section3-dau.csv")
DPU = pd.read_csv("D:/data/datasource/数据分析实战_酒卷隆治/R/section3-dpu.csv")
INSTALL = pd.read_csv("D:/data/datasource/数据分析实战_酒卷隆治/R/section3-install.csv")# 将数据合并起来
data = DAU.merge(INSTALL,on='user_id')
data = pd.merge(data,DPU, on =['user_id','log_date'], how ='outer') # outer 外连接,保留两个数据集中所有的user_id, log_date
# 对数据进行处理
data.fillna(value=0, inplace =True)
# 剔除多余的列
data.drop(columns=['app_name_y','app_name'])
# 生成新的列,年月份数据
data['log_mon'] = data.log_date.apply(lambda x: pd.to_datetime(x).strftime('%Y-%m'))
data['install_mon'] = data.install_date.apply(lambda x: pd.to_datetime(x).strftime('%Y-%m'))
# 按月聚合统计每位人员的销售额
data_mon = data.groupby(['log_mon','user_id','install_mon']).payment.sum().reset_index()# 如果log_date 等于 install_date 则为新用户
data_mon['type'] = data_mon.apply(lambda x: '1' if x.log_mon == x.install_mon else '0', axis =1)
# 按月统计新老客户的销售额
data1 = data_mon.groupby(['log_mon','type'])['payment'].sum().reset_index(name='tot_payment')
data_pivot = pd.pivot_table(data1,values='tot_payment',index='log_mon',columns='type',aggfunc='sum').reset_index().rename(columns={'0':'老用户','1':'新用户'})
# data_pivot.index=('老用户','新用户')
data_pivot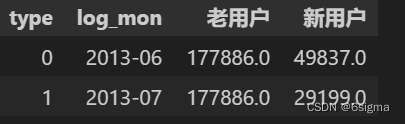
# 堆积柱形图: 不同月份新老客户的销售额bar1 = plt.bar(np.arange(2),data_pivot.老用户,color='green',label='老用户',width=0.2,alpha=0.5)
bar2 = plt.bar(np.arange(2),data_pivot.新用户,color='grey',label='新用户',bottom=data_pivot.老用户,width=0.2,alpha=0.5)plt.bar_label(bar1,color='black')
plt.bar_label(bar2,color='black')# # 设置x轴标签
plt.rcParams['font.sans-serif']=['SimHei'] # 用来显示中文
plt.title('黑猫游戏新老客户销售额',fontsize=18)
plt.xticks(np.arange(2),data_pivot.log_mon)
plt.xlabel('月份',fontsize=12)
plt.ylabel('月销售额(日元)',fontsize=12)
plt.ylim(0,300000) # 修改刻度
