本文主要是介绍Emergent Abilities of Large Language Models 机翻mark,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
证明通过扩大语言模型可以可靠地提高性能和样本效率在广泛的下游任务。相反,本文讨论了我们称之为大型语言模型的新兴能力的一种不可预测的现象。我们认为如果一个能力不存在于较小的模型中,但在较大的模型中存在,则该能力就是新兴的。因此,仅仅通过外推小模型的性能无法预测新兴的能力。这种涌现的存在提出了一个问题:是否有可能进一步扩展语言模型的能力范围。
1. 简介
近年来,语言模型已经彻底改变了自然语言处理(NLP)。现在人们普遍认为,增加语言模型的规模(例如训练计算、模型参数等)可以提高下游各种NLP任务的性能和样本效率(Devlin等人,2019;Brown等人,2020年等)。在许多情况下,规模对性能的影响往往可以通过缩放定律来方法上预测——例如,交叉熵损失的缩放曲线已被证明可以在经验上跨越超过七个数量级(Kaplan等人,2020;Hoffmann等人,2022)。另一方面,某些下游任务的性能似乎并不随着规模的增大而持续提高,并且这些任务不能提前预测(Ganguli等人,2022)。
在本文中,我们将讨论大型语言模型涌现能力的不可预测现象。作为概念,涌现长期以来一直在物理学、生物学和计算机科学等学科领域进行讨论(安德森,1972;黄等人,2012;Forrest,1990;Corradini& O’Connor,2010;Harper& Lewis,2012,inter)
我们考虑以下从 Steinhardt (2022) 汲取并植根于诺贝尔奖得主菲利普·安德森 (Philip Anderson) 的论文“更多意味着不同”(1972) 中的一般涌现定义[5]:
在这里,我们将根据训练计算能力和模型参数数量来探索规模与涌现的关系。具体来说,我们定义大型语言模型的涌现能力为在小规模模型中不存在但在大规模模型中存在的能力;因此,不能仅通过预测小规模模型性能改进来简单地预测这些能力(第 2 节)。1 我们调查了各种先前工作的涌现能力,并将其分类到诸如少量提示(第 3 节)和增强提示策略(第 4 节)等设置中。涌现力激励未来的研究,以了解为何会出现此类能力,以及是否会导致进一步的能力涌现,我们认为这是该领域的重要问题(第 5 节)。
2. 紧急能力定义
作为广义的概念,涌现经常被非正式地使用,并且可以用许多不同的方式合理解释。在本文中,我们将考虑大型语言模型涌现能力的一个集中定义:
如果能力在较小模型中不存在,但在较大模型中存在,则该能力就是涌现出来的。
从微观模型中推断出一个缩放法则(即一致性能提升)并不能直接预测涌现能力。通过缩放曲线(横轴:模型规模,纵轴:性能)可视化后,涌现能力显示出一种明显模式——在达到某一临界尺度之前,性能接近随机;达到该尺度后,性能显著地超过随机水平。这种定性的改变也被称为相变——通过观察较小尺度的系统无法预见的整体行为的剧烈变化(Huberman & Hogg, 1987)。
今天,语言模型主要沿着三个因素进行扩展:计算量、模型参数数量和训练数据集大小(Kaplan等人,2020;Hoffmann等人,2022)。在这篇论文中,我们将通过绘制不同模型的性能来分析缩放曲线(霍夫曼等,2022)。由于使用更多计算资源训练的语言模型往往也会有更多的参数,因此我们在附录D中还展示了以模型参数数量为x轴的图表(见图11和图12,以及图4和图10)。由于大多数密集变压器语言模型家族在训练计算上大致与模型参数成比例(Kaplan等人,2020),因此使用训练FLOPS或模型参数作为x轴会产生形状相似的曲线。
