本文主要是介绍爬虫案例—抓取找歌词网站的按歌词找歌名数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬虫案例—抓取找歌词网站的按歌词找歌名数据
找个词网址:https://www.91ge.cn/lxyyplay/find/
目标:抓取页面里的所有要查的歌词及歌名等信息,并存为txt文件
一共46页数据
网站截图如下:

抓取完整歌词数据,如下图:
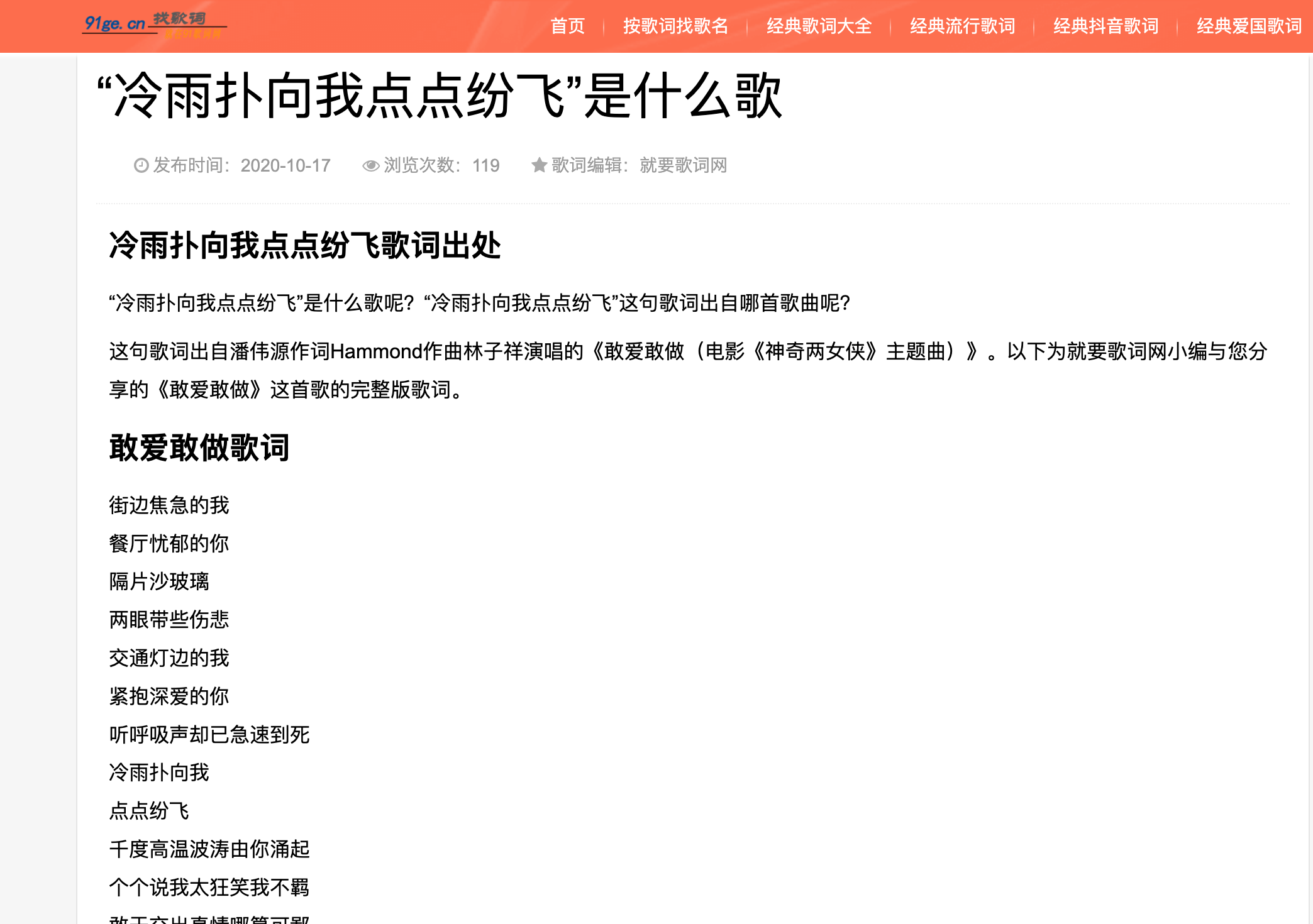
源码如下:
import asyncio
import time
import aiohttp
from aiohttp import TCPConnector # 处理ssl验证报错
from lxml import etreeheaders = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}# 返回每首歌的href函数
async def get_song_url(page_url):async with aiohttp.ClientSession(headers=headers, connector=TCPConnector(ssl=False)) as session:async with session.get(page_url) as res:html = await res.text()tree = etree.HTML(html)url_lst = tree.xpath('//div[@class="des"]/a/@href')return url_lst# 获取每首歌的详细信息
async def get_song_word(song_url):async with aiohttp.ClientSession(headers=headers, connector=TCPConnector(ssl=False)) as session:async with session.get(song_url) as res:html = await res.text()tree = etree.HTML(html)if tree is not None:song_question = tree.xpath('//div[@class="logbox"]')if song_question:song_q = song_question[0].xpath('./h1/text()')[0]else:passdiv_word = tree.xpath('//div[@class="logcon"]')if div_word:where_song = div_word[0].xpath('./h2[1]/text()')[0]question_song = div_word[0].xpath('./p[1]/text()')[0]answer_song = div_word[0].xpath('./p[2]/text()')[0]song_words = div_word[0].xpath('./p[position()>2]//text()')# song_name = div_word.xpath('./h2[2]/text()')[0].strip('\r\n\t')song_words = ''.join(song_words[:-1]).strip('\r\n\t')with open(f'songs/{song_q}.txt', 'a') as f:f.write(where_song + '\n' + question_song + '\n' + answer_song + '\n\n' + song_words)else:passif __name__ == '__main__':t1 = time.time()loop = asyncio.get_event_loop()for n in range(1, 47):song_url = f'https://www.91ge.cn/lxyyplay/find/list_16_{n}.html'urls = loop.run_until_complete(get_song_url(song_url))tasks = [get_song_word(url) for url in urls]loop.run_until_complete(asyncio.gather(*tasks))print(f'耗时:{time.time() - t1:.2f}秒')
运行结果如下图:
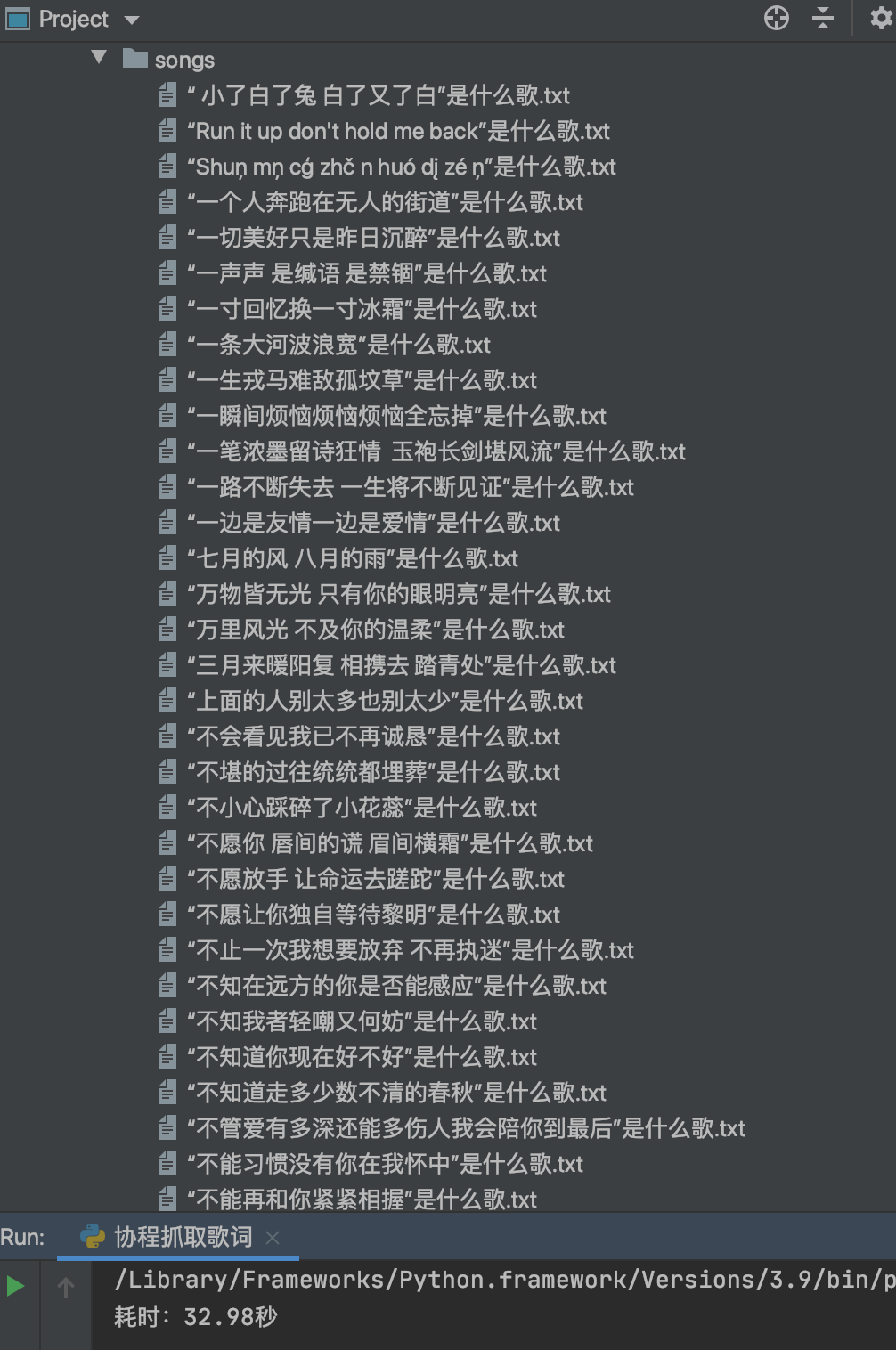
利用协程抓取数据,效率很高。
这篇关于爬虫案例—抓取找歌词网站的按歌词找歌名数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




