本文主要是介绍YOLO-----关于正负样本、Loss、IOU、怎样去平衡正负样本的问题?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于正负样本、Loss、IOU、怎样去平衡正负样本的问题
- 1、关于正负样本
- 2、Loss计算
- 3、IOU、GIOU、DIOU、CIOU
- 4、怎样去平衡正负样本的问题?
先整理一下anchor的概念
常用的anchor定义
----Faster R-CNN 定义三组纵横比ratio = [0.5,1,2]和三种尺度scale = [8,16,32],可以组合处9种不同的形状和大小的边框。
----YOLO则不是使用预设的纵横比和尺度的组合,而是使用k-means聚类的方法,从训练集中学习得到不同的Anchor
yolov3中输入图片大小为416 × 416 × 3,分别经过32倍、16倍、8倍下采样,得到三层特征图,13 × 13 × 255、 26 × 26 × 255、 52 ×52 × 255。
每张特征图上会提前设定3个anchor box。即yolov3中一共9个anchor box。
13 ×13的特征图感受野最大,使用大的anchor(116x90),(156x198),(373x326),
26 × 26特征图使用中等的anchor box (30x61),(62x45),(59x119),适合检测中等大小的目标。
52 × 52特征图感受野最小,使用最小的anchor box(10x13),(16x30),(33x23),适合检测较小的目标。
这些anchor的大小是对于原图像(416× 416)来说的。Anchor的作用是来回归出预测框,当我们标记的ground truth 与anchor 相交时,挑选出IOU最大值所对应的anchor,用这个anchor来回归预测框。
1、关于正负样本
loss计算中,“负责预测目标”(即正样本)和背景(即负样本),以及不参与计算loss的部分是怎么选择的:
正样本的选择:
如果Ground Truth的中心点落在一个区域中,该区域就负责检测该物体。然后计算这个grid的9个先验框(anchor)和目标真实位置的IOU值(直接计算,不考虑二者的中心位置),取IOU值最大的先验框和目标匹配。
于是,找到的该grid(网格)中的该anchor负责预测这个目标,其余的网格、anchor都不负责。将与该物体有最大IoU的预测框作为正样本(注意这里没有用到ignore thresh,即使该最大IoU<ignore thresh也不会影响该预测框为正样本)
负样本的选择:
YOLOv3中有一个参数是ignore_thresh,在ultralytics版版的YOLOv3中对应的是train.py文件中的iou_t参数(默认为0.225)。
如果一个预测框与所有的Ground Truth的最大IoU<ignore_thresh时,那这个预测框就是负样本**(再次提醒:即使该最大IoU<ignore thresh也不会影响该预测框为正样本)**
注意:不参与计算部分就是最大IOU没有超过阈值ignore_thresh的一部分
计算各个先验框和所有的目标ground truth之间的IOU,如果某先验框和图像中所有物体最大的IOU都小于阈值(一般0.5),那么就认为该先验框不含目标,记作负样本,其置信度应当为0
最大IOU没有超过阈值ignore_thresh的一部分虽然不负责预测对象,但IOU较大,可以认为包含了目标的一部分,不可简单当作负样本,所以这部分不参与误差计算。