训练数据集大小也是一个重要因素,但我们没有绘制能力与它的关系,因为许多语言模型族在所有模型大小上都使用固定数量的训练示例(Brown等人,2020;Rae等人,2021;Chowdhery等人,2022)。虽然我们在这里关注训练计算能力和模型大小,但没有一个代理能充分捕获规模的所有方面。例如,Chinchilla(Hoffmann等人,2022)的参数比Gopher(Rae等人,2021)少四分之一,但使用的训练计算量相似;稀疏混合专家模型的每个训练/推理计算量的参数比稠密模型多(Fedus等人,2021;Du等人,2021)。总的来说,把涌现看作多个相关变量的函数可能是明智的。例如,在图4后面,我们还将绘制基于WikiText103困惑度(Merity等人,2016)的涌现性,它恰好与Gopher / Chinchilla的训练计算量密切相关(尽管这种相关性可能不会长期保持)。
请注意,能力首次出现的规模取决于许多因素,并不是该能力的一个不变属性。例如,可能在训练计算量较少的情况下就已出现。
请注意,能力首次出现的规模取决于许多因素,并不是该能力的一个不变属性。例如,可能在训练计算量较少的情况下就已出现。
对于使用更高质量的数据训练的模型,可以减少模型参数。反之,涌现能力也严重依赖于其他因素,例如不受数据量、质量或模型参数数量的限制。如今的语言模型可能没有被最优地训练(Hoffmann等人,2022),我们对如何最好地训练模型的理解会随着时间的推移而演变。本文的目标不是描述或声称观察到涌现能力需要特定的规模,而是讨论先前工作中涌现行为的例子。
当模型在一定规模之前随机表现,之后性能显著高于随机水平时,通过少量提示执行任务的能力就会出现。图 2 展示了来自各种工作的五个语言模型家族中的八种此类新兴能力。
图2A-D展示了来自 BIG-Bench 的四个新兴的提示式任务,这是一个由超过200个基准测试组成的众包语言模型评估套件( BIG-Bench, 2022)。图2A显示了一个算术基准测试,用于测试三位数加减法以及两位数乘法。在几万倍训练计算量之前,GPT-3 和 LaMDA( Thoppilan 等人,2022 年)的性能接近于零,然后在 GPT-3 的 2 × 10^22 训练浮点运算次数(130 亿个参数)处急剧上升,在 LaMDA 的 10^23 训练浮点运算次数(680 亿个参数)处也急剧上升。在其他任务中,例如从国际音标转写(图2B)、从乱序字母恢复单词(图2C)和波斯语问答(图2D),也会出现类似的涌现行为。 BIG-Bench 中的更多涌现能力请参见附录E。
TruthfulQA。图 2E 展示了 TruthfulQA 测试基准上的一些提示性能,该基准用于衡量回答问题时的真实性(Lin等人,2021)。此基准针对 GPT-3 模型进行了恶意策划,即使在放大到最大的模型大小时,它们的表现也不如随机表现。当小 Gopher 模型扩展到具有 5 × 10^23 训练浮点运算 (280B 参数) 的最大模型时,其表现也没有超过随机表现,在这种情况下,性能跃升至高于随机值的 20% 以上(Rae 等人,2021 年)。
