本文主要是介绍【博士每天一篇论文-综述】Deep Echo State Network (DeepESN)_ A Brief Survey,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阅读时间:2023-11-22
1 介绍
年份:2017
作者:C. Gallicchio 比萨大学计算机科学系终身教授助理教授,A. Micheli,比萨大学计算机科学系
期刊: ArXiv
引用量:68
这是两个大牛的论文,两位作者也是在2017到2018年期间发表了多篇ESN的研究。该文概述了DeepESN(深度回声状态网络)在开发、分析和应用方面的进展。DeepESN是一种专门用于处理时间数据的深度递归神经网络(RNN)。它是Echo State Network(ESN)模型的延伸,ESN模型是一种设计高效训练的RNN的先进方法。DeepESN利用堆叠的递归层的分层组合来开发时间信息的多个时间尺度表示。
这篇论文讨论了DeepESN的属性和动力学,以及其优点和缺点。它还探讨了层叠在RNN架构设计中的作用及其对网络动力学的影响。作者回答了与堆叠层次的好处、RNN层叠的架构效果以及使用有效训练的储备计算(RC)方法设计深度递归模型的潜力有关的一些基本问题。
2 创新点
- DeepESN模型的引入和层次结构:论文介绍了DeepESN模型的基本特征,即它是一种深度循环神经网络,通过堆叠多个递归层来表示时间信息的多个时间尺度。这种层次结构使得DeepESN能够更有效地处理时间数据。
- 网络层叠对RNN的影响:论文通过实证调查和实验分析,揭示了层叠层对于DeepESN模型中的时间数据表示具有积极影响。层叠层的设计不仅有助于实现多时间尺度表示,还提高了未监督的储层自适应和网络设计的效果。
- DeepESN在时间数据处理方面的优势:论文指出,DeepESN模型能够将Echo State Network (ESN)方法的优势扩展到深度递归结构中,为处理时间数据提供了一种高效的方法。DeepESN在预测任务、记忆能力任务和多频率分类任务等合成数据和真实世界问题中取得了比浅层Reservoir架构更好的性能。
- 深度递归模型在结构化领域中的应用:论文还介绍了DeepESN模型在结构化数据领域的扩展,如Deep Tree Echo State Network (DeepTESN) 和 Graph Neural Networks (FDGNNs)。这些模型在处理树形和图形数据方面取得了很好的结果,并超过了传统方法的性能。
这些创新点表明DeepESN模型在处理时间数据以及结构化数据方面具有潜力,并且相比传统的储层网络结构有一定的优势。
3 相关研究
- 深度残差脉动神经网络(DeepESN)模型通过层级嵌套的储备池结构,实现了多时间尺度的时间信息表示。它通过实证研究分析了层级嵌套储备池的效果,并展示了层级嵌套对未监督储备池自适应的增强效果。参考文献:[25]、[26]。
- 对线性激活函数的深度ESN状态进行了频率分析,并发现在深度ESN的状态中存在多重频率表示。即使在简化的线性设置下,逐层深入的储备池将越高层次越关注于越低的频率。研究还表明,在多重叠振荡器(MSO)任务上,深度ESN在预测性实验中比现有研究成果提高了数个数量级。参考文献:[39]。
- 将回声状态性质(ESP)的基本RC条件推广到深度RC网络的情况。通过对嵌套动态系统的稳定性和收敛性的研究,提出了深度RNN体系结构中回声状态性质成立的充分条件和必要条件。这项工作为DeepESN的定义、有效性和使用提供了重要的概念和实用工具。参考文献:[36]。
- 深度树回声状态网络(Deep Tree Echo State Network, DeepTESN)模型是用于结构化领域学习的深度RC框架的扩展。它结合了深度学习、树学习和RC训练效率。DeepTESN已被证明在文档处理和计算生物学的挑战性任务中具有优势,超过了以前最先进的结果。该模型扩展了水库操作,实现了离散树形结构上的状态转换系统,并为树形结构数据提供了Echo state Property的泛化。是设计深度神经网络用于分层结构数据学习的有效方法。参考文献[45,46]。
- 深度RC方法也有利于图数据的学习,导致快速和深度图神经网络(fdgnn)的发展。在[48]中引入了在离散图结构上运行的油藏的概念,并且可以使用图嵌入稳定性(GES)特性来研究由此产生的动力学的稳定性,fdgnn在图分类任务中显示了最先进的准确性,并且比文献模型更快,在训练时间上提供了显着的加速。参考文献[47][48]。
- DeepESN在合成任务中表现优于浅层油藏架构,如macky - glass下一步预测任务、短期记忆容量任务、MSO任务和基于频率的分类任务,在现实世界的应用中也很有效,如环境辅助生活、医疗诊断、语音和音乐处理、气象预报、能源预测、交通预测和金融市场预测。参考文献[25,27,39,44,49][50-60]。
参考文献:
[25] C. Gallicchio, A. Micheli, L. Pedrelli, Deep reservoir computing: A critical experimental analysis
[26] C. Gallicchio, A. Micheli, Deep reservoir computing: A critical analysis, in: Proceedings of the 24th European Symposium on Artificial Neural Networks (ESANN)
[27] C. Gallicchio, A. Micheli, Why layering in Recurrent Neural Networks? a DeepESN survey, in: Proceedings of the 2018 IEEE International Joint Conference on Neural Networks (IJCNN),
[36]C. Gallicchio, A. Micheli, Echo state property of deep reservoir computing networks., Cognitive Computation
[39] C. Gallicchio, A. Micheli, L. Pedrelli, Hierarchical temporal representation in linear reservoir computing, in: A. Esposito, M. Faundez-Zanuy, F. C. Morabito, E. Pasero (Eds.),
[44] C. Gallicchio, A. Micheli, L. Pedrelli, Design of Deep Echo State Networks, Neural Networks 108 (2018) 33–47.
