本文主要是介绍Vue3+Vite使用Puppeteer进行SEO优化(SSR+Meta),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 背景
【笑小枫】https://www.xiaoxiaofeng.com上线啦
资源持续整合中,程序员必备网站,快点前往围观吧~

我的个人博客【笑小枫】又一次版本大升级,虽然知道没有多少访问量,但我还是整天没事瞎折腾。因为一些功能在Halo上不太好实现,所以又切回了Vue3项目,本文就是对于Vue单页面项目SEO优化的一个简单的完整方案。
此次优化的最大好处,就是SSR时对已有的vue项目0侵入,不需要改任何的代码,赞啊👍👍👍
2. 技术选型
- vue:3.2.47
- vite:2.9.9
- vue-meta:3.0.0-alpha.8
- puppeteer:19.8.0
2.1 简单描述下如何SEO
唉,说实话,是个毛线的选型,我是先吭哧吭哧把项目上线了,才又想起来SEO这个坑,心累~
对于Vue来说,SEO最大的坑,如何返回渲染后的页面,也就是下面说的SSR了,然后就是动态Meta。
看看Vue.js关于SSR的介绍吧,很详细,也给出了方案
https://cn.vuejs.org/guide/scaling-up/ssr.html#overview


确实,Vue也给出了更通用的方案。
全程百度+cv写出的Vue代码,这些通用的方案并不适合我。
2.2 简单说说这几种方案吧
- 网上比较多的是使用
Nuxt.js,但是用我已经开发好的项目来改,说实话,前端小白的我实在是改不动了。 Quasar不太了解,不过多介绍了。Vite SSR,Vite提供了内置的Vue服务端渲染支持。也要改已有代码,不想改,不会改。
好吧,官方给的方案被我否定了,就是想找个不用修改已有代码的方法。太难了~
经过不懈的百度努力,发现了一线生机phantomjs,简单说说这个吧
Phantomjs是一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现。虽然“PhantomJS宣布终止开发”,但是已经满足对Vue的SEO处理。
这种解决方案其实是一种旁路机制,原理就是通过Nginx配置,判断访问的来源UA是否是爬虫访问,如果是则将搜索引擎的爬虫请求转发到一个node server,再通过PhantomJS来解析完整的HTML,返回给爬虫。
废了好大一番功夫,然后爬取到的数据仍然是没有渲染的数据,尴尬的一批。
2.3 我使用的解决方案
说了这么多废话,说说我的最终解决方案吧~
用的方式类似于PhantomJS,使用的Puppeteer
Puppeteer 是一个 Node.js 库,它提供了一个高级 API 来通过开发工具协议控制 Chrome/Chromium。 Puppeteer 默认以无头模式运行,但可以配置为在完整 (“有头”) Chrome/Chromium 中运行。
