puppeteer专题

【截图服务 +打包】pkg打包 puppeteer
目录 最后结论 遇到的问题与解决 版本匹配问题 参考文档 最后结论 pkg -t win --public ./screenshots.js --output ./dist/screen.exe 服务启动: postman调用 : 遇到的问题与解决 版本匹配问题 pkg 这里说的是v3.5,实际装的是5.8.1,没有关系;可以向下兼容。 但node

【Puppeteer】‘left‘ is already pressed, ‘${button}‘ is already pressed 的解决办法
解决过程如下 这是我原来的代码,不管我怎么修改,都一直会出现 'left' is already pressed 这个错误 找了很多资料 搜了 很多网站都 找不到解决办法 async function dragAndDrop(page, canvasSelector, startX, startY, endX, endY) {const startCoordinates = await ge
Puppeteer的高级用法:如何在Node.js中实现复杂的Web Scraping
概述 随着互联网的发展,网页数据抓取(Web Scraping)已成为数据分析和市场调研的重要手段之一。Puppeteer作为一款强大的无头浏览器自动化工具,能够在Node.js环境中模拟用户行为,从而高效地抓取网页数据。然而,当面对复杂的网页结构和反爬虫机制时,基础的爬虫技术往往无法满足需求。本文将深入探讨如何在Node.js中利用Puppeteer的高级功能,实现复杂的Web Scrap

vue项目通过puppeteer做SEO,可以使用Puppeteer在Vue项目中进行SEO,通过服务端渲染获取渲染后的HTML内容,以便搜索引擎爬虫能够正确地索引您的网页内容。
正在使用的项目 https://manefuwu.com/ 下载vue-seo-puppeteer项目:https://github.com/lovelin0523/vue-seo-puppeteer npm install 查看puppeteer缺失的库 ldd node_modules/puppeteer/.local-chromium/linux-756035/chrome-lin

如何解决 Cloudflare | 使用 Puppeteer 和 Node.JS
我认为,现在自动化任务越多,越能体现它们的价值,因此挑战也变得更加明显和困难。例如,Cloudflare 目前提供了强有力的安全措施来保护网站免受所有形式的自动化工具的侵扰。 但对于从事自动化项目(如网络爬虫、数据提取或测试)的开发人员和组织来说,导航这些安全功能可能是一项挑战。然而,通过合适的工具和策略,您可以在遵守法律和道德标准的前提下,有效应对这些挑战。 因此,在本教程中,我将探讨如

Puppeteer Web 抓取:使用 Browserless 的 Docker
Docker 镜像介绍 Docker 镜像是用于在 Docker 容器中执行代码的文件。它类似于构建 Docker 容器的指令集,就像一个模板。换句话说,它们相当于虚拟机环境中的快照。 Docker 镜像包含运行容器所需的所有库、依赖项和文件,使其成为容器的独立可执行文件。这些镜像可以在多个位置共享和部署,因此具有高度的可移植性。 什么是 Browserless? Nstbrowser
Puppeteer 搭建
Puppeteer 是一个nodejs库,主要使用于以下: UI 自动化测试:摆脱手工浏览点击页面确认功能模式爬虫 Puppeteer 需要专用的浏览器,叫chormium,需要单独下载。 配置环境步骤 1.安装nodejs 2.配置国内chormium源 export PUPPETEER_DOWNLOAD_HOST=https://storage.googleapis.com.cn
使用node将页面转为pdf?(puppeteer实现)
本文章适合win系统下实验(linux,mac可能会出现些莫名其妙的bug我也不会解决) 具体过程 首先了解什么时无头浏览器启动无头浏览器打开指定的url页面设置导出pdf格式开始转化完整基础代码 首先了解什么时无头浏览器 没有界面的浏览器 下载puppeteer npm i puppeteer 下载中可能会出现文件,中途不要暂停,这个不用管 启动无头浏览器

