本文主要是介绍puppeteer 爬取大众点评,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在研究node的爬虫框架,这里作为学习的记录,实现通过puppeteer来爬取大众点评的信息
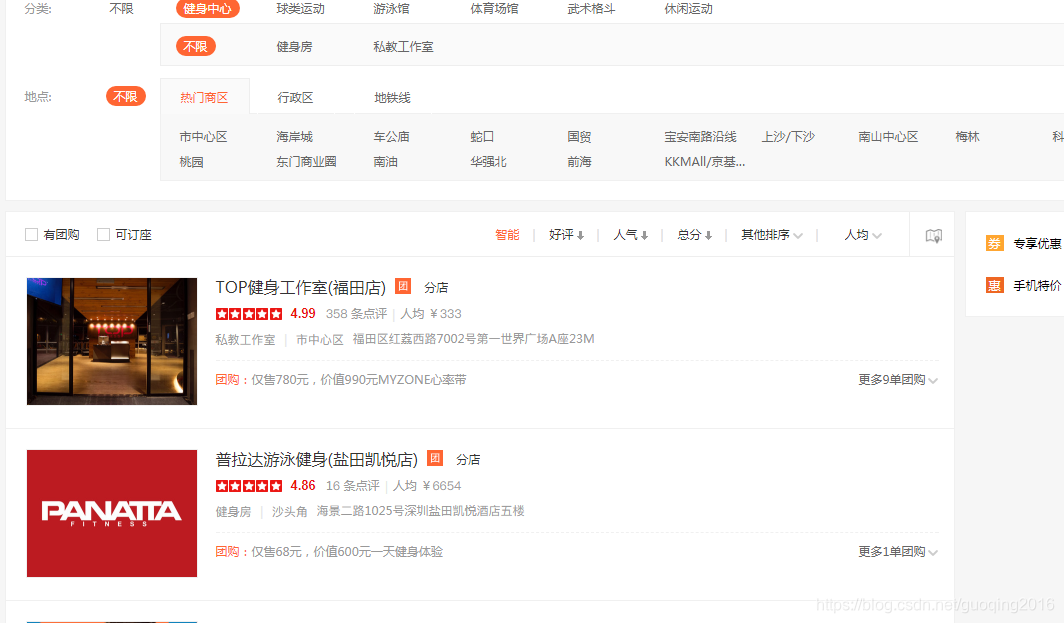
先看一下最终的爬取效果:
首先需要安装puppeteer插件
安装的方法网上一堆,我也不多讲了,给一个我这个实例对应的安装地址(我一直安装失败,看了这个文章之后才可以运行…QAQ)
Puppeteer 安装失败的解决办法
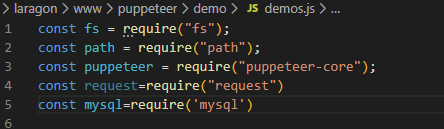
这里我额外引入了mysql和request(这个没用到),对应的安装方法:
npm install mysql request --save
下面我们讲下实现的原理
在爬虫启动浏览器访问大众点评后,有时候会出现一个验证的
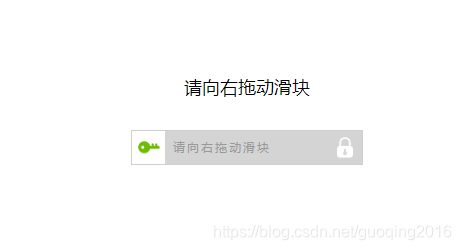
然而我测试的时候,这个验证滑了之后还是不给进去

感觉被检测出是爬虫然后就不给访问的样子,具体什么原因我也不清楚,只是发现
有时候就可以直接进入到页面中,需要多试几次,emmmmmmm,知道具体原因的,可以评论区留言一下,谢谢
