本文主要是介绍GDPU 数据结构 天码行空10,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 数据结构实验十 树遍历应用
- 一、【实验目的】
- 二、【实验内容】
- 三、【实验源代码】
- ⭐ 图解
- ⭐ CPP版
- ⭐ c语言版
- 四、实验结果
数据结构实验十 树遍历应用
一、【实验目的】
1、了解树的建立方法
2、掌握树与二叉树的转化及其遍历的基本方法
3、掌握递归二叉树遍历算法的应用
二、【实验内容】
1.构造一棵药品信息树,树的形态如下图所示,打印出先序遍历、后序遍历的遍历序列。
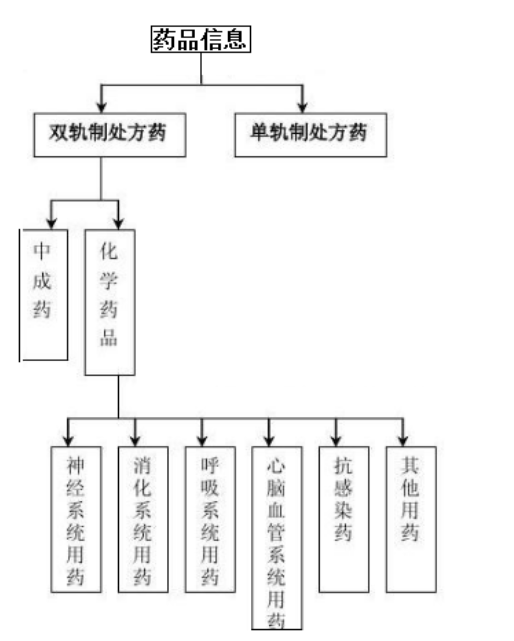
2.编写一个层序遍历算法,利用队列结构按层次(同一层自左至右)输出树中所有的结点。
3.将树结构转化为二叉树,编写二叉树非递归中序遍历算法,并输出遍历序列。
三、【实验源代码】
源码
⭐ 图解
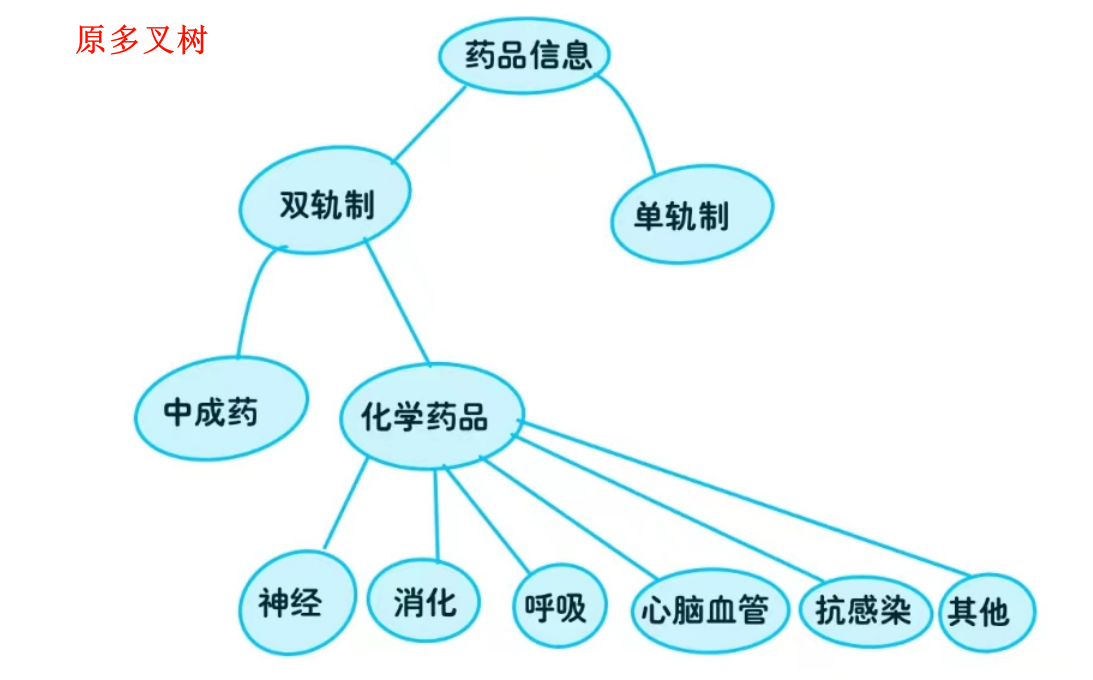
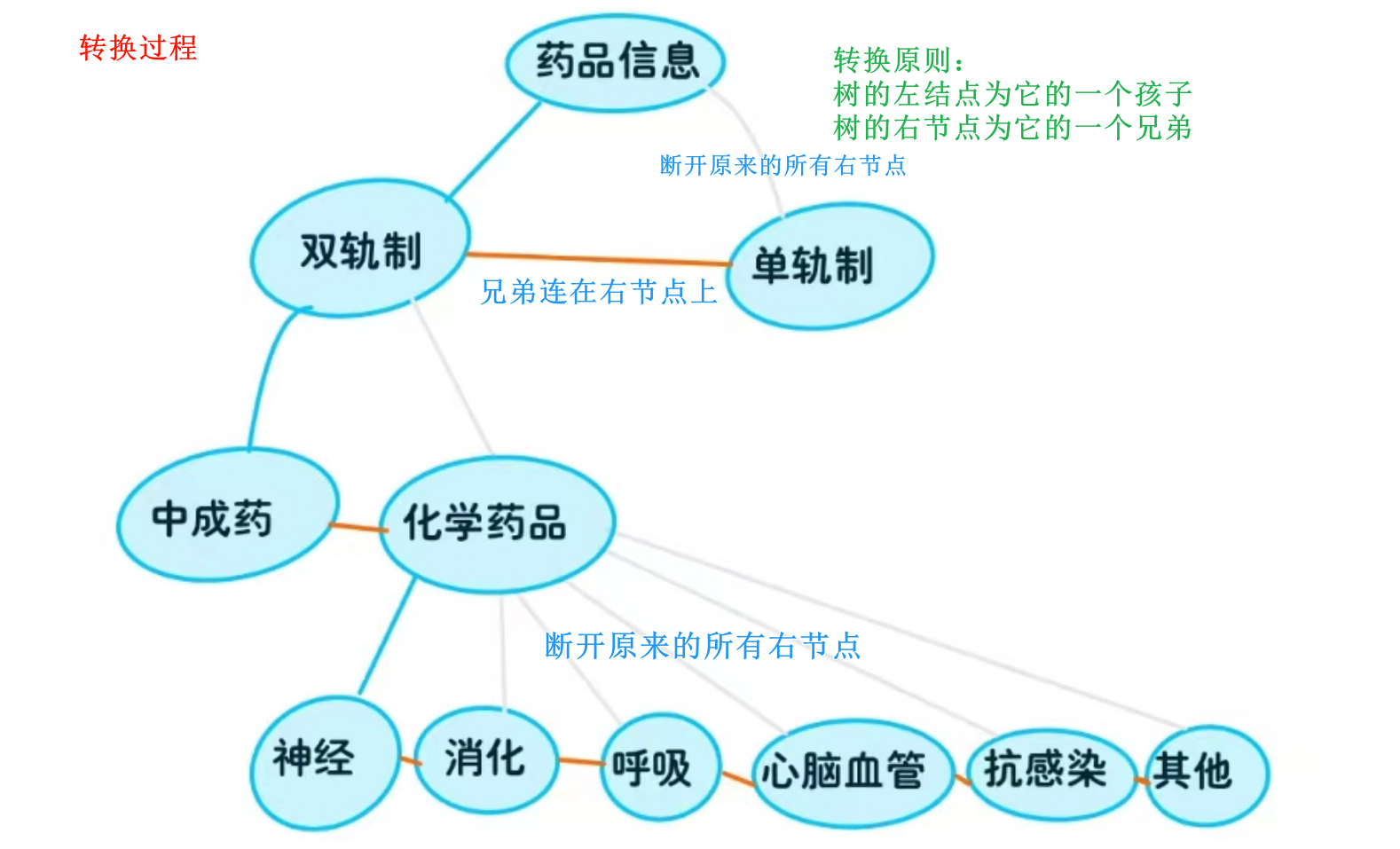
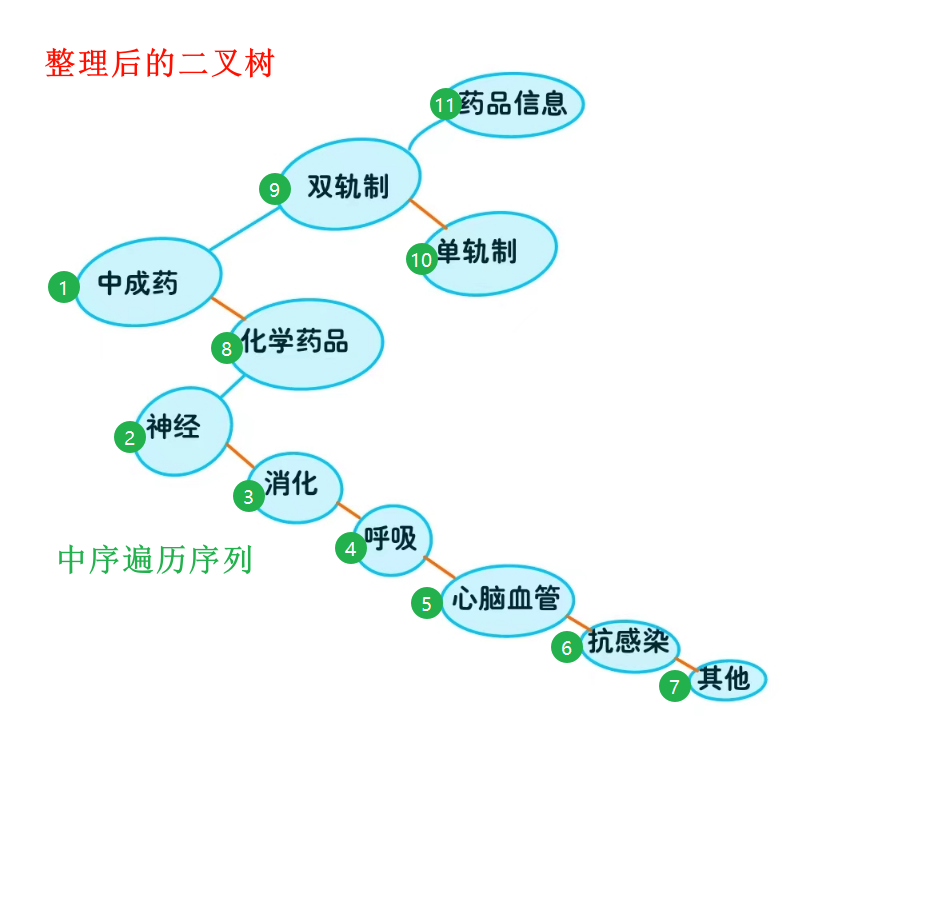
⭐ CPP版
#include <iostream>
#include <queue>
#include <stack>using namespace std;// 多叉树节点
struct Node {string name; // 节点名称vector<Node*> nodes; //子节点指针数组// 构造函数Node(string name, vector<Node*> nodes) : name(name), nodes(nodes) {}
};// 二叉树节点
struct BinaryNode {string name; // 节点名称BinaryNode *left; // 左子节点指针BinaryNode *right; // 右子节点指针
// 构造函数BinaryNode(string name, BinaryNode *left, BinaryNode *right) : name(name), left(left), right(right) {}
};// 按照题意初始化多叉树,返回多叉树的根节点
Node* init() {// 第四层节点Node* n31 = new Node("神经系统用药", {});Node* n32 = new Node("消化系统用药", {});Node* n33 = new Node("呼吸系统用药", {});Node* n34 = new Node("心脑血管系统用药", {});Node* n35 = new Node("抗感染药", {});Node* n36 = new Node("其他用药", {});// 第三层节点vector<Node*> ns1 = {n31, n32, n33, n34, n35, n36};Node* n21 = new Node("中成药", {});Node* n22 = new Node("化学药品", ns1);// 第二层节点vector<Node*> ns2 = {n21, n22};Node* n11 = new Node("双规制处方药", ns2);Node* n12 = new Node("单规制处方药", {});// 第一层节点Node* root = new Node("药品信息", {n11, n12}); // 根节点return root;
