本文主要是介绍GDPU 数据结构 天码行空9,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验九 哈夫曼编码
一、【实验目的】
1、理解哈夫曼树的基本概念
2、掌握哈夫曼树的构造及数据结构设计
3、掌握哈夫曼编码问题设计和实现
二、【实验内容】
1、假设用于通信的电文仅由8个字母 {a, b, c, d, e, f, g, h} 构成,它们在电文中出现的概率分别为{ 0.07, 0.19, 0.02, 0.06, 0.32, 0.03, 0.21, 0.10 },试为这8个字母设计哈夫曼编码。
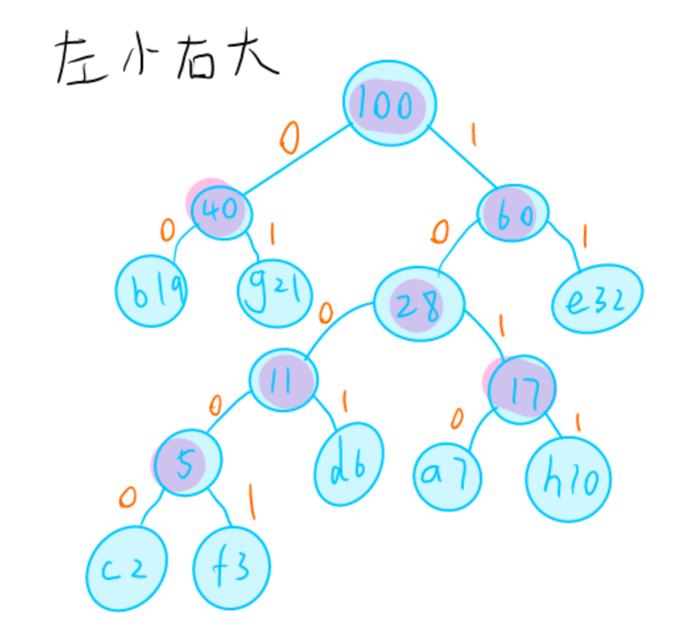
提示:包含两个过程:
(1)构建哈夫曼树
(2)输出编码。
三、【实验源代码】
🍑 优先队列版
#include <iostream>
#include <queue>
#include <map>
using namespace std;// 定义结点结构体
struct Node
{Node *l; // 左孩子结点Node *r; // 右孩子结点int w; // 结点权值char letter; // 字符// 结点构造函数Node(Node* _l, Node* _r, int _w, char _letter){l = _l;r = _r;w = _w;letter = _letter;}// 重载小于运算符bool operator < (const Node& cmp) const {return w > cmp.w;}
};priority_queue<Node> heap; // 定义优先队列用于构建哈夫曼树的堆
map<char, string> hafCode; // 存储哈夫曼编码的映射表// 构建哈夫曼树
Node* build()
{while (heap.size() > 1){// 从堆中取出两个权值最小的结点,合并为一个新的父结点Node* x = new Node(heap.top().l, heap.top().r, heap.top().w, heap.top().letter);heap.pop();Node* y = new Node(heap.top().l, heap.top().r, heap.top().w, heap.top().letter);heap.pop();Node* node = new Node(x, y, x->w + y->w, '!'); // 父结点的字符设为'!'heap.push(*node); // 将新父结点加入堆中}return new Node(heap.top().l, heap.top().r, heap.top().w, heap.top().letter); // 返回哈夫曼树的根结点
}// 递归遍历哈夫曼树,生成哈夫曼编码
void dfs(Node* n, string m)
{if (n->letter != '!'){hafCode.insert(make_pair(n->letter, m)); // 将字符和其对应的哈夫曼编码插入映射表}if (n->l != NULL)dfs(n->l, m + "0"); // 左孩子结点编码为m + "0"if (n->r != NULL)dfs(n->r, m + "1"); // 右孩子结点编码为m + "1"
}// 输出字符的哈夫曼编码
void printHafCode()
{for (char i = 'a'; i <= 'h'; i++)cout << "字母 " << i << " 的哈夫曼码值是: " << hafCode[i] << endl;
}int main()
{// 将初始字符权值放入优先队列中heap.push(Node(NULL, NULL, 7, 'a'));heap.push(Node(NULL, NULL, 19,'b'));heap.push(Node(NULL, NULL, 2, 'c'));heap.push(Node(NULL, NULL, 6, 'd'));heap.push(Node(NULL, NULL, 32,'e'));heap.push(Node(NULL, NULL, 3, 'f'));heap.push(Node(NULL, NULL, 21,'g'));heap.push(Node(NULL, NULL, 10,'h'));Node *root = build(); // 构建哈夫曼树dfs(root, ""); // 生成哈夫曼编码printHafCode(); // 输出哈夫曼编码return 0;
}
🍑 能跑就行
#include <iostream>
using namespace std;
#include <cstdio>
#include <cstring>
typedef struct node { //哈夫曼树中单个节点的信息int parent; //父节点char letter; //字母int lchild;int rchild;double weight; //权值
}*HuffmanTree;