进入到页面之后,正常的那种获取文本信息这些应该很容易搞定的,也可以去下载一下我的代码,大部分注释都有写,可以去学习学习,链接地址我会放到最下面
最主要的是大众点评有反爬虫机制,会将文字进行替换
比如:
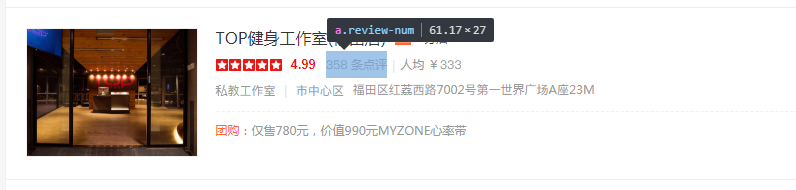
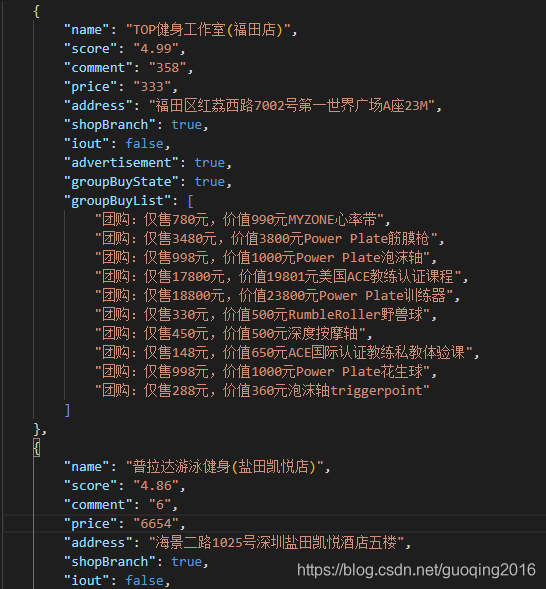
我们来读取一下这个358点评数的信息(F12选的)
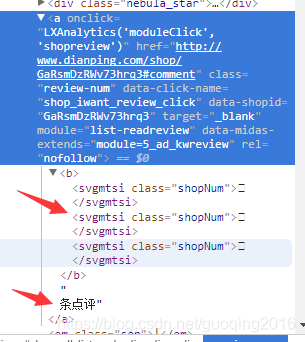
在F12后的审查元素界面,可以看的到 358这三个数字被替换为了<svgmtsi>标签,不仅如此其他一些重要的信息全部被替换为了<svgmtsi>标签,目的就是不让新手爬取…emmmm
博主觉得这个问题可以用两种方法解决:
1、ocr去识别文字
2、解析svg的信息 (博主用的就是这个方法)
因为博主用的是解析信息的方法,下面会具体讲讲
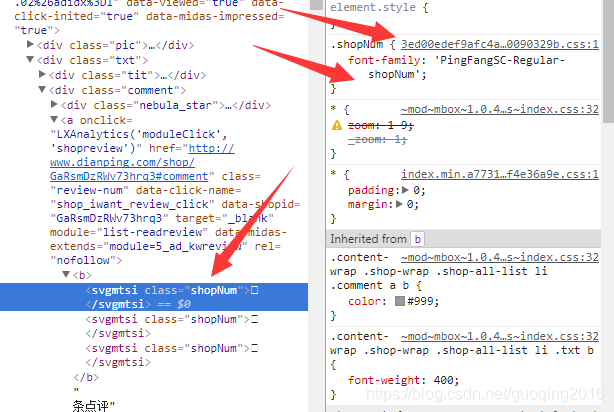
我们选中一个<svgmtsi>只会,可以看到他引用的对应的样式(这里是shopNum),然后鼠标放在样式的地址上,有一个链接,复制链接地址并打开它
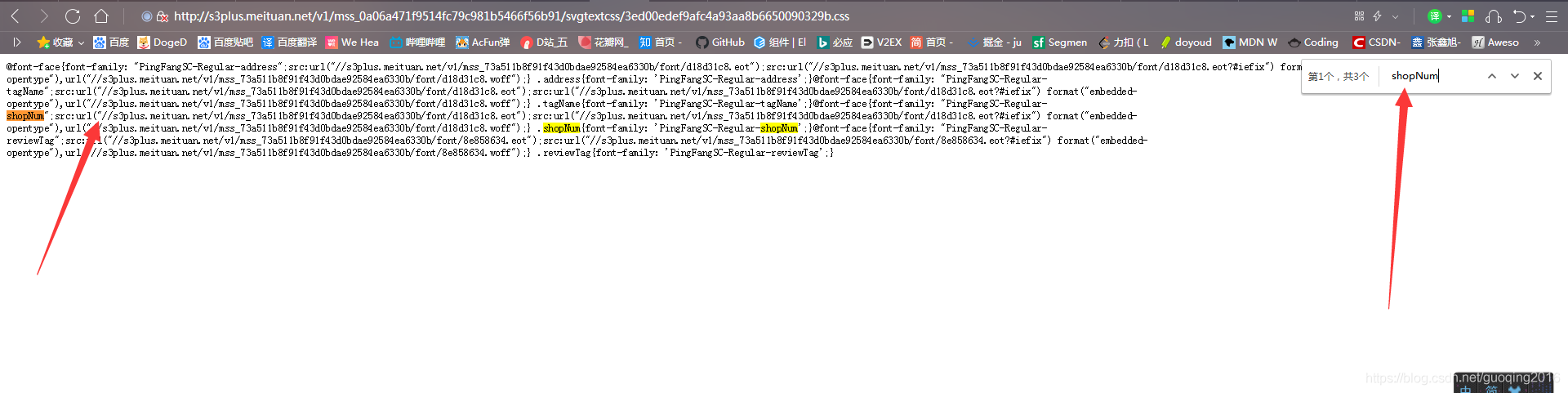