}// 队列实现层序遍历(BFS)
void LevelOrderByQueue(Node* root) {queue<Node*> q;q.push(root);cout << "队列实现层序遍历:" << endl;while (!q.empty()) {Node* t = q.front(); // 取出队首节点q.pop(); // 队首节点出队cout << t->name << " "; // 输出节点名称for (Node* node : t->nodes) {q.push(node); // 将子节点加入队列}}
}// 二叉树的非递归遍历(栈)
void InOrder(BinaryNode* root) {stack<BinaryNode*> s;BinaryNode* t = root;cout << endl;cout << "二叉树的中序遍历:" << endl;while (t != nullptr || !s.empty()) {if (t != nullptr) {s.push(t);t = t->left; // 移动到左子节点} else {t = s.top(); // 弹出栈顶节点s.pop();cout << t->name << " "; // 输出节点名称t = t->right; // 移动到右子节点}}
}// 多叉树转二叉树
//root:多叉树的根节点
//broot:二叉树的根节点
void createBinaryTree(Node* root, BinaryNode* broot) {if (root == nullptr)//判空 return;broot->name = root->name; // 转换节点名称vector<Node*> nodes = root->nodes;//nodes存的是当前多叉树的子树if (nodes.empty()) {return;}// 左儿子右兄弟BinaryNode* left = new BinaryNode("", nullptr, nullptr);// 递归构建左子树createBinaryTree(nodes[0], left);BinaryNode* t = left;// t 是当前孩子中最右的孩子for (int i = 1; i < nodes.size(); i++) {Node* node = nodes[i];BinaryNode* right = new BinaryNode(node->name, nullptr, nullptr); // 构建右子树// 递归构建右子树createBinaryTree(nodes[i], right);t->right = right; // 连接右兄弟节点t = right;}broot->left = left; // 连接左子树
}// 多叉树的先序遍历