2、Loss计算
在YOLOv3中,Loss分为三个部分:
1、一个是x、y、w、h部分带来的误差,也就是bbox带来的loss
2、一个是置信度带来的误差,也就是obj带来的loss
3、最后一个是类别带来的误差,也就是class带来的loss
在代码中分别对应lbox, lobj, lcls,yolov3中使用的loss公式如下: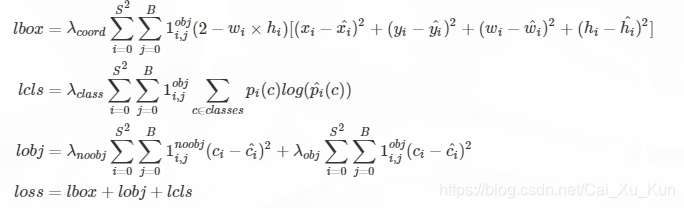
其中:
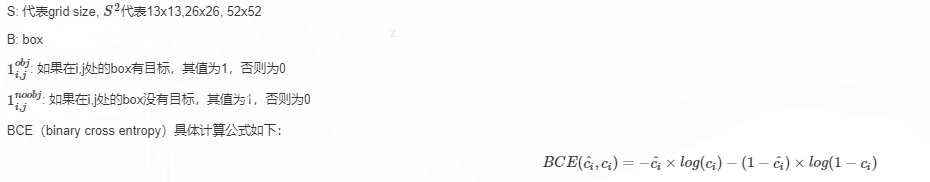
box loss:1–IOU/1-GIOU/1-DIOU/1-CIOU
cls loss:
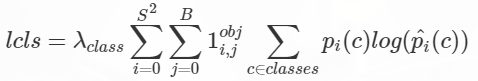
obj:
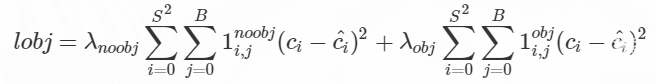
关于BCE、MSE、Focal loss(类别cls)要整理一次。
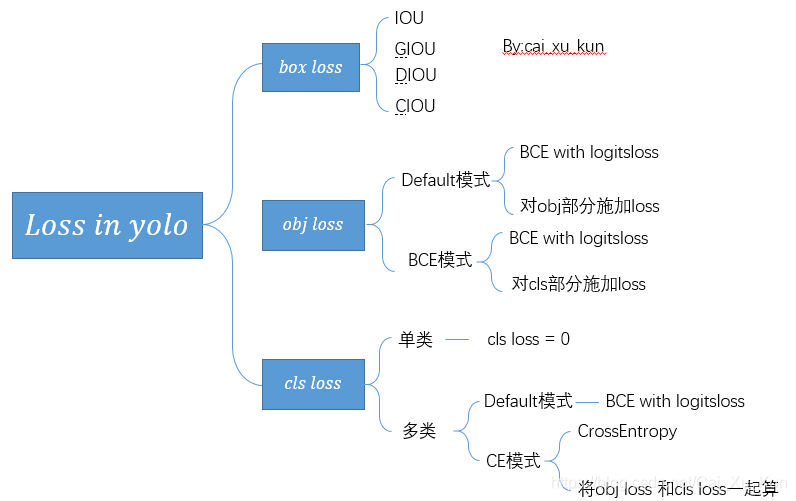
3、IOU、GIOU、DIOU、CIOU
IOU:
对于检测框B和groundtruth G,IOU公式如下:
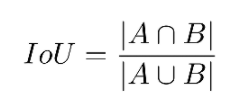
那么IoU Loss即为1-IoU。
显然IoU Loss具有非负性、尺度不变性、同一性、对称性、三角不等性等特点,所以可以用于bounding box的回归任务中。
但同时,IoU Loss也存在一个很致命的缺点:
当B与G的IoU为0时,Loss也为0,网络无法进行训练。因此IoU loss在回归任务中的表现并不好。
IOU实现代码:
import numpy as np
def Iou(box1, box2, wh=False):if wh == False:xmin1, ymin1, xmax1, ymax1 = box1xmin2, ymin2, xmax2, ymax2 = box2else:xmin1, ymin1 = int(box1[0]-box1[2]/2.0), int(box1[1]-box1[3]/2.0)xmax1, ymax1 = int(box1[0]+box1[2]/2.0), int(box1[1]+box1[3]/2.0)xmin2, ymin2 = int(box2[0]-box2[2]/2.0), int(box2[1]-box2[3]/2.0)xmax2, ymax2 = int(box2[0]+box2[2]/2.0), int(box2[1]+box2[3]/2.0)# 获取矩形框交集对应的左上角和右下角的坐标(intersection)xx1 = np.max([xmin1, xmin2])yy1 = np.max([ymin1, ymin2])xx2 = np.min([xmax1, xmax2])yy2 = np.min([ymax1, ymax2]) # 计算两个矩形框面积area1 = (xmax1-xmin1) * (ymax1-ymin1) area2 = (xmax2-xmin2) * (ymax2-ymin2)inter_area = (np.max([0, xx2-xx1])) * (np.max([0, yy2-yy1])) #计算交集面积iou = inter_area / (area1+area2-inter_area+1e-6) #计算交并比return iou
2. 作为损失函数会出现的问题(缺点)