不仅仅可以用来做爬虫,Puppeteer 还可以干这个!
Python 自动化测试工具大家可能知道 Pyppeteer,其实它就是 Puppeteer 的 Python 版本的实现,二者功能类似。但其实 Puppeteer 和 Pyppeteer 不仅仅可以用来做爬虫,还能干很多其他的事情,今天就来介绍用 Puppeteer 搞的一个骚操作——自动发文。 “ 阅读本文大概需要 6 分钟。 ” 前言 自动化测试对于软件开发来说是
译文:Puppeteer 与 Chrome Headless —— 从入门到爬虫
随时随地技术实战干货,获取项目源码、学习资料,请关注源代码社区公众号(ydmsq666) from:http://csbun.github.io/blog/2017/09/puppeteer/ Puppeteer 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具。正因为这个官方声明,许多业内自动化测试库都已经停止维护,包括 PhantomJS。Sele

Puppeteer的入门教程和实践
随时随地技术实战干货,获取项目源码、学习资料,请关注源代码社区公众号(ydmsq666)、QQ技术交流群(183198395)。 from:https://www.jianshu.com/p/2f04f9d665ce 出现的背景 Chrome59(linux、macos)、 Chrome60(windows)之后,Chrome自带headless(无界面)模式很方便做自动化测试或者