void preOrder(Node* root) {if (root == nullptr) {return;}cout << root->name << " "; // 输出节点名称for (Node* n : root->nodes) {preOrder(n); // 递归遍历子节点}
}// 多叉树的后序遍历
void postOrder(Node* root) {if (root == nullptr) {return;}for (Node* n : root->nodes) {postOrder(n); // 递归遍历子节点}cout << root->name << " "; // 输出节点名称
}int main() {Node* root = init();// 打印先后序遍历cout << "多叉树的先序遍历:" << endl;preOrder(root); // 先序遍历cout << "\n多叉树的后序遍历:" << endl;postOrder(root); // 后序遍历cout << endl;LevelOrderByQueue(root); // 层序遍历BinaryNode* broot = new BinaryNode("", nullptr, nullptr);createBinaryTree(root, broot); // 多叉树转二叉树InOrder(broot); // 中序遍历二叉树return 0;
}
⭐ c语言版
#include <stdio.h>
#include <stdlib.h>
#include <string.h>struct Node {char* name; // 结点名称struct Node** nodes; // 子结点数组int num_nodes; // 子结点数量
};struct BinaryNode {char* name; // 结点名称struct BinaryNode* left; // 左子结点struct BinaryNode* right; // 右子结点
};// 创建多叉树结点
struct Node* createNode(char* name, struct Node** nodes, int num_nodes) {struct Node* new_node = (struct Node*)malloc(sizeof(struct Node));new_node->name = name;new_node->nodes = nodes;new_node->num_nodes = num_nodes;return new_node;
}// 创建二叉树结点
struct BinaryNode* createBinaryNode(char* name, struct BinaryNode* left, struct BinaryNode* right) {struct BinaryNode* new_node = (struct BinaryNode*)malloc(sizeof(struct BinaryNode));new_node->name = name;new_node->left = left;new_node->right = right;return new_node;
}// 多叉树的层序遍历