Puppeteer的作用,我主要用到的是SSR:
- 生成页面的屏幕截图和 PDF。
- 抓取 SPA(单页应用)并生成预渲染内容(即 “SSR”(服务器端渲染))。
- 自动化表单提交、UI 测试、键盘输入等。
- 使用最新的 JavaScript 和浏览器功能创建自动化测试环境。
- 捕获站点的时间线痕迹以帮助诊断性能问题。
- 测试 Chrome 扩展程序。
3. SEO实现-Meta设置
meta标签用于设置HTML的元数据(描述数据的数据),该数据不会显示在页面中,主要用于浏览器(如和现实内容或重新加载页面)、搜索引擎(如SEO)及其他web服务,这里使用vue-meta进行设置。
3.1 Vue-meta 简介与安装
-
Vue-meta 是一个 Vue.js 的插件,允许你在组件中操作应用的 meta 信息,如标题、描述等。它对于单页应用 (SPA) 和服务端渲染 (SSR) 的项目特别有价值,因为它们在处理 meta 信息方面要比传统的多页面应用要复杂得多。
-
为了使用 Vue-meta,首先需要安装。推荐使用 npm 进行安装,执行以下命令即可:
npm i -S vue-meta@next
目前 vue-meta3 还是处于 alpha 阶段,不要低于 3.0.0-alpha.7
- 接下来,需要在 Vue 项目中引入并使用 Vue-meta。在项目的 main.js 文件中,添加如下代码:
import { createApp } from "vue";
import { createMetaManager} from 'vue-meta'const app = createApp(App);app.use(createMetaManager(false, {meta: { tag: 'meta', nameless: true }}));
app.mount("#app");
- 在
App.vue中添加<metainfo></metainfo>标签,一定要添加,不然不生效哟
<template><metainfo></metainfo><router-view />
</template>
3. 在组件中使用 Vue-meta
- 安装并引入 Vue-meta 后,可以在 Vue 组件中使用它。要在组件中添加 meta 信息,如标题、描述等,可以在组件内引用,在onMounted中设定相关的信息:
<script setup>import {onMounted} from "vue";import { useMeta } from 'vue-meta';onMounted(() => {useMeta({title: '笑小枫🍁 - 程序员的世外桃源',meta: [{ name: 'keywords', content: '笑小枫,java,SpringBoot,程序员' },{ name: 'description', content: '欢迎来到笑小枫,我们致力于打造一个开放、友好的技术社区,让知识和智慧在这里自由碰撞、绽放。欢迎加入我们的旅程,一起在技术的海洋中探索无限可能!' }]});});