多任务语言理解。图 2G 展示了大规模多任务语言理解 (MMLU) 基准,该基准包含涵盖数学、历史、法律等主题的 57 项测试(Hendrycks 等人,2021 年)。对于 GPT-3、Gopher 和 Chinchilla 模型,训练浮点运算次数为 10^22(约 100 亿个参数)或更少的模型在所有主题上的平均表现不如随机猜测,而达到 3–5×10^23 训练浮点运算次数(70–280 亿个参数)时,性能显著优于随机猜测。这一结果令人惊讶,因为它可能意味着解决大量跨学科知识的问题需要超越这个阈值(对于没有检索或访问外部内存的稠密语言模型)。
LaMDA - (GPT-3 Gopher Chinchilla PaLM Random)
图 2:在 few-shot 提示设置下的八个涌现示例。每个点代表一个单独的模型。当语言模型达到一定的规模时,通过 few-shot 提示执行任务的能力会显著提高,从而显著超过随机性能。请注意,使用更多训练计算的模型通常具有更多的参数——因此我们在图 11 中显示了一个与训练浮点运算数量而不是模型参数数作为 x 轴的相似的图。A-D:BIG-bench(2022),两轮。E:Lin等人。(2021)和Rae等人。(2021)。F:Patel 和 Pavlick(2022)。G:Hendrycks 等人。(2021a),Rae 等人。(2021)和 Hoffmann 等人。(2022)。H:Brown 等人。(2020),Hoffmann 等人。(2022)和 Chowdhery 等人。(2022)在 WiC 基准上(Pilehvar 和 Camacho-Collados,2019 年)。
语境中的单词。最后,图 2H 显示了语境中的单词 (WiC) 基准(Pilehvar 和 Camacho-Collados, 2019 年),这是一个语义理解基准。值得注意的是,即使在扩大到其最大的模型大小(约 5×10^23 Flops)时,GPT-3 和 Chinchilla 也无法实现比随机更好的单次性能。尽管到目前为止的结果可能表明单独扩展模型无法使其解决 WiC,但当 PaLM 扩展到 2.5×10^24 Flops(540B 参数)时,最终出现了高于随机的性能,这远远超过了 GPT-3 和 Chinchilla 的规模。
虽然目前零样本提示可能是在大型语言模型上进行交互最常用的方法,但最近的研究已经提出了几种其他的提示和微调策略来进一步增强语言模型的能力。
图3:专门提示或微调方法可能在达到一定模型规模之前不会产生积极效果。A:Wei等人,(2022年)。B:Wei等人,(2022年)。C:Nye等人,(2021年)。D:Kadavath等人,(2022年)。图12中给出了一个与训练浮点运算数量无关但以参数数量为x轴的类似图表。A到C中的模型是LaMDA(Thoppilan等人,2022),而D中的模型来自Anthropic。
多步推理。多步骤推理任务对于语言模型和更广泛的NLP模型来说一直具有挑战性(Rae等人,2021;Bommasani等人,2021;Nye等人,2021)。最近提出的一种称为思维链提示的策略使语言模型能够通过引导它们在给出最终答案之前产生一系列中间步骤来解决此类问题(Cobbe等人,2021;Wei等人,2022b;Zhou等人,2022)。如图3A所示,当扩大到1023训练浮点运算时(~100B参数),思维链提示仅超过标准提示没有中间步骤。在使用来自最终答案后的解释增强少量提示性能方面也观察到了类似的性能提升(Lampinen等人,2022)。
