本文主要是介绍【飞桨】【PaddlePaddle】【论文复现】StarGAN v2论文及其前置:GAN、CGAN、pix2pix、CycleGAN、pix2pixHD、StarGAN学习心得,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- GAN
- CGAN
- pix2pix
- CycleGAN
- pix2pixHD
- StarGAN
PaddlePaddle: 百度顶会论文复现营.
GAN
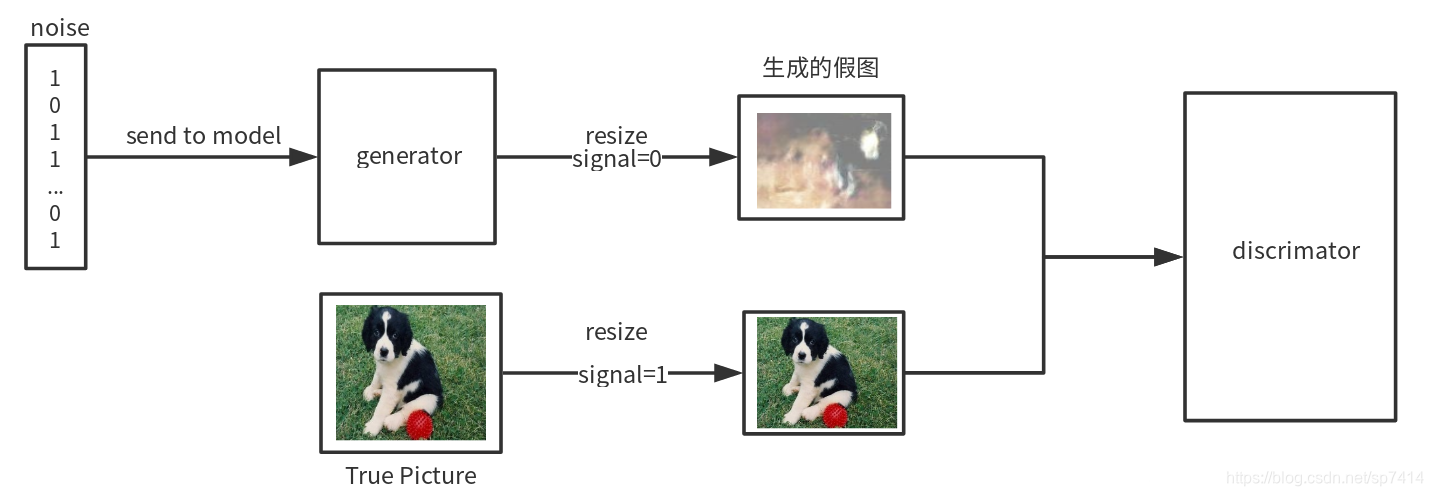
GAN,即生成对抗网络,其网络结构主要包含一个生成器G和一个判别器D。首先,一个n维噪声输入到模型中,由生成器生成一个fake图像(根据目标而定),接着传入真实图像,resize成与fake图像相同大小,共同输入到判别器D中,送入训练网络中,训练趋势是使生成器生成越来越逼真,可以“以假乱真”的假图像,而判别器的精度也不断提升,最后,判别器D无法区分生成器G生辰的fake图像,得到的真假图像概率为0.5,达到理想状态。经过这样的一种“抗衡”生成器G的图像生成能力越来越强,整个网络的目的也就达到了。
CGAN
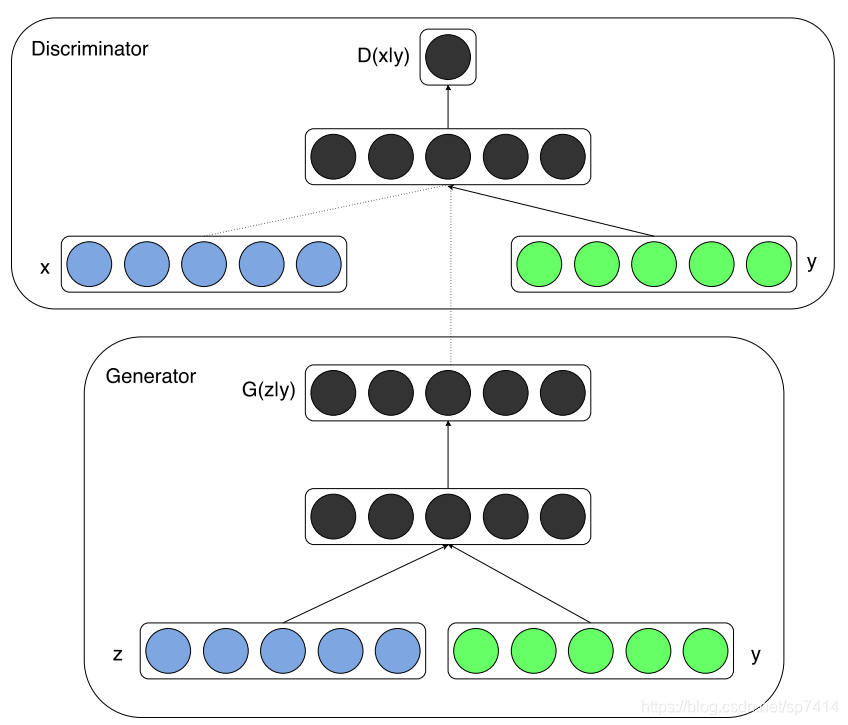
CGAN(条件生成对抗网络)主要针对GAN的随机性问题,在生成器和判别器中都加入了一个标签作为输入,从它的损失函数中可以看出,D和G的概率表达都变成了条件概率,这样,对于不同的标签y,就有不同的函数表达,从而可以完成特定的任务。
pix2pix