void levelOrder(struct Node* root) {struct Node** queue = (struct Node**)malloc(sizeof(struct Node*) * 1000);int front = 0;int rear = 0;queue[rear++] = root;printf("队列实现层序遍历:\n");while (front < rear) {struct Node* temp = queue[front++];printf("%s ", temp->name);for (int i = 0; i < temp->num_nodes; i++) {queue[rear++] = temp->nodes[i];}}printf("\n");
}// 二叉树的中序遍历
void inOrder(struct BinaryNode* root) {struct BinaryNode** stack = (struct BinaryNode**)malloc(sizeof(struct BinaryNode*) * 1000);int top = -1;struct BinaryNode* temp = root;printf("\n二叉树的中序遍历:\n");while (temp != NULL || top != -1) {if (temp != NULL) {stack[++top] = temp;temp = temp->left;}else {temp = stack[top--];printf("%s ", temp->name);temp = temp->right;}}
}// 创建二叉树
void createBinaryTree(struct Node* root, struct BinaryNode* broot) {broot->name = root->name;struct Node** nodes = root->nodes;int num_nodes = root->num_nodes;if (num_nodes == 0) {return;}struct BinaryNode* left = createBinaryNode("", NULL, NULL);createBinaryTree(nodes[0], left);struct BinaryNode* temp = left;for (int i = 1; i < num_nodes; i++) {struct Node* node = nodes[i];struct BinaryNode* right = createBinaryNode(node->name, NULL, NULL);createBinaryTree(nodes[i], right);temp->right = right;temp = right;}broot->left = left;
}// 多叉树的先序遍历
void preOrder(struct Node* root) {if (root == NULL) {return;}printf("%s ", root->name);for (int i = 0; i < root->num_nodes; i++) {preOrder(root->nodes[i]);}
}// 多叉树的后序遍历