</script>
- 上述代码中,我们设定了页面的 title(标题)为 “Vue-meta 示例”,并添加了两个 meta 标签:description(描述)和 keywords(关键词)。组件渲染时,Vue-meta 将自动更新这些 meta 信息。
3.3 Vue-meta 的高级用法
- Vue-meta 不仅可以设置 meta,还支持设置其他 HTML 标签,如 link、style、script 等。下面是一个为页面添加样式和脚本的例子:
<script setup>import {onMounted} from "vue";import { useMeta } from 'vue-meta';onMounted(() => {useMeta({title: '笑小枫🍁 - 程序员的世外桃源',meta: [{ name: 'keywords', content: '笑小枫,java,SpringBoot,程序员' },{ name: 'description', content: '欢迎来到笑小枫,我们致力于打造一个开放、友好的技术社区,让知识和智慧在这里自由碰撞、绽放。欢迎加入我们的旅程,一起在技术的海洋中探索无限可能!' }],link: [{rel: 'stylesheet',href: 'https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.min.css'}],script: [{src: 'https://cdnjs.cloudflare.com/ajax/libs/jquery/3.6.0/jquery.min.js',async: true,body: true,}]});});
</script>
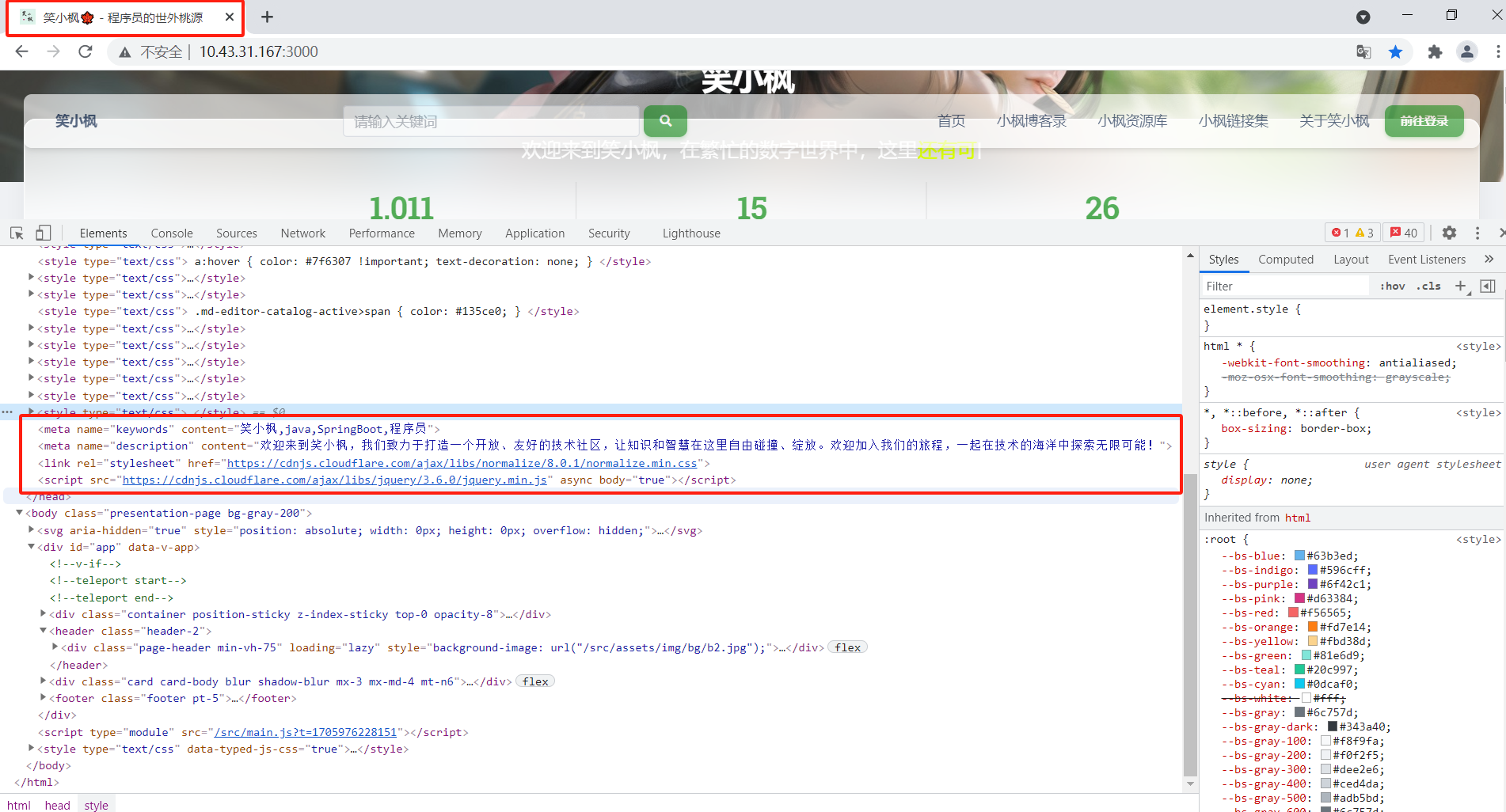
- 通过请求后台数据,数据请求成功后,动态设置meta属性。最开始是放在
onMounted中,因为数据也是放在onMounted中,感觉数据没有请求完,meta就渲染完了,导致不生效,暂时不知道怎么解决,误打误撞中,动态的页面会触发onUpdated事件,于是就取巧放在了onUpdated中,希望知道原因的前端大佬可以给予指导🙏🙏🙏
省略了非关键性代码,正常不会触发onUpdated,这里误打误撞了…