js爬虫puppeteer库 解决网页动态渲染无法爬取
我们爬取这个网址上面的股票实时部分宇通客车(600066)_股票价格_行情_走势图—东方财富网 我们用正常的方法爬取会发现爬取不下来,是因为这个网页这里是实时渲染的,我们直接通过网址接口访问这里还没有渲染出来 于是我们可以通过下面的代码来进行爬取: npm install puppeteer //index.jsconst puppeteer = require('puppetee
最新版puppeteer 在linux下的安装教程
最新版的 puppeteer 在安装的时候,Chromium不会自动下载,导致安装失败 这个时候需要跳过Chromium的安装,然后手动下载Chromium并安装。 1、先设置npm跳过Chromium下载 export PUPPETEER_SKIP_DOWNLOAD=true 2、安装puppeteer npm i puppeteer --save 3、下载Chromium
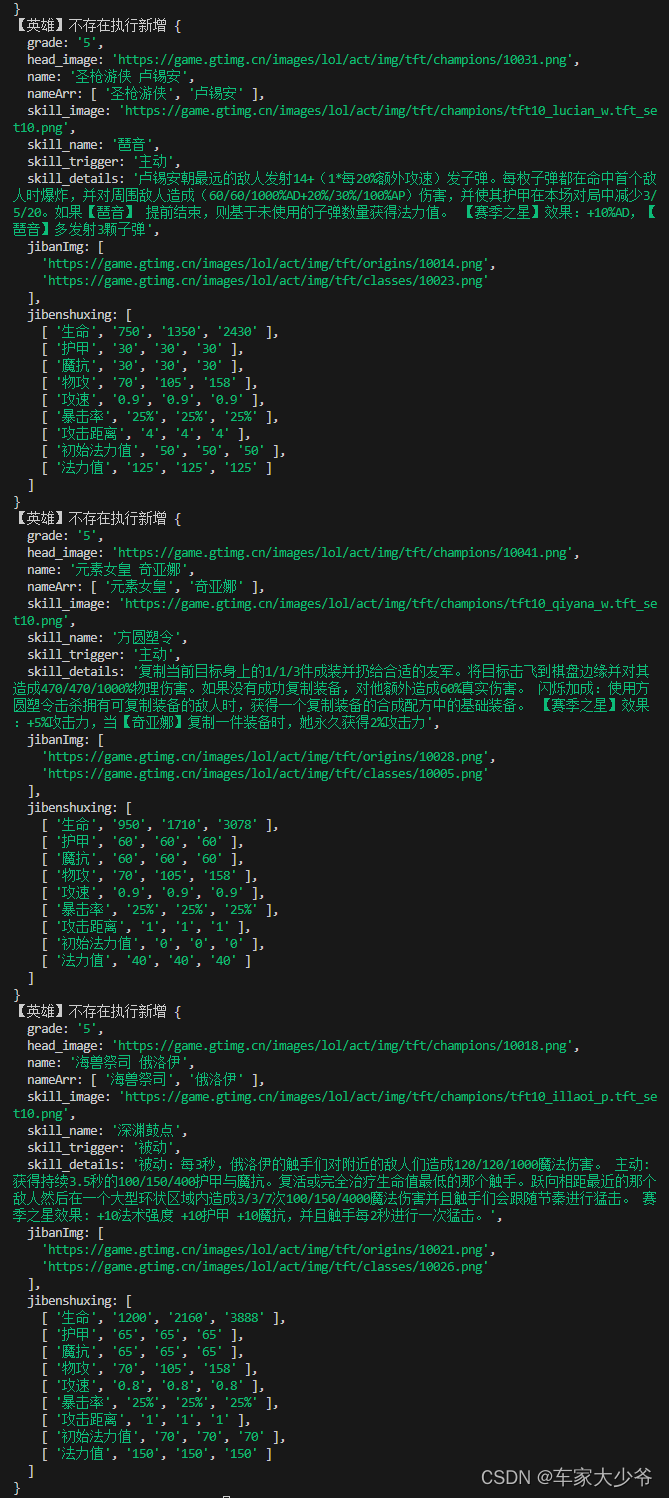
puppeteer使用示例云顶之弈官网
自己从0到1开发的,微信小程序【云顶宝藏】求求点个5星好评吧! 需求:拿到所有英雄的信息 思路:点击每个英雄,进入英雄详情页,拿信息,并返回,继续下一个英雄** 最终效果 本地环境 window系统 node版本:v18.16.1 puppeteer技术文档: https://pptr.nodejs.cn/guides/query-selectors 示例源码下载:htt
实例:使用puppeteer headless方式抓取JS网页
puppeteer google chrome团队出品的puppeteer 是依赖nodejs和chromium的自动化测试库,它的最大优点就是可以处理网页中的动态内容,如JavaScript,能够更好的模拟用户。 有些网站的反爬虫手段是将部分内容隐藏于某些javascript/ajax请求中,致使直接获取a标签的方式不奏效。甚至有些网站会设置隐藏元素“陷阱”,对用户不可见,脚本触发则认为是机
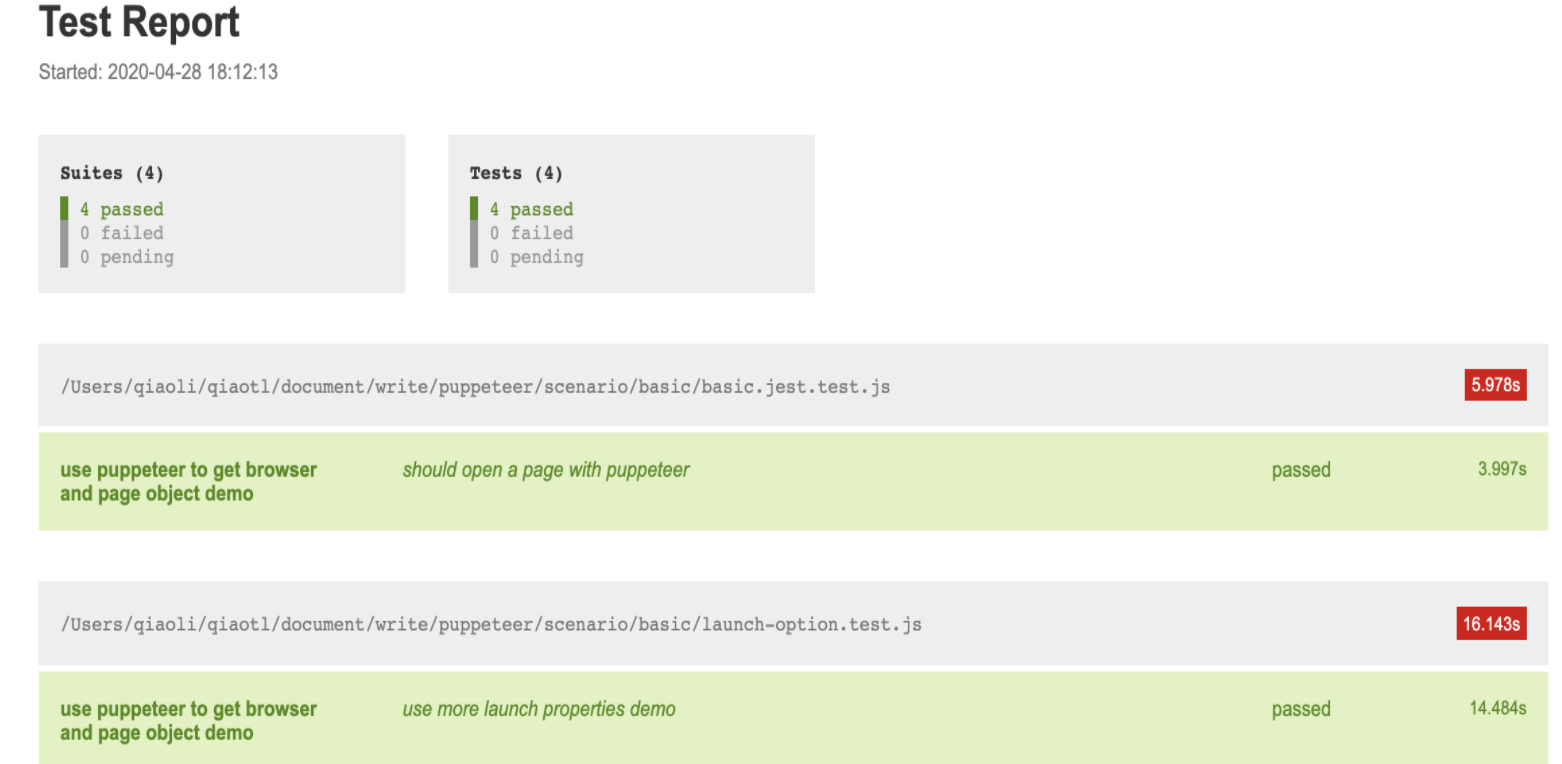
Puppeteer之提高UI层测试可读性
代码被阅读的时间远大于编写的时间,易于阅读、易于维护的代码可以有效降低自动化脚本维护成本。此次课程将学习如何提高UI层自动化脚本的可读性和可维护性。另外,测试代码也需要持续优化,优化的前提是定义期望达到的度量指标并进行持续优化。其中,自动化测试成功率、反馈时间是2个重要的衡量指标。此章节还会介绍如何通过测试报告获取自动化测试成功率、反馈时间。为了完成此次课程目标,拆分了2个task。 如何提高脚