指令跟随。另一个不断增长的研究领域旨在通过阅读描述任务的指令(不使用示例)来更好地使语言模型执行新任务。通过在以指令形式表述的任务混合体上进行微调,已证明语言模型能够对描述未知任务的指令做出适当反应(Ouyang等人,2022;Wei等人,2022a;Sanh等人,2022)。如图3 B 所示,Wei 等人(2022a)发现,这种指令微调技术会降低训练浮点运算次数为7×1021(8B 参数)或更少的模型的性能,并且仅当扩展到1023个训练浮点运算次数(~100B 参数)时才会提高性能(尽管Sanh等人[2022]很快发现,这种指令遵循行为也可以由微调较小的编码器解码器T5模型来诱导)。
程序执行。考虑涉及多个步骤的计算任务,例如大数相加或运行计算机程序。Nye等人。(2021)表明微调语言模型以预测中间输出(“临时存储区”)使其能够成功地执行此类多步计算。如图3C所示,在8位数相加时,仅使用临时存储区有助于训练浮点运算次数为~9×10^19(40M个参数)或更大的模型。
模型校准。最后,语言模型部署的重要方向之一是校准,它衡量模型是否能够预测哪些问题它们能够正确回答。Kadavath等人(2022)比较了两种测量校准的方法:真/假技术,其中模型首先提出答案,然后评估其答案“P(True)”正确的概率;以及更标准的校准方法,使用正确答案与其他答案选项的概率进行比较。如图3 D 所示,当缩放到最大模型规模时,真/假技术的优势才会显现 ∼3 × 1023 训练浮点运算 (52B 参数)。
表1:大型语言模型涌现能力列表以及这些能力出现时的规模(训练浮点运算次数和模型参数数量)。
5 讨论
我们已经看到,在小样本提示设置或其他情况下,各种能力只在评估足够大的语言模型时才被观察到。因此,仅通过推断较小规模模型的性能无法预测它们的出现。新出现的小样本提示任务也是不可预测的,因为这些任务没有明确包含在预训练中,而且我们可能不知道语言模型可以执行的所有小样本提示任务的全部范围。这提出了一个问题:进一步扩展是否有可能赋予更大的语言模型新的涌现能力?语言模型目前不能完成的任务很可能是未来涌现能力的首要候选者;例如,大型GPT-3和PaLM模型甚至都无法达到随机以上的性能水平,而在BIG-bench中有数十个这样的任务(见附录E.4)。
可扩展性意外地启用新方法的能力并不仅仅是理论上的。以历史例子为例,考虑“在上下文中单词”(WiC)基准(Pilehvar 和 Camacho-Collados,2019 年),如图 2H 所示。在这里,将 GPT-3 扩展到大约 3 × 10^23 训练浮点运算 (175B 参数) 的规模并未解锁高于随机的一次提示性能。关于这一负面结果,Brown 等人。(2020) 指出 GPT-3 的模型架构或自回归语言建模目标的使用(而不是去噪训练目标的使用)可能是潜在的原因,并建议通过双向架构训练一个大小相当的模型作为补救措施。然而,后来的研究发现进一步扩大仅解码器的语言模型实际上足以在这项任务上实现超过随机性能。如图 2H 所示,从 3 × 10^23 训练浮点计算 (62B 参数) 扩大到 3 × 10^24 训练浮点计算 (540B 参数) 将 PaLM(Chowdhery et al.,2022) 的性能显着提高,而无需 Brown 等人。(2020) 建议的重大架构更改。
5.1 萌芽的可能解释