plt.legend(loc='upper right',ncol=1)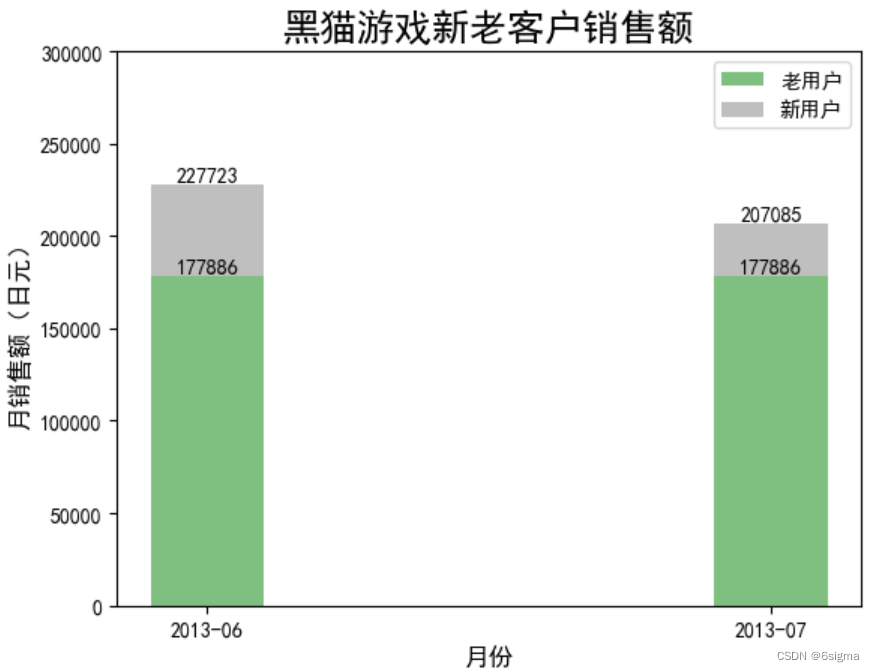
# Note: 根据上图可知销售额的下降主要是优于新用户导致。
# 筛选新用户 且消费大于0的用户 的销售数据,对消费金额进行分组,统计不同组内的用户数
data_new = data_mon[(data_mon.type=='1')&(data_mon.payment>0)]
# 对数据进行分组
payment_min = data_new.payment.min()
payment_max = data_new.payment.max()print(payment_min, payment_max,data_new.user_id.count())
data_new['payment_group'] =pd.cut(data_new.payment,bins=[payment_min-1,1000,2000,3000,4000,5000,6000,7000,payment_max+1],labels=['1000日元一下','1000-2000','2000-3000','3000-4000','4000-5000','5000-6000','6000-7000','7000日元以上']) data_new_group = pd.pivot_table(data_new,values='user_id',index='payment_group',columns='log_mon',aggfunc='count').reset_index().rename(columns={'2013-06':'六月份','2013-07':'七月份'})
data_new_group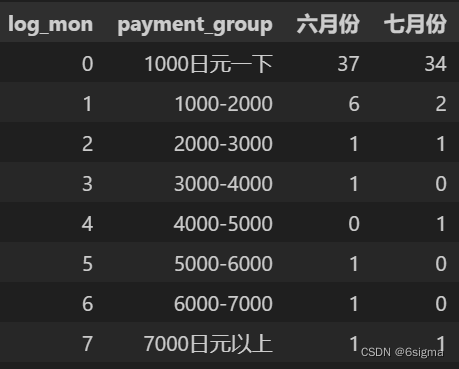
# 可视化
fig = plt.figure(figsize=(10,4))
bar1 = plt.bar(np.arange(8), height=data_new_group.六月份, color='blue', width=0.3,alpha = 0.5,label='2013年6月') # alpha 设置透明度
bar2 = plt.bar(np.arange(8)+0.3,height = data_new_group.七月份, color='green',width=0.3,alpha = 0.5,label='2013年7月')plt.legend()# 添加数据标注,
plt.bar_label(bar1)
plt.bar_label(bar2)# # 设置x轴标签
plt.rcParams['font.sans-serif']=['SimHei'] # 用来显示中文
plt.title('黑猫游戏新老客户销售额度比较',fontsize=18)
plt.xticks(np.arange(8)+0.2,data_new_group.payment_group)
plt.ylabel('消费人数(人)',fontsize=12)
plt.ylim(0,40) # 修改刻度
plt.legend(loc='upper right',ncol=1)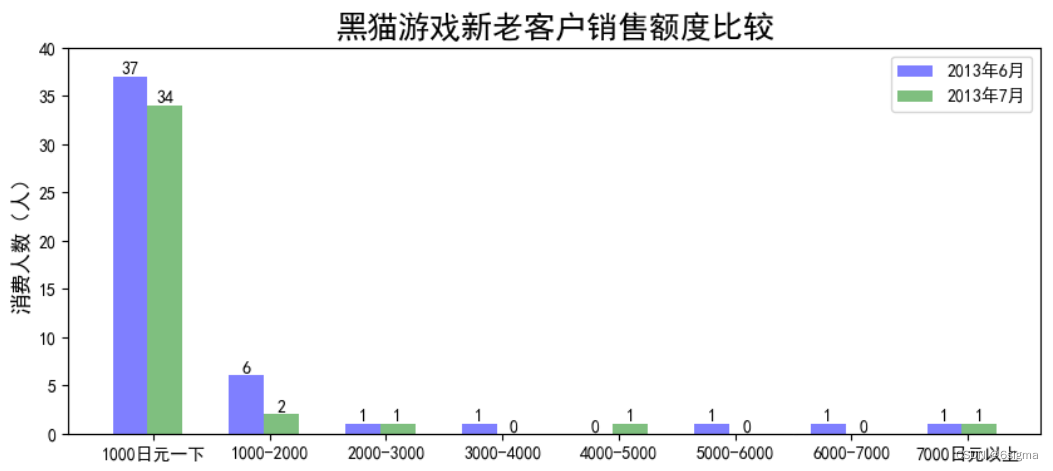
Note: 由图可知,本月消费2000以下的用户数量减少了。 (根据书本的样例数据计算的结果,并不能反应出销售额的下降是由于消费2000元以下的用户数减少,暂且认为是确实部分数据)
解决对策: 根据之间的假设 宣传活动减少,导致新客户数量减少,新客户带来了销售额的下降,建议恢复商业宣传活动到之前的水平。
Note: 在实际的工作中,还需要判断ROI,比较新用户的顾客终身价值和商业宣传活动的投入成本,再进行决策。
这篇关于Python 数据分析实战——为什么销售额减少?酒卷隆治_案例1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