<script setup>import {onMounted, ref, onUpdated} from "vue";import { useMeta } from 'vue-meta';onMounted(() => {getArticleByIdClick();});onUpdated(() => {useMeta({title: articleInfo.value.title + '- 笑小枫🍁',meta: [{ name: 'keywords', content: articleInfo.value.keywords },{ name: 'description', content: articleInfo.value.description }]})})
</script>

4. SEO实现-使用Puppeteer进行SSR
Puppeteer中文网
上文简单介绍了Puppeteer,这里就不过多的介绍Puppeteer了,如需了解,可以去官网
搭建用到的工具
- node
- npm
- puppeteer
- express
- html-minifier
- google-chrome
- nginx
4.1 安装Node.js和npm
已经安装过node.js的机器忽略这部分即可,可以通过node -v查看
- 进入node安装目录
cd /opt
- 下载安装包
wget https://nodejs.org/dist/v17.9.0/node-v17.9.0-linux-x64.tar.gz
- 解压安装包
tar -xzvf node-v17.9.0-linux-x64.tar.gz
- 设置软连接,建立快捷命令
ln -s /opt/node-v17.9.0-linux-x64/bin/node /usr/local/bin/
ln -s /opt/node-v17.9.0-linux-x64/bin/npm /usr/local/bin/
- 使用
node -v查看是否安装成功

4.2 安装 Puppeteer 及相关扩展工具
- 创建并进入项目目录,会生成node_modules
cd /home/wwwroot
mkdir puppeteer
cd puppeteer
- 安装 puppeteer,express 与 html-minifier
npm install puppeteer --save
npm install express
npm install html-minifier
- 安装依赖库
yum install pango.x86_64 libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86
4.3 创建服务器端运行脚本
- 创建渲染请求的页面脚本:spider.js
const puppeteer = require('./node_modules/puppeteer');//由于目录不一致,所以使用的是绝对路径
const WSE_LIST = require('./puppeteer-pool.js'); //这里注意文件的路径和文件名