尽管涌现能力的例子有很多,但目前很少有令人信服的解释来解释为什么这些能力会以这样的方式出现。对于某些任务来说,可能有一种直观的感觉,即涌现需要一个比特定阈值尺度更大的模型。例如,如果一个多步骤推理任务需要 l 步序列计算,那么这可能需要至少深度为 O(l) 层的模型。还合理地假设更多的参数和更多的训练能够实现更好的记忆,这对需要世界知识的任务是有益的。4 例如,在封闭书籍问答中表现出色可能需要一个具有足够参数来捕获压缩的知识库本身的模型(尽管基于语言模型的压缩器可以比传统压缩器具有更高的压缩率(Bellard, 2021))。
5.2 超越扩展
虽然我们可能会观察到一种在某个尺度上出现的能力,但这种能力可能在较小的尺度上实现——换句话说,模型规模并不是解锁涌现能力的唯一因素。随着训练大型语言模型的科学不断进步,某些能力可以通过具有新架构、更高质量的数据或改进训练过程的小型模型来解锁。例如,在 14 个 BIG-Bench 任务中,LaMDA 137B 和 GPT-3 175B 模型的表现接近随机,而 PaLM 62B 实际上实现了超过随机的表现,尽管其模型参数和训练浮点运算 (FLOP) 较少。虽然没有实证研究消除了 PaLM 62B 和之前模型之间的所有差异(计算成本太高),但 PaLM 表现更好的潜在原因包括高质量的训练数据(例如比 LaMDA 更多的多语种和代码数据)以及结构上的差异(例如数字编码的拆分;见 Chowdhery 等人 (2022) 的第 2 部分)。
。
此外,一旦发现了一种能力,进一步的研究可能会使这种能力在较小规模的模型上得到应用。例如,让语言模型能够遵循描述任务的自然语言指令(Wei等人,2022a;Sanh等人,2022;Ouyang等人,2022等)。虽然最初Wei等人(2022a)发现基于指令的微调仅适用于参数为68B或更大的解码器模型,但Sanh等人(2022)在一个具有编码器-解码器架构的11B模型中诱导了类似的行为,该模型通常在微调后比纯解码器架构表现更好(Wang等人,2022a)。另一个例子是,Ouyang等人(2022)针对InstructGPT模型提出了一个基于人类反馈的强化学习方法,使得一个13亿参数的模型能够在广泛的应用场景中的人类评分者评估中优于大得多的模型。
还有针对提高语言模型一般性的少样本提示能力的工作(Gao等人,2021;Schick和Schütze,2021等)。为什么语言建模目标促进某些下游行为的理论和可解释性研究(Wei等人,2021a;Saunshi等人,2021)可能会对如何使涌现行为超出现有的简单扩大规模的方法产生影响。例如,预训练数据的一些特征(如长程连贯性和具有许多罕见类别)也被证明与新兴的少样本提示相关,并且可能使较小的模型能够实现它(Xie等人,2022;Chan等人,2022),并且在某些情况下,少样本学习需要特定的模型架构(Chan等人,2022)。计算语言学工作还进一步表明,当模型参数和训练浮点运算保持不变时,训练数据的阈值频率可以激活新兴的句法规则学习(Wei等人,2021b),甚至已经被证明具有类似心理语言学文献中的“啊哈!”时刻(Abend等人,2017;Zhang等人,2021)。随着我们继续训练越来越大的语言模型,降低涌现能力的门槛对于让更广泛的研究人员能够研究这些能力变得更加重要(Bommasani等人,2021;Ganguli等人,2022;Liang等人,2022)。