谷歌 Puppeteer 爬虫工具初体验(可用于H5截图预览)
https://segmentfault.com/a/1190000014403160 随着网络的迅速发展,因特网已经成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine) —— 例如传统的通用搜索引擎 Baidu 和 Google等,作为一个辅助人们检索信息的工具成为用户访问因特网的入口和指南。但是,通用性搜索引擎也存在着一定的局限性,如:通
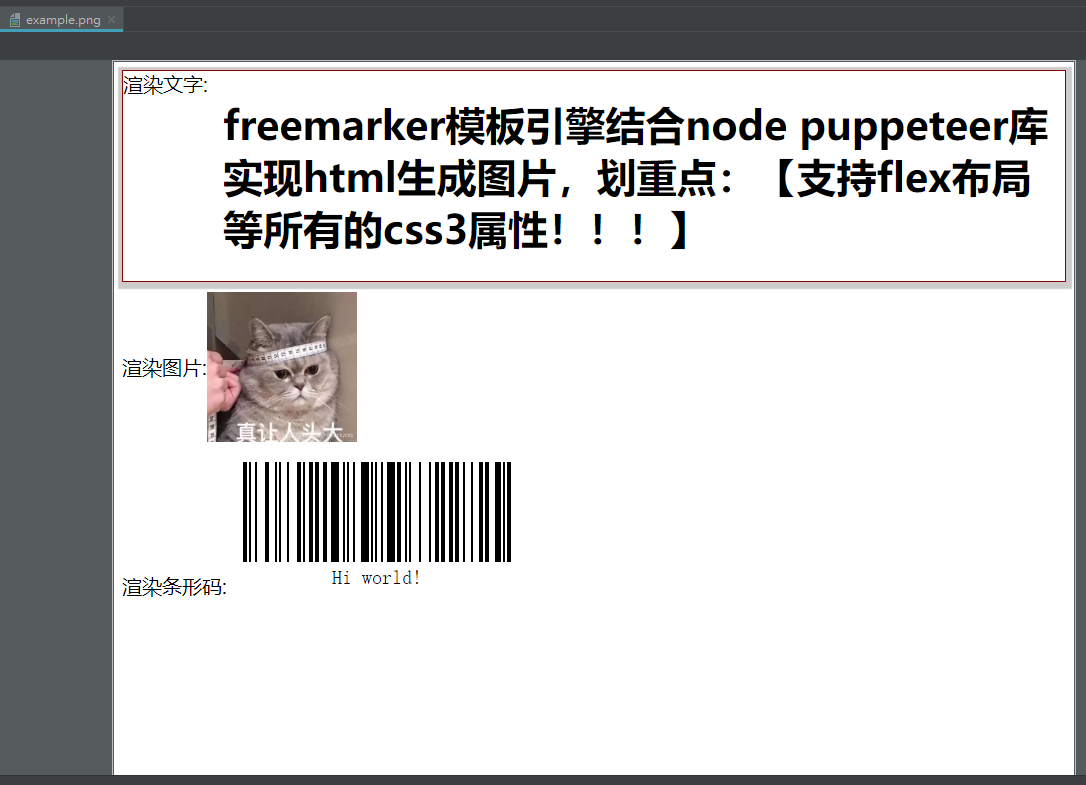
freemarker模板引擎结合node puppeteer库实现html生成图片
效果图: 先看效果图,以下是基于freemarker模板渲染数据,puppeteer加载html中的js及最后图片生成: 背景: 目前为止,后台java根据html模板或者一个网页路径生成图片,都不支持flex布局及最新的css3属性,这其中的库、插件包括:html2image、cssbox、core-renderer、wkhtmltox、Flying Saucer、node插件phanto