void postOrder(struct Node* root) {if (root == NULL) {return;}for (int i = 0; i < root->num_nodes; i++) {postOrder(root->nodes[i]);}printf("%s ", root->name);
}int main() {// 创建多叉树结点struct Node* n31 = createNode("神经系统用药", NULL, 0);struct Node* n32 = createNode("消化系统用药", NULL, 0);struct Node* n33 = createNode("呼吸系统用药", NULL, 0);struct Node* n34 = createNode("心脑血管系统用药", NULL, 0);struct Node* n35 = createNode("抗感染药", NULL, 0);struct Node* n36 = createNode("其他用药", NULL, 0);struct Node* ns1[] = { n31, n32, n33, n34, n35, n36 };struct Node* n21 = createNode("中成药", NULL, 0);struct Node* n22 = createNode("化学药品", ns1, 6);struct Node* ns2[] = { n21, n22 };struct Node* n11 = createNode("双规制处方药", ns2, 2);struct Node* n12 = createNode("单规制处方药", NULL, 0);struct Node* nodes[] = { n11, n12 };struct Node* root = createNode("药品信息", nodes, 2);printf("多叉树的先序遍历:\n");preOrder(root);printf("\n多叉树的后序遍历:\n");postOrder(root);printf("\n");levelOrder(root);// 创建二叉树struct BinaryNode* broot = createBinaryNode("", NULL, NULL);createBinaryTree(root, broot);inOrder(broot);return 0;
}
四、实验结果
多叉树的先序遍历:
药品信息 双规制处方药 中成药 化学药品 神经系统用药 消化系统用药 呼吸系统用药 心脑血管系统用药 抗感染药 其他用药 单规制处方药
多叉树的后序遍历:
中成药 神经系统用药 消化系统用药 呼吸系统用药 心脑血管系统用药 抗感染药 其他用药 化学药品 双规制处方药 单规制处方药 药品信息
队列实现层序遍历:
药品信息 双规制处方药 单规制处方药 中成药 化学药品 神经系统用药 消化系统用药 呼吸系统用药 心脑血管系统用药 抗感染药 其他用药
二叉树的中序遍历:
中成药 神经系统用药 消化系统用药 呼吸系统用药 心脑血管系统用药 抗感染药 其他用药 化学药品 双规制处方药 单规制处方药 药品信息
这篇关于GDPU 数据结构 天码行空10的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