void Select(HuffmanTree& tree, int n, int& s1, int& s2) { //找到权值最小的两个值的下标,其中s1的权值小于s2的权值int min = 0;for (int i = 1; i <= n; i++) {if (tree[i].parent == 0) {min = i;break;}}for (int i = min + 1; i <= n; i++) {if (tree[i].parent == 0 && tree[i].weight < tree[min].weight)min = i;}s1 = min; //找到第一个最小值,并赋给s1for (int i = 1; i <= n; i++) {if (tree[i].parent == 0 && i != s1) {min = i;break;}}for (int i = min + 1; i <= n; i++) {if (tree[i].parent == 0 && i != s1 && tree[i].weight < tree[min].weight)min = i;}s2 = min; //找到第二个最小值,并赋给s2
}
void CreateHuff(HuffmanTree& tree, char* letters, double* weights, int n) {int m = 2 * n - 1; //若给定n个数要求构建哈夫曼树,则构建出来的哈夫曼树的结点总数为2n-1tree = (HuffmanTree)calloc(m + 1, sizeof(node)); //开辟空间顺序储存Huffman树,用calloc开辟的空间初始化的值为0(NULL),符合Huffman树初始化条件(parent、weight、lchild、rchild等初始化应为0),由于tree[0]不存数据(因为任何节点的父节点若为0,会与节点初始化0值相混淆,故不存数据),则要开辟(2n-1)+1个空间(额外开辟一个空间)for (int i = 1; i <= n; i++) { //给节点赋字母及其对应的权值tree[i].weight = weights[i - 1];tree[i].letter = letters[i];}for (int i = n + 1; i <= m; i++) {int s1 = 0, s2 = 0;Select(tree, i - 1, s1, s2); //每次循环选择权值最小的s1和s2,生成它们的父结点tree[i].weight = tree[s1].weight + tree[s2].weight; //新创建的节点i 的权重是s1和s2的权重之和tree[i].lchild = s1; //新创建的节点i 的左孩子是s1tree[i].rchild = s2; //新创建的节点i 的右孩子是s2tree[s1].parent = i; //s1的父亲是新创建的节点itree[s2].parent = i; //s2的父亲是新创建的节点i}
}
void HuffmanCoding(HuffmanTree& tree, char**& HuffCode, int n) {HuffCode = (char**)malloc(sizeof(char*) * (n + 1)); //运用char型二级指针,可理解成包含多个char*地址的数组,开n+1个空间,因为下标为0的空间不用char* tempcode = (char*)malloc(sizeof(char) * n);tempcode[n - 1] = '\0';for (int i = 1; i <= n; i++) {int start = n - 1;int doing = i; //doing为正在编码的数据节点int parent = tree[doing].parent; //找到该节点的父结点while (parent) { //直到父结点为0(NULL),即父结点为根结点时停止if (tree[parent].lchild == doing) //如果该结点是其父结点的左孩子,则编码为0,否则为1tempcode[--start] = '0';elsetempcode[--start] = '1';doing = parent; //继续往上进行编码parent = tree[parent].parent;}HuffCode[i] = (char*)malloc(sizeof(char) * (n - start)); //开辟用于存储编码的内存空间strcpy(HuffCode[i], &tempcode[start]); //将编码拷贝到字符指针数组中的相应位置}free(tempcode); //释放辅助空间
}
int main() {int n = 8;char letters[9] = {' ','a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'};double weights[9] = {0.07, 0.19, 0.02, 0.06, 0.32, 0.03, 0.21, 0.10};HuffmanTree tree;CreateHuff(tree, letters, weights, n); //构建哈夫曼树char** HuffCode;HuffmanCoding(tree, HuffCode, n);for (int i = 1; i <= n; i++)printf("字母 %c 的哈夫曼编码值是: %s\n", tree[i].letter, HuffCode[i]);return 0;
}
👨🏫 参考资料
这篇关于GDPU 数据结构 天码行空9的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