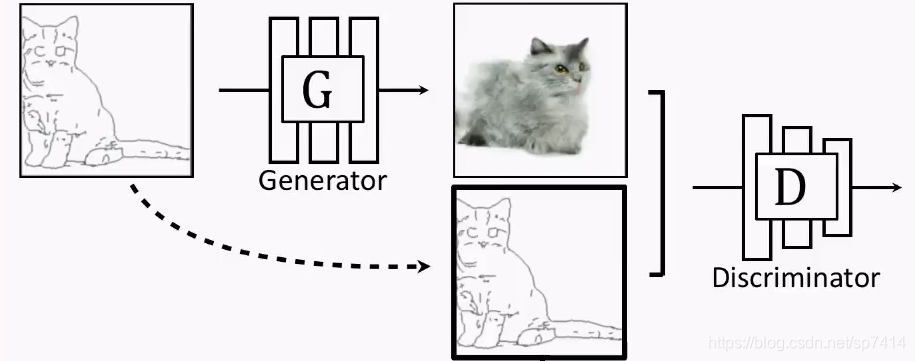
Pix2pix主要的核心思想是“对应关系”,以草图代替噪声作为输入,由生成器生成一个图片,再将草图和G生成的图片共同作为D的输入,这样就可以把草图变成相应的图片了。
这里附上一个有趣的小链接:https://affinelayer.com/pixsrv/,可以把自己绘制的草图转化成猫咪。
CycleGAN
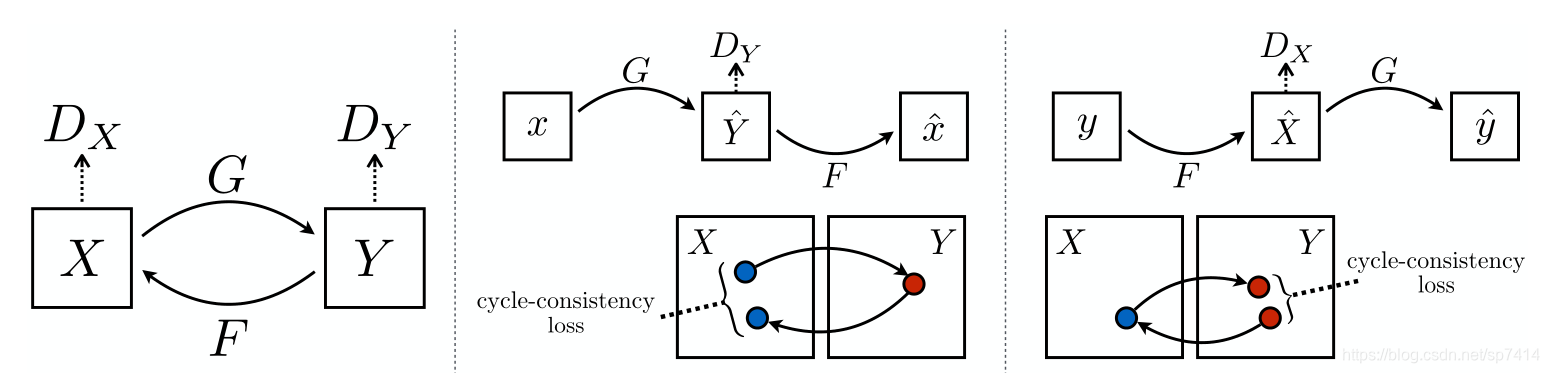
尽管pix2pix的图像生成效果较好,但它的限制是必须要用成对的数据进行训练。草图转化为仿真图还比较容易,但涉及到灰度变换、自动着色等方面时,往往没有那么多成对的数据供使用,所以为了解决这个限制所带来的问题,CycleGAN应运而生。以把马变成斑马的CycleGAN网络为例,它只需要一些马的图像和一些斑马的图像就可以了,不需要成对数据。但为了防止网络随机输出,需要在此基础上加上限制,即一个马的图像经过G变成斑马图像,那么还需要增加一个F,使得这个斑马图像经过F还可以变回原来的马的图像。同样的,一个斑马图像也要经过G—F变换再变回原来的斑马图像。CycleGAN的核心在于分离了“风格”和“内容”,使得网络变换可以保持目标内容而改变风格。
pix2pixHD
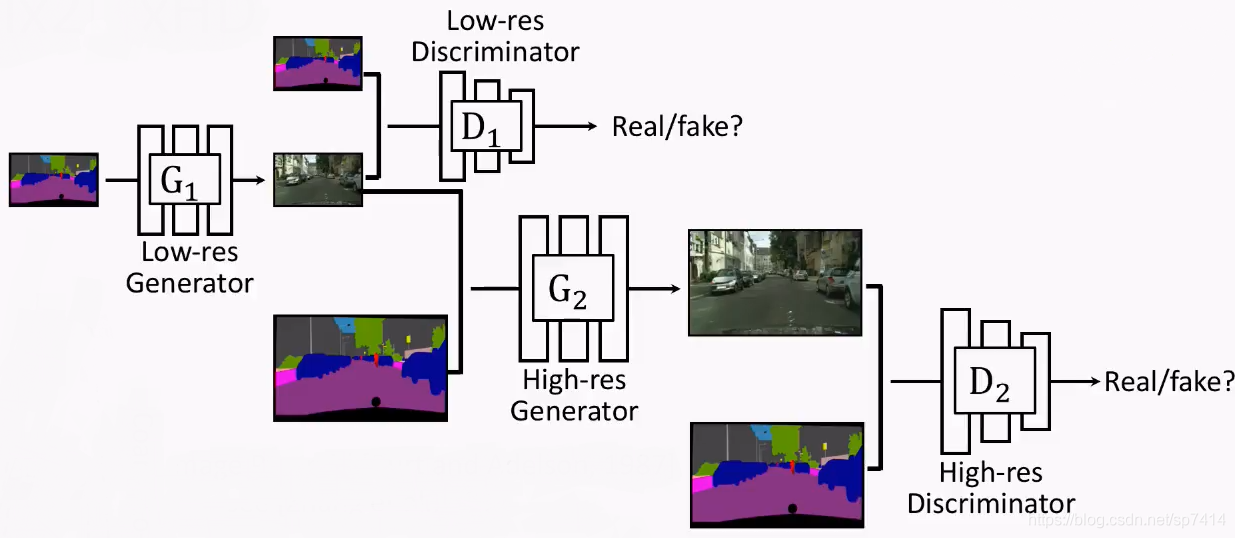
上面提到的CycleGAN有一个比较严重的缺陷,即它只能生成低分辨率的图像。为了得到高分辨率的图像,pix2pixHD网络采用以生成的低分辨率图像作为输入,在一个新的G中生成更高分辨率的方法成功地提升了生成图像的分辨率。
