本文主要是介绍【论文阅读】Augmented Transformer network for MRI brain tumor segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Zhang M, Liu D, Sun Q, et al. Augmented transformer network for MRI brain tumor segmentation[J]. Journal of King Saud University-Computer and Information Sciences, 2024: 101917. [开源]
IF 6.9 SCIE JCI 1.58 Q1 计算机科学2区
【核心思想】
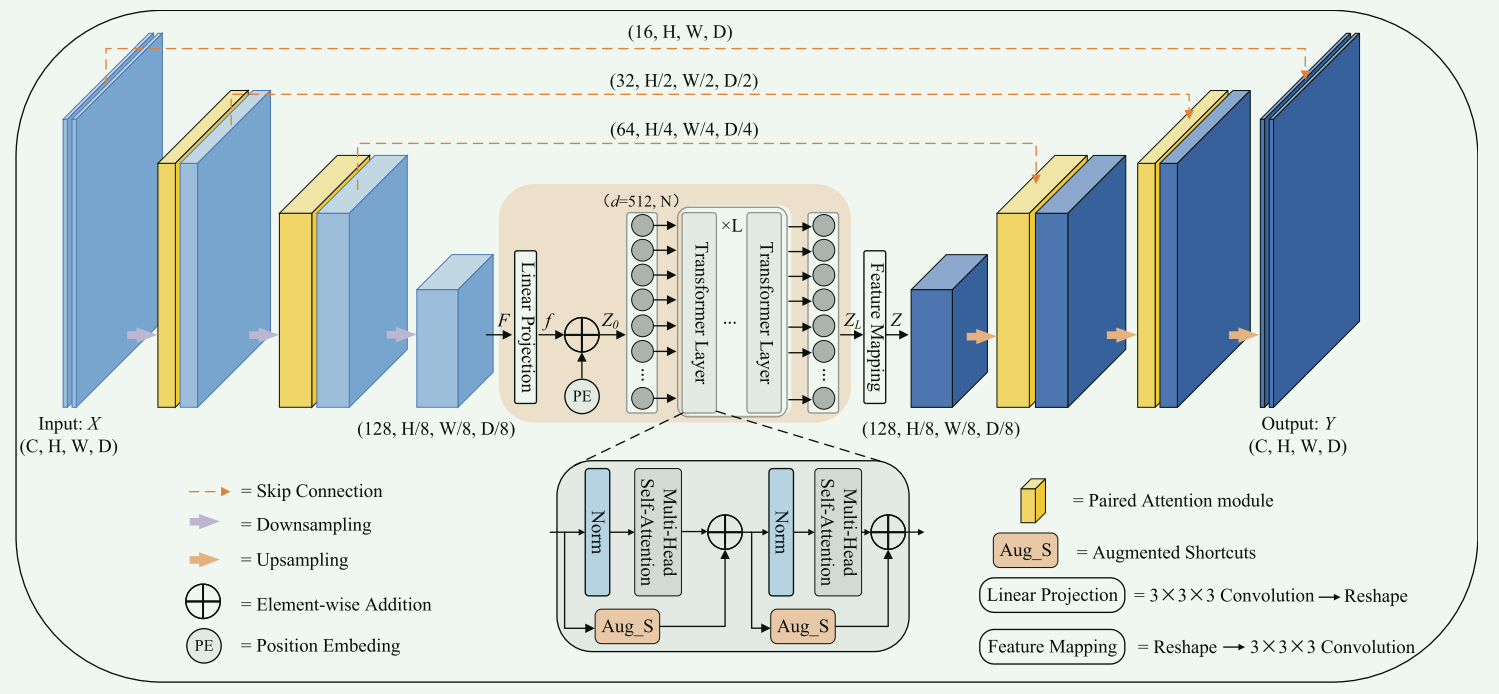
本文提出了一种新型的MRI脑肿瘤分割方法,称为增强型transformer 网络(AugTransU-Net),旨在解决现有transformer 相关的U-Net模型在捕获长程依赖和全局背景方面的局限性。本文的创新之处在于构建了改进的增强型transformer 模块,这些模块结合了标准transformer 块中的增强短路(Augmented Shortcuts),被策略性地放置在分割网络的瓶颈处,以保持特征多样性并增强特征交互和多样性。
【方法】
-
架构设计:AugTransU-Net利用层次化的3D U-Net作为骨干网络,引入了配对注意力模块(paired attention modules)到编码器和解码器层,同时利用改进的transformer 层通过增强短路(Augmented Shortcuts)在瓶颈处。
-
特征增强:通过增强短路(Augmented Shortcuts),可以在多头自注意力块中增加额外的分支,以保持特征多样性和增强特征表示。传统的Shortcuts连接只是将输入特征复制到输出,这限制了其增强特征多样性的能力。具有增强Shortcuts方式的 Transformer 模型已被用来避免特征崩溃并产生更多样化的特征。增强短路的公式为:
Aug − S = ∑ i = 1 T T l i ( Z l ; θ l i ) , l ∈ [ 1 , 2 , … , L ] \operatorname{Aug}_{-} S=\sum_{i=1}^{T} T_{l i}\left(Z_{l} ; \theta_{l i}\right), l \in[1,2, \ldots, L] Aug−S=∑i=1TTli(Zl;θli),l∈[1,2,…,L],