当然,仅通过增加规模(训练计算、模型参数和数据集大小)来实现的程序存在局限性。例如,随着硬件限制最终成为瓶颈,某些能力可能尚未出现。其他能力可能永远不会出现——例如,即使使用非常大的训练数据集,某些任务也永远无法达到任何显著性能。最后,一个能力可能会出现并保持稳定;换句话说,没有保证扩大规模能够使能力达到预期水平。
5.3 新涌现视角
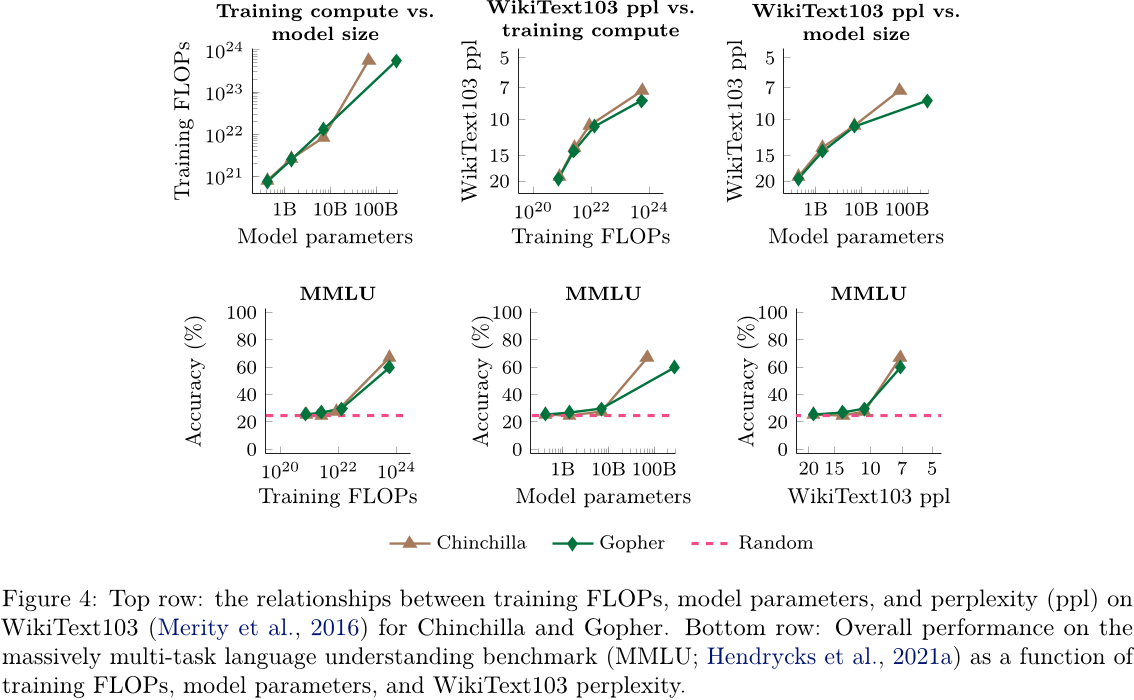
到目前为止,尽管规模(例如训练浮点运算次数或模型参数)在很大程度上与下游指标上的语言建模性能相关,但规模并不一定是查看新兴能力的唯一视角。例如,特定任务的能力的出现可以分析为基于语言模型在通用文本语料库(如 WikiText-103 (Merity 等,2016 年) 上的困惑度。图 4 显示了该图表,其中语言模型在 WikiText-103 上的困惑度位于 x 轴,MMLU 基准测试上的性能位于 y 轴,并且与 x 轴上的训练浮点运算次数和模型参数并排显示。
由于 WikiText103 的困惑度和训练浮点运算发生器在考虑的模型(Gopher 和 Chinchilla)中高度相关,因此新兴能力的图表看起来相似。然而,随着未来开发出超越标准密集型变形金刚模型的新技术(例如检索增强模型可能具有较强的 WikiText103困惑度,同时需要更少的训练计算和更少的模型参数),这种 WikiText103困惑度与规模之间的相关性可能会改变。(Borgeaud等人,2021)。另外,请注意,使用 WikiText103困惑度来比较不同模型族可能会很复杂,因为诸如训练数据组成差异等因素。总的来说,新兴能力应该被视为许多相关变量的函数。
5.4 突发风险
重要的是,正如在小样本提示设置中观察到的涌现能力没有明确包含在预训练中一样,风险也可能出现(Bommasani等人,2021;Steinhardt,2021;Ganguli等人,2022)。例如,大型语言模型的社会风险,如真实性、偏见和毒性,是研究的一个快速增长领域(Weidinger等人,2021)。这些风险是重要的考虑因素,无论它们是否可以根据第2节中的定义准确地描述为“涌现”,并且,在某些情况下,确实会随着模型规模的增加而增加(参见逆向缩放奖品6)。由于对涌现能力的研究鼓励了语言模型的扩展,因此即使风险不是涌现出来的,也要意识到与模型规模相关的风险很重要。
在这里,我们总结了关于特定社会风险与模型规模之间关系的一些先前发现。在WinoGender(Rudinger等人,2017年),它衡量了诸如“护士”或“电工”等职业中的性别偏见,到目前为止,规模扩大已经提高了性能(Du等人,2021;Chowdhery等人,2022)。尽管如此,
BIG-Bench (2022) 在 BBQ 偏见基准测试(Parrish等人,2022)中发现,在模糊语境下,偏见会随着模型规模的增加而增加。至于毒性方面,Askell 等人(2021)发现,尽管更大的语言模型可以产生更多来自 Gehman 等人(2020)的真实毒性提示数据集中的有毒响应,但通过向模型提供“有用、无害且诚实”的示例,这种行为是可以缓解的。在从语言模型提取训练数据时,发现较大的模型更有可能记住训练数据(Carlini 等人,2021;2022),尽管已经提出了去重方法,并且可以在同时减少记忆并提高性能(Kandpal 等人,2022;Lee 等人,2022a)。 TruthfulQA 指标(Lin 等人,2021)表明,GPT-3 模型随着规模增大更容易模仿人类的虚假陈述,尽管 Rae 等人(2021)后来在一个多项选择版本上展示了对 Gopher 进行 280B 规模扩展可实现比随机选择显著更好的涌现性能。