StarGAN

接下来是阅读本篇论文的重点内容,即StarGAN v1、v2。
Pix2pix和CycleGAN在解决一对一的图像转换方面效果显著,但当有多个领域需要转换时,他它们往往需要重新对新的模型进行训练,不仅非常耗时,而且泛化能力较低。StarGAN主要目的在于解决多对多的图像翻译问题。它独特的星型结构使得其只需要一个生成器G和一个判别器D就可以完成图像翻译工作。StarGAN的网络训练过程大致如下:(1)D对真假图片进行判别,并把真实图片分类到对应域中;(2)真图片和目标域标签共同作为输入进入G,生成假图片;(3)G根据所给的原始域标签在假图片的基础上对原始图片进行重构;(4)G最后生成几乎无法让D与真实图片区分开的图像,并且使D可以按照目标域对图像进行分类。总结来看,StarGAN加入了“域”的概念,并且标签的作用更明显了。
再来说说我对于StarGAN v2的理解。StarGAN v2原始论文的标题为:针对多个域的多样化图像合成。它的目标有两个,1.生成图像样化;2.在多个域上具有可扩展性。与第一代网络不同的是,StarGAN v2引入了两个新的概念:风格迁移(AdaIN)和人脸对齐(用于生成heatmap)和两个新的模块:映射网络(mapping network)和样式编码器(style encoder),StarGAN v2的网络结构也就变成了:G—映射网络—样式编码器—D。
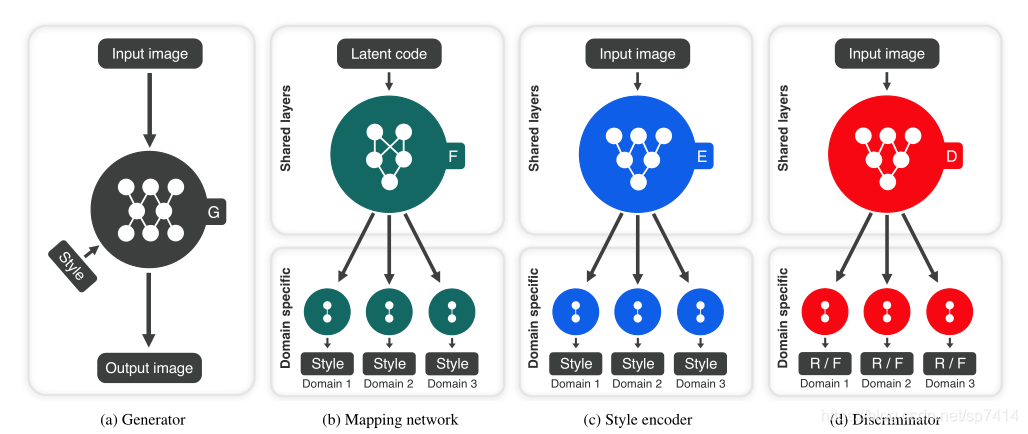