其中 T l i T_{li} Tli:这表示第 l l l层的第 i i i个Transformer 模块。每个Transformer 模块都在处理输入特征,并且可能有其自己的参数和结构。 T l i T_{li} Tli由线性层和激活函数实现。由于投影 T l i T_{li} Tli 的不同权重矩阵 θ l i \theta_{l i} θli 将输入特征翻译到不同的特征空间中,更多并行的 T T T 增强短路方式有助于丰富特征空间并增强特征的多样性以获得更高的性能。
Z l Z_l Zl:这是第 l l l层的输入特征。在Transformer 模型中,每一层都会接收到来自前一层的特征作为输入。
θ l i \theta_{li} θli:这些是第 l l l层第 i i i个Transformer 模块的参数。这些参数在模型训练过程中学习和优化。
这个公式描述了如何在每一层中通过累加所有Transformer 模块的输出来计算增强短路的输出。这样的设计允许网络在每一层中捕获和融合更加丰富和多样化的特征,有助于提高模型的性能和鲁棒性
但如果按照上面的公式计算,需要计算很多矩阵乘法,特别是在并行使用更多增强短路时,需要在 Z l Z_l Zl和 θ l i \theta_{li} θli 之间计算大量的矩阵乘法。受到循环矩阵(Dietrich 和 Newsam, 1997; Kra 和 Simanca, 2012)在傅里叶域上通过快速傅里叶变换(FFT)的效率和有效性的启发,循环矩阵和向量之间的乘积带来了较小的计算复杂度 O ( C ′ log C ′ ) \mathcal{O}\left(C^{\prime} \log C^{\prime}\right) O(C′logC′),其中 C ′ C^{\prime} C′ 是循环矩阵的维数。