const spider = async (url) => {let tmp = Math.floor(Math.random() * WSE_LIST.length);//随机获取浏览器let browserWSEndpoint = WSE_LIST[tmp];//连接const browser = await puppeteer.connect({browserWSEndpoint});//打开一个标签页var page = await browser.newPage();// Intercept network requests.await page.setRequestInterception(true);page.on('request', req => {// Ignore requests for resources that don't produce DOM// (images, stylesheets, media).const whitelist = ['document', 'script', 'xhr', 'fetch'];if (!whitelist.includes(req.resourceType())) {return req.abort();}// Pass through all other requests.req.continue();});//打开网页await page.goto(url, {timeout: 20000, //连接超时时间,单位mswaitUntil: 'networkidle0' //网络空闲说明已加载完毕});//获取渲染好的页面源码。不建议使用await page.content();获取页面,因为在我测试中发现,页面还没有完全加载。就获取到了。页面源码不完整。也就是动态路由没有加载。vue路由也配置了history模式let html = await page.evaluate(() => {return document.getElementsByTagName('html')[0].outerHTML;});await page.close();return html;
}module.exports = spider;- 创建优化puppeteer性能角本,默认不加载一些多余的功能,提高访问效率:puppeteer-pool.js
const puppeteer = require('./node_modules/puppeteer');
const MAX_WSE = 2; //启动几个浏览器
let WSE_LIST = []; //存储browserWSEndpoint列表
//负载均衡