puppeteer设置cookie获取网页内容
使用puppeteer进行页面渲染的时候因为要登录才能获取到数据,我们不想走登录流程,想直接把cookie设置好,就需要设置cookies。 按照下面的方式进行设置 const cookies = {url: url,name: '',value: ''};await page.setCookie(cookies);await page.goto(url); 第一个参数是URL,也就是要增加
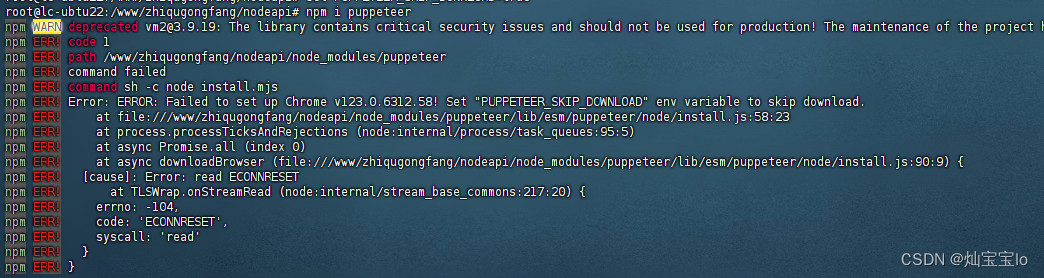
ERROR: Failed to set up Chromium r901912! Set “PUPPETEER_SKIP_DOWNLOAD“ env variable to skip downloa
报错原因 npm install puppeteer的时候报下面这个提示 ERROR: Failed to set up Chromium r901912! Set "PUPPETEER_SKIP_DOWNLOAD" env variable to skip download.{ Error: read ETIMEDOUTat TLSWrap.onStreamRead (internal/s

puppeteer 爬取大众点评
最近在研究node的爬虫框架,这里作为学习的记录,实现通过puppeteer来爬取大众点评的信息 先看一下最终的爬取效果: 首先需要安装puppeteer插件 安装的方法网上一堆,我也不多讲了,给一个我这个实例对应的安装地址(我一直安装失败,看了这个文章之后才可以运行…QAQ) Puppeteer 安装失败的解决办法 这里我额外引入了mysql和request(这个没用到),对应的安装方法:

基于Puppeteer实现配置自动化
前两篇文章《Node.js和Puppeteer进行Web抓取的简单使用》 和《Puppeteer结合Jest对网页进行测试》已经了解到Puppeteer大致可以做点什么事情,之前提到过最终自动化需要一个数组配置。这篇文章将会简单是一个读取配置文件实现自动化的脚本。 脚本 就拿《Node.js和Puppeteer进行Web抓取的简单使用》 代码举例: const puppeteer = req
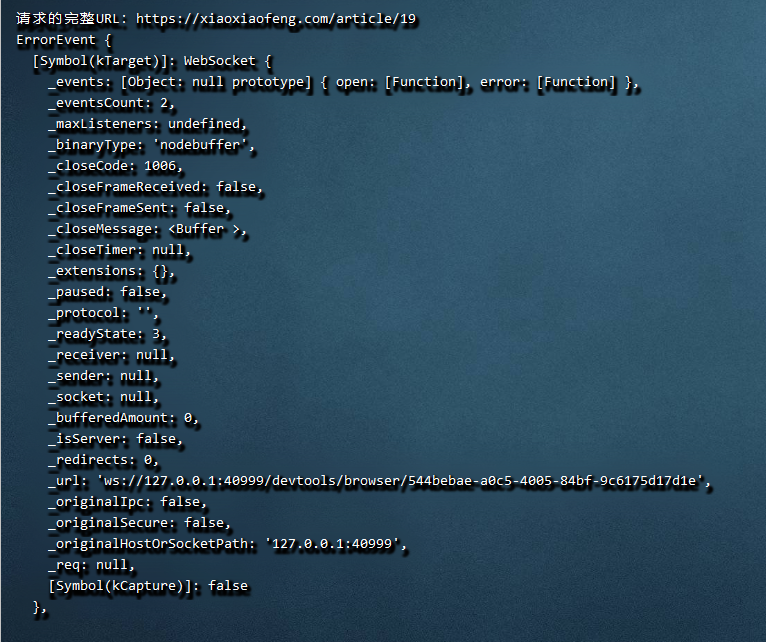
Vue3+Vite使用Puppeteer进行SEO优化(SSR+Meta)
1. 背景 【笑小枫】https://www.xiaoxiaofeng.com上线啦 资源持续整合中,程序员必备网站,快点前往围观吧~ 我的个人博客【笑小枫】又一次版本大升级,虽然知道没有多少访问量,但我还是整天没事瞎折腾。因为一些功能在Halo上不太好实现,所以又切回了Vue3项目,本文就是对于Vue单页面项目SEO优化的一个简单的完整方案。 此次优化的最大好处,就是SSR时对
Node.js和Puppeteer进行Web抓取的简单使用
至此我们大概了解到 node + electron + 谷歌浏览器基本开发知识,现在就可以肝代码了。不要忘记自动化工具主要功能,自动化操作网页。这个时候我们就用到了 Puppeteer 这个库。 Puppeteer的基础 这里的第一步是创建一个新文件夹,其中我们创建一个新的JavaScript文件。通过终端找到你新建的文件夹,并使用下面的行安装Puppeteer包。 npm install
国内下载安装 Puppeteer 的方法
执行 npm install puppeteer 时,有可能会报错,也有可能不会。只要没看到类似: Python Downloading Chromium r609904 - 82.7 Mb [=== ] 16% 990.3s 1 2 Downloading Chromium r609904 - 82.7 Mb [ ===
Puppeteer让你网页操作更简单(2)抓取数据
Puppeteer让你网页操作更简单(1)屏幕截图】 示例2 —— 让我们抓取一些数据 现在您已经了解了Headless Chrome和Puppeteer的工作原理基础知识,让我们看一个更复杂的示例,其中我们实际上可以抓取一些数据。 首先,请查看此处的Puppeteer API文档。如您所见,有大量不同的方法我们可以使用不仅可以在网站上点击,还可以填写表单、输入内容并读取数据。 在本教程中