根据 Tang et al. (2021), θ \theta θ 扮演循环矩阵的角色, T ( Z ; θ ) T(Z ; \theta) T(Z;θ) 通过以下方式实现: T ( Z ; θ ) m = ∑ n = 1 N Z n C m n = ∑ n = 1 N IFFT ( F F T ( Z n ) ) ∘ F F T ( c m n ) T(Z ; \theta)^{m}=\sum_{n=1}^{N} Z^{n} C^{m n}=\sum_{n=1}^{N} \operatorname{IFFT}\left(F F T\left(Z^{n}\right)\right) \circ F F T\left(\mathbf{c}^{m n}\right) T(Z;θ)m=∑n=1NZnCmn=∑n=1NIFFT(FFT(Zn))∘FFT(cmn)
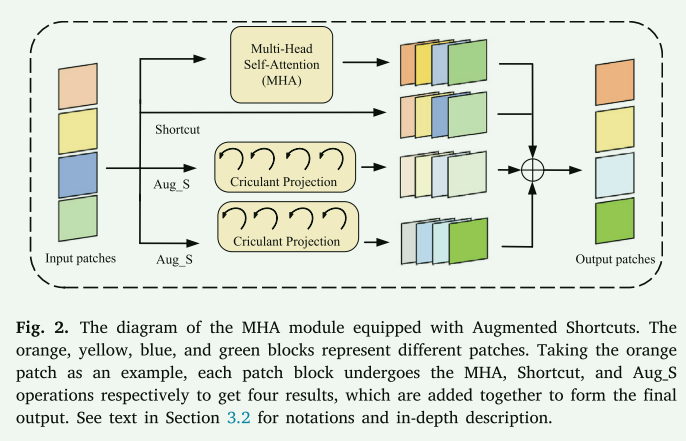
通过利用FFT和IFFT,我们可以以一种计算效率更高的方式实现复杂的线性变换。
-
配对注意力模块:这些模块在网络的低层至高层之间操作,建立空间和通道维度中的长程关系,从而使每一层都能理解整体脑肿瘤结构,并在关键位置捕获语义信息。
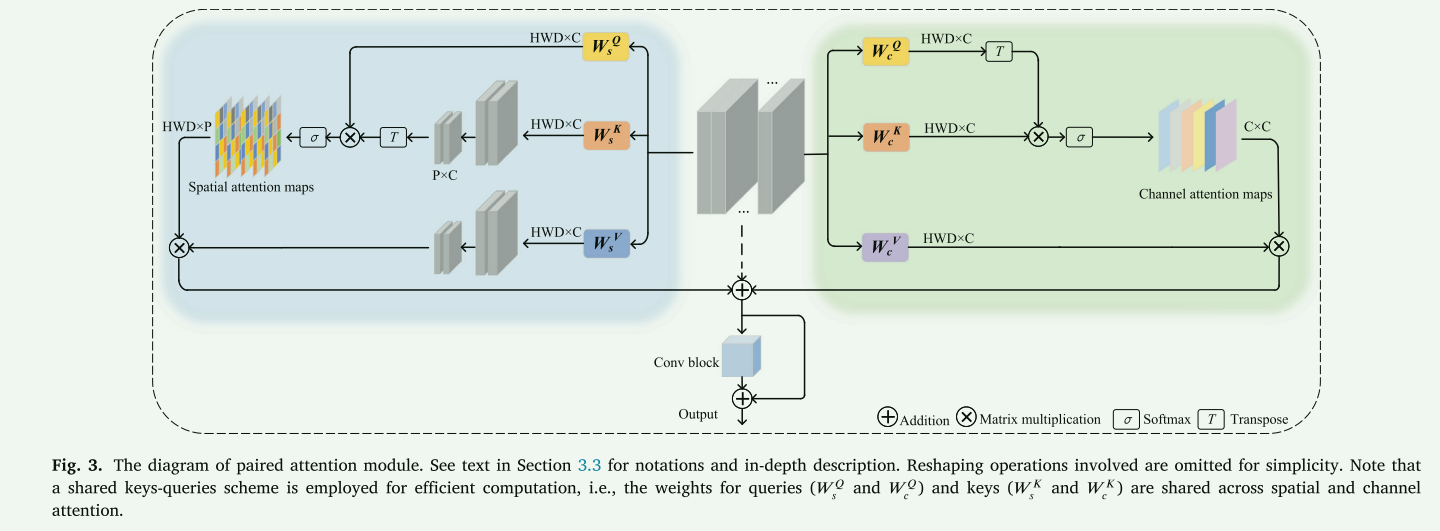
- 空间注意力块:此块的主要功能是降低自注意力机制的复杂性,从二次型减少到线性型。这意味着它能够更高效地处理空间特征,减少计算负担,同时仍然捕获长距离的空间关联。
- 通道注意力块:这部分学习不同通道特征之间的相互依赖性。通过对通道间关系的学习,它能够强化模型对于不同特征重要性的判断和调整。
- 共享键-查询机制:PA模块基于共享键(keys)-查询(queries)机制在两个注意力块之间进行操作,使用不同的值(value)层来学习互补特征。这种设计使得模块能够更全面地理解输入数据的特征,从而提高特征提取的精度和效率。
【效果】
-
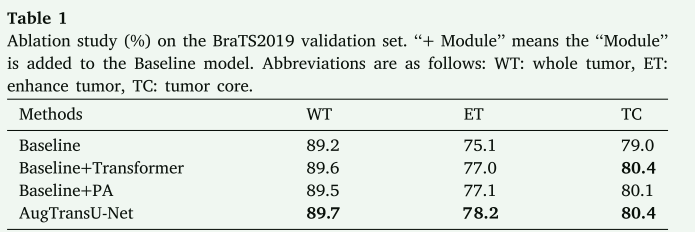
性能提升:实验结果表明,AugTransU-Net在与baseline(TransBTS)的比较中展现了其有效性和竞争力。模型在BraTS2019-2020验证数据集上分别实现了89.7%/89.8%、78.2%/78.6%、80.4%/81.9%的Dice值,这些值分别用于整个肿瘤(WT)、增强肿瘤(ET)和肿瘤核心(TC)分割。
这篇关于【论文阅读】Augmented Transformer network for MRI brain tumor segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