(async () => {for (var i = 0; i < MAX_WSE; i++) {const browser = await puppeteer.launch({//无头模式headless: true,//参数args: ['--disable-gpu','--disable-dev-shm-usage','--disable-setuid-sandbox','--no-first-run','--no-sandbox','--no-zygote','--single-process'],//一般不需要配置这条,除非启动一直报错找不到谷歌浏览器//executablePath:'chrome.exe在你本机上的路径,例如C:/Program Files/Google/chrome.exe'});let browserWSEndpoint = await browser.wsEndpoint();WSE_LIST.push(browserWSEndpoint);}
})();module.exports = WSE_LIST- 创建服务端启动脚本:service.js
需要和spider.js放在一个目录
https://www.xiaoxiaofeng.com需要替换成你自己的域名
const express = require('./node_modules/express');
var app = express();
var spider = require("./spider.js");
var minify = require('html-minifier').minify;
app.get('*', async (req, res) => {let url = "https://www.xiaoxiaofeng.com" + req.originalUrl;console.log('请求的完整URL:' + url);let content = await spider(url).catch((error) => {console.log(error);res.send('获取html内容失败');return;});// 通过minify库压缩代码content=minify(content,{removeComments: true,collapseWhitespace: true,minifyJS:true, minifyCSS:true});res.send(content);
});
app.listen(3000, () => {console.log('服务已启动!');
});- 执行启动puppeteer命令
nohup node server.js &
启动成功后,可以通过tail -f nohup.out查看日志,出现服务已启动!则代表运行成功,期间可能会出现各式各样的问题,再百度一下吧,这里就不一一列举了。
相当与启动了一个端口为3000的puppeteer服务。
启动的时候可能端口占用 3000被占用的话就换一个其他端口。
同时也会在/root/.cache/puppeteer/chrome/下装一个对应版本的谷歌浏览器