[45] C. Gallicchio, A. Micheli, Deep Reservoir Neural Networks for Trees, Information Sciences 480 (2019) 174–193.
[46] C. Gallicchio, A. Micheli, Deep Tree Echo State Networks, in: Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), IEEE, 2018, pp. 499–506.
[47] C. Gallicchio, A. Micheli, Fast and deep graph neural networks., in: Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), 2020, pp. 3898–3905.
[48] C. Gallicchio, A. Micheli, Graph echo state networks, in: The 2010 International Joint Conference on Neural Networks (IJCNN), IEEE, 2010, pp. 1–8.
[49] C. Gallicchio, Short-term Memory of Deep RNN, in: Proceedings of the 26th European Symposium on Artificial Neural Networks (ESANN), 2018, pp. 633–638.
[50] C. Gallicchio, A. Micheli, Experimental analysis of deep echo state networks for ambient assisted living, in: Proceedings of the 3rd Workshop on Artificial Intelligence for Ambient Assisted Living (AIAAL 2017), colocated with the 16th International Conference of the Italian Association for Artificial Intelligence (AIIA 2017), 2017.
[51] C. Gallicchio, A. Micheli, L.Pedrelli, Deep Echo State Networks for Diagnosis of Parkinson’s Disease, in: Proceedings of the 26th European Symposium on Artificial Neural Networks (ESANN), 2018, pp. 397–402.
[52]C. Gallicchio, A. Micheli, L. Pedrelli, Comparison between DeepESNs and gated RNNs on multivariate time-series prediction, in: 27th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2019), i6doc. com publication, 2019.
4 算法
介绍了一种深度回声状态网络(Deep Echo State Network,DeepESN)模型。与标准的浅层ESN模型类似,DeepESN由动态储备组件和前馈读出部分组成。储备组件将输入历史嵌入到丰富的状态表示中,并利用储备提供的状态编码计算输出。深度ESN的储备被组织成一个堆叠的循环层的层次结构,在每个时间步骤中,状态计算从第一层开始,直到储备架构中的最高层。每个层的输出作为下一层的输入。该模型可以被视为一个输入驱动的离散时间非线性动力系统,其中全局状态的演化由状态转移函数F决定。每个层的状态动态由F控制。通过使用漏积分器储备单元,并忽略偏差项,论文给出了DeepESN储备的数学描述。与浅层ESN/RNN相比,DeepESN的储备架构被限制在图中所示的三种连接约束条件下,这些约束条件对信息流和状态动力学产生影响。深度ESN架构可以被看作是对相应的单层ESN的简化,降低了绝对数量的循环权重。然而,这种特殊的架构组织方式影响了时间信息的处理。
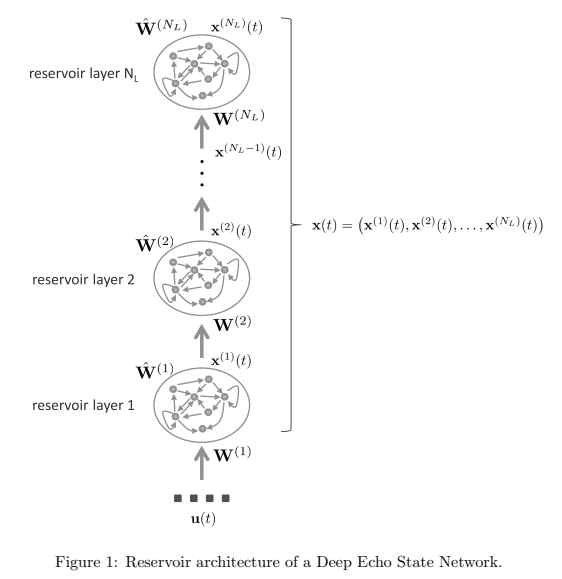
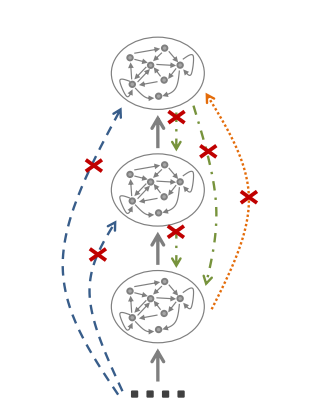
Deep Echo State Network(DeepESN)的分层储备器架构。与浅层ESN/RNN相比,DeepESN的储备器架构被解释为具有相同总循环单元数量的标准浅层ESN/RNN的受限版本。包含几个约束,以获得分层架构。首先,所有从输入层到高于第1层的储备器层的连接都被删除(影响逐渐远离输入层的循环单元逐渐感知到外部输入信息的方式)。其次,所有来自较高层的连接到较低层的连接也被删除(这会影响信息的流动和网络状态的子部分的动态)。这些约束使DeepESN与浅层ESN/RNN相比具有不同的结构特点,并提供了一种层次化组成的储备器架构。
5 代码
https://github.com/lucasburger/pyRC?utm_source=catalyzex.com
6 思考
注意这篇开头提到的两位作者是ESN储层计算的大神,在这篇论文中就引用了自己的21篇相关论文。建议根据相关研究总结的论文,跟读研究一下。根据谷歌学术发表的论文可以看到,作者对于ESN的研究跨度是从2010年到2020年。
有源码的论文,可以复现和在这些基础上做进一步的改进。
这篇关于【博士每天一篇论文-综述】Deep Echo State Network (DeepESN)_ A Brief Survey的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