如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重合度)。同时因为loss=0,没有梯度回传,无法进行学习训练。
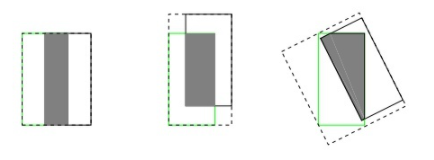
IoU无法精确的反映两者的重合度大小。如下图所示,三种情况IoU都相等,但看得出来他们的重合度是不一样的,左边的图回归的效果最好,右边的最差。
GIOU:
由于IoU是比值的概念,对目标物体的scale是不敏感的。然而检测任务中的BBox的回归损失(MSE loss, l1-smooth loss等)优化和IoU优化不是完全等价的,而且 Ln 范数对物体的scale也比较敏感,IoU无法直接优化没有重叠的部分。
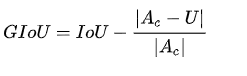
上面公式的意思是:先计算两个框的最小闭包区域面积 [公式] (通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
box loss = 1 -GIOUS
特性
1、*与IoU相似,GIoU也是一种距离度量,作为损失函数的话, [公式] ,满足损失函数的基本要求
2、GIoU对scale不敏感
3、*GIoU是IoU的下界,在两个框无限重合的情况下,IoU=GIoU=1
4、*IoU取值[0,1],但GIoU有对称区间,取值范围[-1,1]。在两者重合的时候取最大值1,在两者无交集且无限远的时候取最小值-1,因此GIoU是一个非常好的距离度量指标。与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
实现代码:
def Giou(rec1,rec2):#分别是第一个矩形左右上下的坐标x1,x2,y1,y2 = rec1 x3,x4,y3,y4 = rec2iou = Iou(rec1,rec2)area_C = (max(x1,x2,x3,x4)-min(x1,x2,x3,x4))*(max(y1,y2,y3,y4)-min(y1,y2,y3,y4))area_1 = (x2-x1)*(y1-y2)area_2 = (x4-x3)*(y3-y4)sum_area = area_1 + area_2w1 = x2 - x1 #第一个矩形的宽w2 = x4 - x3 #第二个矩形的宽h1 = y1 - y2h2 = y3 - y4W = min(x1,x2,x3,x4)+w1+w2-max(x1,x2,x3,x4) #交叉部分的宽H = min(y1,y2,y3,y4)+h1+h2-max(y1,y2,y3,y4) #交叉部分的高Area = W*H #交叉的面积add_area = sum_area - Area #两矩形并集的面积end_area = (area_C - add_area)/area_C #闭包区域中不属于两个框的区域占闭包区域的比重giou = iou - end_areareturn giou
DIOU:
1、来源
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。
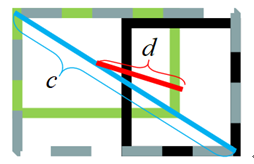
基于IoU和GIoU存在的问题,作者提出了两个问题:
1、 直接最小化anchor框与目标框之间的归一化距离是否可行,以达到更快的收敛速度?
2、如何使回归在与目标框有重叠甚至包含时更准确、更快?