4.4 配置Nginx
我这里用的是docker容器启动的Nginx,proxy_pass换成对应的地址就行了,然后重启Nginx。
location / {proxy_set_header Host $host:$proxy_port;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;if ($http_user_agent ~* "Baiduspider|twitterbot|facebookexternalhit|rogerbot|linkedinbot|embedly|quora link preview|showyoubot|outbrain|pinterest|slackbot|vkShare|W3C_Validator|bingbot|Sosospider|Sogou Pic Spider|Googlebot|360Spider") {proxy_pass http://172.17.0.1:3000;}alias /usr/share/nginx/html/;index index.html index.htm;try_files $uri $uri/ /index.html;
}
这样就可以了,让我们一起来测试一下吧
首先我们先正常的请求,不加请求头,请求结果如下,可以看到是没有渲染的vue页面。

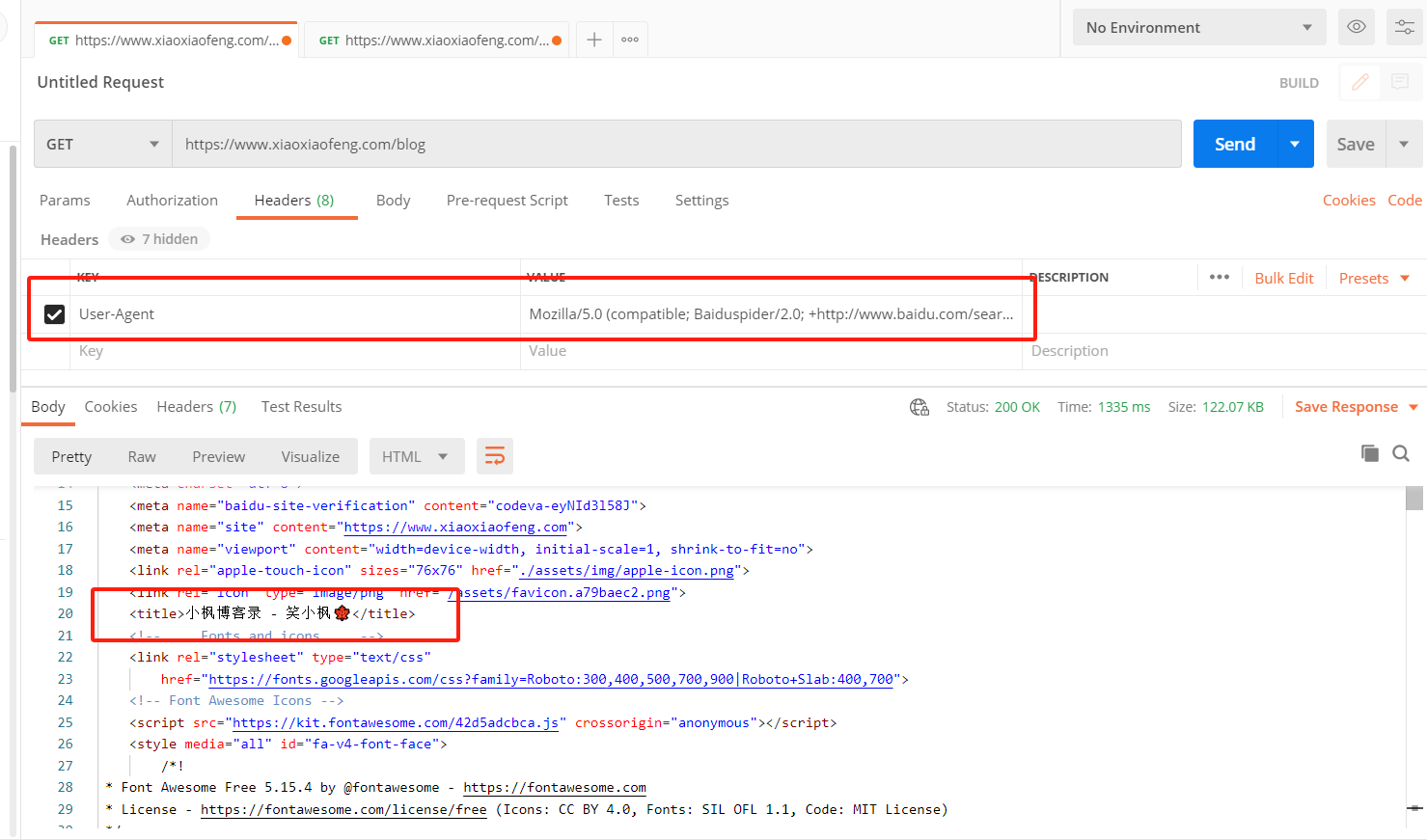
然后我们加上请求头(这里直接复制了百度请求头)User-Agent:Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html),再次访问,可以看到请求到了渲染后的网页。
我们最后再去百度收录看一下爬取诊断吧。
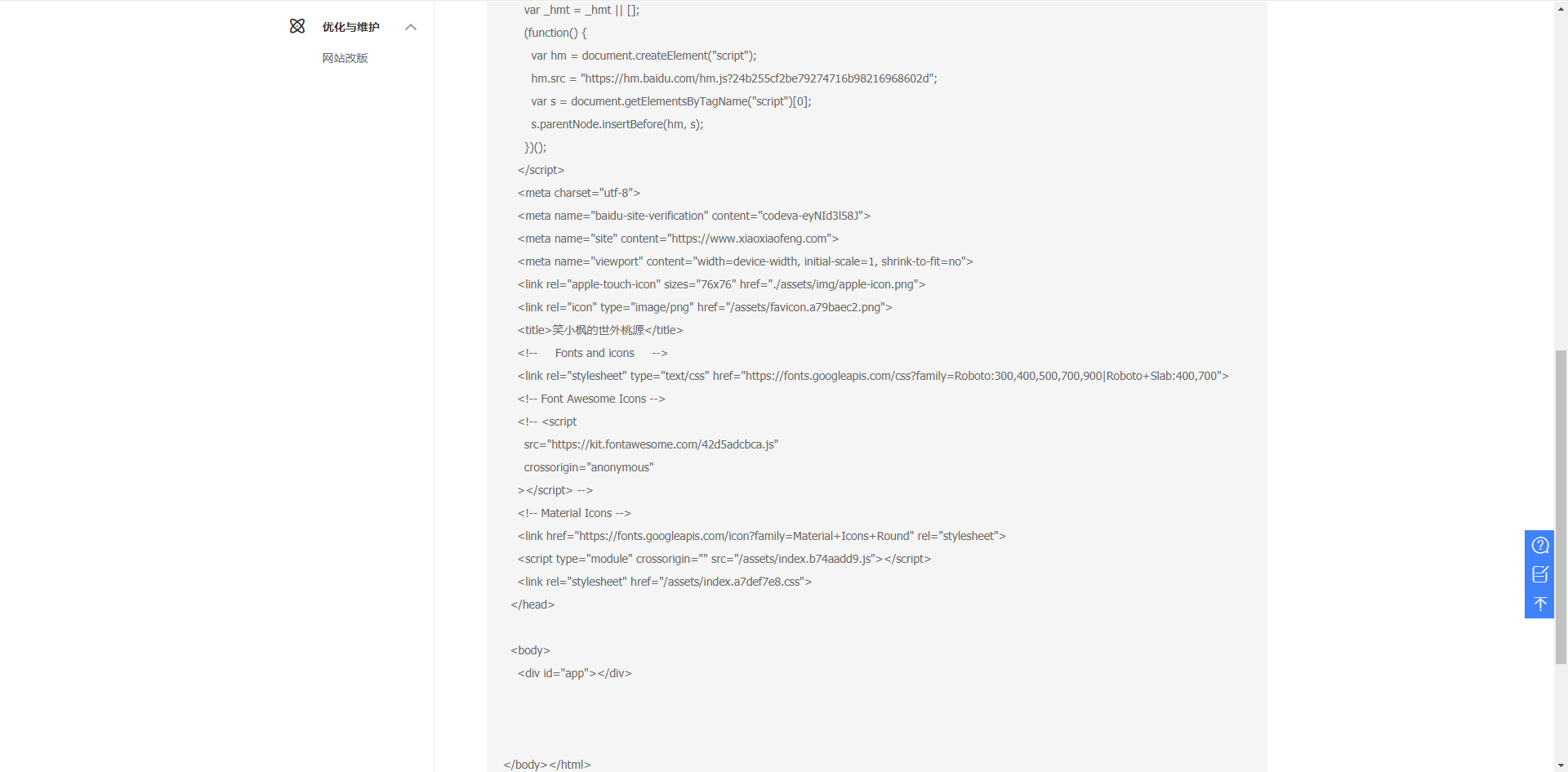
处理前,百度爬取到的内容:
处理后,百度爬取到的内容(截图有限,看滚动条就可以清楚看见):

最后,看一下我们网站访问有没有受影响吧,完美收官~
5.说说遇到的问题吧
- 首先通过服务器端渲染后返回,对服务器是有一定压力影响的,这个不可避免。
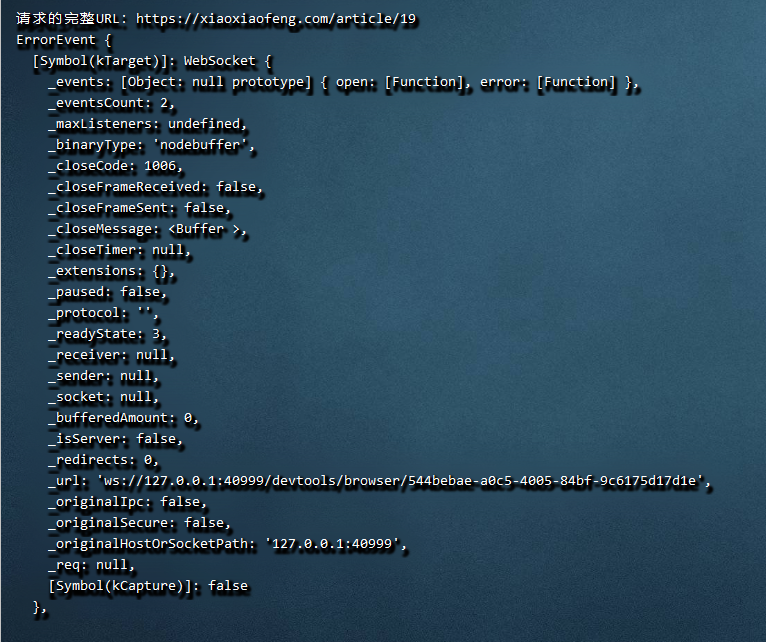
- 上线后时不时会遇到这个错误,然后后续请求都会一直报错,正在排查原因。(可能是服务器配置太低的问题)
- 每次都渲染JS,加载速度很慢
PS:莫名奇妙不知道优化了啥,速度一下提上来了,百度爬虫从原来的7s降到了1s,上文中的代码已经是优化后最新的代码。
6. 关于笑小枫
本文到此就结束了,如果帮助到你了,帮忙点个赞👍
🐾我是笑小枫,全网皆可搜的【笑小枫】
这篇关于Vue3+Vite使用Puppeteer进行SEO优化(SSR+Meta)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