打开之后,大概就是这样的,这时候我们去搜索之前的样式shopNum,然后会有3个匹配值,复制第一个匹配值后面的地址

然后在新页面中打开,就会提示一个下载信息
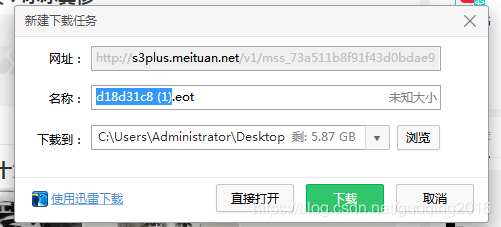
这里下载的信息就是一个文字包,你可能打不开,可以用百度的文字编辑打开
地址为:http://fontstore.baidu.com/static/editor/index.html
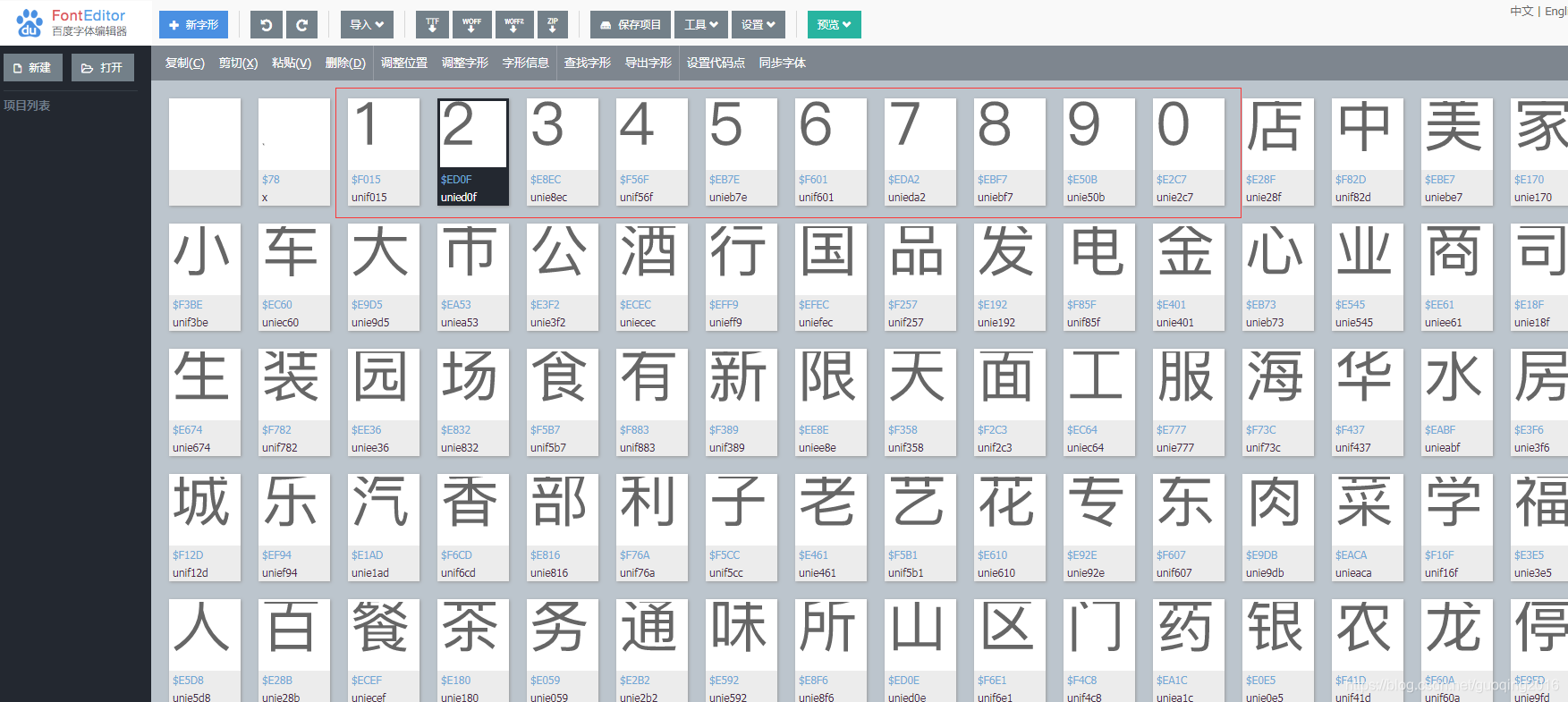
将文件直接拖拽进去也可以打开的,打开之后就是这样的情况,可以看到数字对应的密匙信息吧
来核实一下对不对,比如我去取一下之前358条点评中的数字3(在审查元素中只能看到类似的信息)
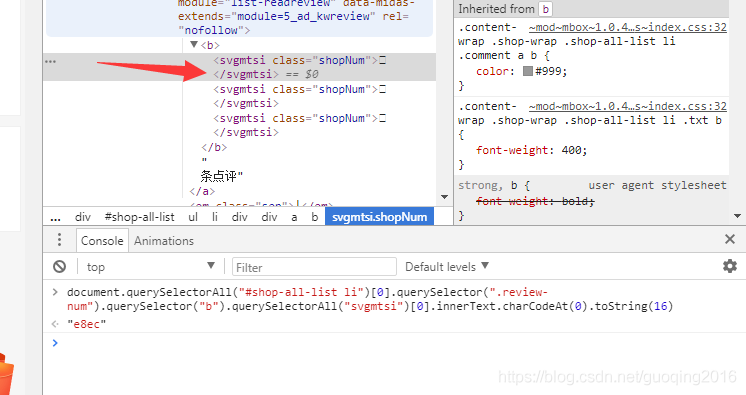
在config里输入:
document.querySelectorAll("#shop-all-list li")[0].querySelector(".review-num").querySelector("b").querySelectorAll("svgmtsi")[0].innerText.charCodeAt(0).toString(16)
获取到对应的e8ec信息
与之前文字库中作对比,可以发现
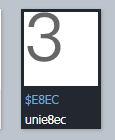