对提示有更好的技术和理解。虽然少量提示(Brown等人,2020)简单而有效,但对提示的一般改进可能会进一步扩展语言模型的能力。例如,简单的修改,如校准输出概率(赵等,2021年;
使用提示( Holtzman 等人,2021 年)或通过嘈杂通道( Min 等人,2021 年)已经提高了在各种任务上的性能。中间步骤( Reynolds 和 McDonell,2021;Nye 等人,2021;Wei 等人,2022b)还使模型能够执行标准提示形式(Brown 等人,2020 年)中不可能进行的多步推理任务。此外,更好地探索是什么使得提示成功(Wei 等人,2021a;Xie 等人,2022;Min 等人,2022;Olsson 等人,2022),可以为如何在较小的模型规模上引发新兴能力提供见解。通常对为什么模型有效存在充分理解,这落后于诸如少量提示等技术的发展和普及,随着时间的推移,随着开发出更强大的模型,提示的最佳实践也可能会改变。
前沿任务。尽管语言模型可以执行各种各样的任务,但仍然有许多任务,即使是迄今为止最大的语言模型也无法以高于随机准确度的方式执行。 BIG-bench 中列举了数十个这样的任务;这些任务通常涉及抽象推理(例如,下棋、挑战数学等)。未来的研究可能会调查为什么尚未出现这些能力,以及如何使模型能够执行这些任务。展望未来,另一个增长方向可能是多语种涌现;在多语种 BIG-bench 任务上的结果表明,模型规模和训练数据都对涌现起作用(例如,图 2 D 表明,回答波斯语问题需要使用 PaLM 的训练数据集并扩展到 620 亿个参数)。其他前沿任务可能包括跨多个模态提示(Alayrac等人,2022 年;Ramesh 等人,2022 年)。
理解涌现。除了进一步研究如何解锁涌现任务之外,未来的研究中的一个重要开放性问题是如何以及为什么在大型语言模型中出现涌现能力。在这篇论文中,我们对 BIG-Bench 中的交叉熵损失的缩放进行了初步分析(附录A.1),生成任务的不同度量(附录A.2)以及涌现发生在哪些类型的任务中(附录A.3 和附录B)。这些分析并没有完全回答为什么会涌现或如何预测它的问题。未来的研究所能做的可能是以新的方式来分析涌现(例如:分析涌现任务与训练数据之间的关系;创建一个需要多个组合子任务的合成任务,并评估每个子任务随着规模增大而提高的程度以及它们结合时产生的涌现现象)。总的来说,理解涌现是一种重要的方向,因为它可能会让我们能够预测未来模型可能具备的能力,并为如何训练更强大的语言模型提供新的见解。
6 结论
我们讨论了语言模型的涌现能力,这种能力仅在一定的计算规模上观察到有意义的表现。涌现能力可以跨越各种语言模型、任务类型和实验场景。这些能力是最近对扩大语言模型规模的结果,并且似乎需要研究它们是如何出现的以及是否会出现更多的涌现能力,这似乎是自然语言处理领域的重要未来研究方向。
在本文中,我们综述了现有文献中的结果,而没有提出新的方法或模型。如第 5 节所述,涌现能力以多种方式具有不可预测性,并包括涌现风险(见第 5.4 节)。我们认为这些现象值得仔细研究,并为该领域提出了重要的问题。
这篇关于Emergent Abilities of Large Language Models 机翻mark的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)