![[公式]](https://img-blog.csdnimg.cn/20210415214555835.png)
分子是预测框和真实框的中心点的欧氏距离, 分母是包含预测框和真实框的最小区域的对角线距离。
DIoU中对anchor框和目标框之间的归一化距离进行了建模
2、优点
预测框和真实框的重叠程度。并且考虑到预测框长和宽的比值问题并以此添加惩罚项,从而使预测框的效果更加稳定
实现代码:
def Diou(bboxes1, bboxes2):rows = bboxes1.shape[0]cols = bboxes2.shape[0]dious = torch.zeros((rows, cols))if rows * cols == 0:#return diousexchange = Falseif bboxes1.shape[0] > bboxes2.shape[0]:bboxes1, bboxes2 = bboxes2, bboxes1dious = torch.zeros((cols, rows))exchange = True# #xmin,ymin,xmax,ymax->[:,0],[:,1],[:,2],[:,3]w1 = bboxes1[:, 2] - bboxes1[:, 0]h1 = bboxes1[:, 3] - bboxes1[:, 1] w2 = bboxes2[:, 2] - bboxes2[:, 0]h2 = bboxes2[:, 3] - bboxes2[:, 1]area1 = w1 * h1area2 = w2 * h2center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2 center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2 center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:]) inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2]) out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:]) out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)inter_area = inter[:, 0] * inter[:, 1]inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2outer = torch.clamp((out_max_xy - out_min_xy), min=0)outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)union = area1+area2-inter_areadious = inter_area / union - (inter_diag) / outer_diagdious = torch.clamp(dious,min=-1.0,max = 1.0)if exchange:dious = dious.Treturn dious
CIOU:

实现代码:
def bbox_overlaps_ciou(bboxes1, bboxes2):rows = bboxes1.shape[0]cols = bboxes2.shape[0]cious = torch.zeros((rows, cols))if rows * cols == 0:return ciousexchange = Falseif bboxes1.shape[0] > bboxes2.shape[0]:bboxes1, bboxes2 = bboxes2, bboxes1cious = torch.zeros((cols, rows))exchange = Truew1 = bboxes1[:, 2] - bboxes1[:, 0]h1 = bboxes1[:, 3] - bboxes1[:, 1]w2 = bboxes2[:, 2] - bboxes2[:, 0]h2 = bboxes2[:, 3] - bboxes2[:, 1]area1 = w1 * h1area2 = w2 * h2center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:])inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2])out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:])out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)inter_area = inter[:, 0] * inter[:, 1]inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2outer = torch.clamp((out_max_xy - out_min_xy), min=0)outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)union = area1+area2-inter_areau = (inter_diag) / outer_diagiou = inter_area / unionwith torch.no_grad():arctan = torch.atan(w2 / h2) - torch.atan(w1 / h1)v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(w2 / h2) - torch.atan(w1 / h1)), 2)S = 1 - ioualpha = v / (S + v)w_temp = 2 * w1ar = (8 / (math.pi ** 2)) * arctan * ((w1 - w_temp) * h1)cious = iou - (u + alpha * ar)cious = torch.clamp(cious,min=-1.0,max = 1.0)if exchange:cious = cious.Treturn cious
4、怎样去平衡正负样本的问题?
可参考链接:
https://blog.csdn.net/qq_14845119/article/details/78930091.
https://www.cnblogs.com/wmx24/p/9676120.html.
https://zhuanlan.zhihu.com/p/30252501.
大概几种解决方案
1.调整训练集的正负样本比例,
2. 过采样
对训练集里面样本数量较少的类别(少数类)进行过采样,合成新的样本来缓解类不平衡。
一种经典的过采样算法:SMOTE。
3. 欠采样
对训练集里面样本数量较多的类别(多数类)进行欠采样,抛弃一些样本来缓解类不平衡。
4.focal loss等等
博客参考:
感谢!
https://www.cnblogs.com/pprp/p/12590801.html.
https://www.cnblogs.com/pprp/p/12590801.html.
https://zhuanlan.zhihu.com/p/94799295.
https://blog.csdn.net/weixin_46269983/article/details/107637613.
这篇关于YOLO-----关于正负样本、Loss、IOU、怎样去平衡正负样本的问题?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