数字3对应的刚好是 unie8ec
因此我们就可以做一个数字匹配的列表来(虽然这个列表是固定的,每次变了规则还要对着的变化,但是可以实现读取信息)
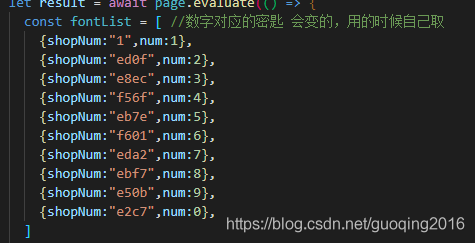
根据获取出来的内容对应着匹配一下数组列表,然后就可以知道真实的数字内容了
(文字的解析方式更复杂,不过也可以用这种方式实现,就是文字太多了…)
对于具体的内容获取,元素选择什么的可以参考下面的api
puppeteer系列教程
官方api
后续的完整代码我会提供链接地址进行下载(推荐去下面的github地址下载,不要积分的,希望拉取的时候可以star一下,谢谢)
完整代码的下载地址
我对于生成的信息存到了数据库以及本地的demo.json中
如果要运行爬虫,可以直接在终端运行 node demos.js
(别告诉你不知道怎么启动。。。百度查查node运行js文件吧)
爬虫运行时的图片

有问题直接留言,我天天看!!!
如果对你有帮助,希望可以去github帮忙点个Star 谢谢了QAQ 你的Star对我十分重要
↓↓↓GitHub地址↓↓↓
快来点一下Stat
这篇关于puppeteer 爬取大众点评的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