在生成器G中,StarGAN v2的生成器删除了上采样中所有的跳跃连接,以基于人脸对齐产生的heatmap进行替代,这样可以对人脸信息进行充分的保留。映射网络包含k个输出分支,表示有k个域,在给定噪声和相应的域标签时,它就会生成相应的样式码,映射网络主要由全连接层构成,最后输出一个大小为64位的样式码。样式编码器作用和映射网络一样,都是生成样式码,不同的是样式编码器要通过给定的图像和对应域来提取样式码。它主要采用下采样的方式,最后输出一个D(样式码维度)×K维的向量。判别器D包括k个输出分支,表示有k个域,且每个分支都学习一个二元分类,确定图像x是域y的真实图像还是G生成的fake图像,因此D的输出维度设定为1,作为真/假的分类。
最后,从真实图像与生成图像之间的差异性与生成图像的多样性两个指标进行分析,StarGAN v2与其他同类型的方法相比,图像生成效果最好。从人的喜爱偏好角度分析,StarGAN v2生成的图像也是最真实、自然的,最被人所接受的。看看StarGAN v2生成的图像吧,是不是很真实,真实得可怕~

部分图片及文章思路源自下面的几篇文章,侵删。
1.CGAN(条件生成-对抗网络)简述教程.
2.starGAN 论文学习.
3.CycleGan论文笔记.
4.一文读懂GAN, pix2pix, CycleGAN和pix2pixHD.
5.GAN网络详解(从零入门).
这篇关于【飞桨】【PaddlePaddle】【论文复现】StarGAN v2论文及其前置:GAN、CGAN、pix2pix、CycleGAN、pix2pixHD、StarGAN学习心得的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

