本文主要是介绍看书标记【R语言数据分析项目精解:理论、方法、实战 9】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
看书标记——R语言
- Chapter 9 文本挖掘——点评数据展示策略
- 9.1项目背景、目标和方案
- 9.1.1项目背景
- 9.1.2项目目标
- 9.1.3项目方案
- 1.建立评论文本质量量化指标
- 2.建立用户相似度模型
- 3.对用户评论进行情感性分析
- 9.2项目技术理论简介
- 9.2.1评论文本质量量化指标模型
- 1.主题覆盖量
- 2.评论文本分词数量
- 3.评论点赞数
- 4.评论中的照片数
- 5.评论分值偏移
- 9.2.2用户相似度模型
- 1.pearson相关系数
- 2.欧几里得距离
- 3.夹角余弦相似度
- 4.马氏距离
- 9.2.3情感性分析
- 1.文本挖掘基础知识
- 2.基于规则情感性分析方法
- 3.词汇极性判断
- 4.关键词提取
- 9.2.4R语言实例代码
- 1.分词
- 2.配置词典
- 3.增加自定义词典
- 4.增加停用词词典
- 5.关键词提取TF-IDF
- 6.词性标注
- 9.3项目实践
- 9.3.1若干自定义函数
- 1.数据清理
- 3.分词
- 9.3.2文本质量量化指标模型
- 9.3.3用户相似度模型
- 9.3.4情感词分析
- 1.导入评论数据并清洗分词
- 2.关联情感词、否定词和程度副词
- 3.对片段进行窗口期判定及综合打分
- 9.3.5总结
【R语言数据分析项目精解:理论、方法、实战 9】
Chapter 9 文本挖掘——点评数据展示策略
9.1项目背景、目标和方案
9.1.1项目背景
评论内容无效、评论数据千人一面,有必要对评论显示策略做出一定的调整
9.1.2项目目标
(1)对评论文本的质量进行监控和量化,将一些无效评论的显示顺序滞后。
(2)制定用户相似度模型,将用户的评论给与他相似的用户看,达到千人百面的效果。
(3)对评论所表达的情感进行分析,综合评分和情感两个方面对评论进行排序。
9.1.3项目方案
1.建立评论文本质量量化指标
对评论文本进行分析,评论文本质量量化指标主要考虑如下几个因素。
(1)主题覆盖量
主要考虑评论文本中对产品专有主题的覆盖情况。
(2)评论文本分词数量
评论文本写得越详细、内容越多,对访问者的帮助可能就越大,删除过渡词后,看剩余文本单词的数量,数量越多,该条评论的信息量就越大。
(3)评论点赞数
评论点赞数越多,该条评论对用户就越有用。
(4)评论中的照片数量
很好理解,有照片的评论显然要比没有照片的评论更加真实和有用。
(5)评论分值偏移
用户给该产品人为打的一个主观评价分,但并不是评分分值越高,该条评论的质量就越高,若用户的打分有失公允,那么该条评论的质量也就不算高了。
2.建立用户相似度模型
用户行为及用户属性,相似度计算,建立相似度模型
3.对用户评论进行情感性分析
基于词典的情感分析对评论文本进行分析。
9.2项目技术理论简介
9.2.1评论文本质量量化指标模型
1.主题覆盖量
指定五个主题,每个主题都有收集对应的相关词汇用于描述相关主题。每涉及一项主题为0.2,满分为1。
2.评论文本分词数量
去除停用词,得到相对真实的论文文本,然后分词,统计词频,最后计算五分位数,每个分位数区间的数从小到大赋予0.2、0.4、0.6、0.8、1分。
3.评论点赞数
计算评论点赞数,也计算五分位数,然后赋值0~1分。
4.评论中的照片数
有照片记为1分,反之为0。
5.评论分值偏移
评论分值偏移就是计算评论分值与所有评论中位数的偏移程度。首先计算所有评分的中位数,然后计算每个分值与中位数的差值绝对值,接着分别计算这些差值绝对值的20%、40%、60%、80%分位数,最后以如下标准计分(依中心递减):在中位数加减20%分位数内为1分、在中位数减去40%分位数和中位数减去20%分位数之间及中位数加上20%分位数和中位数加上40%分位数之间的记为0.8分,以此类推,在每个区间依次递减0.6、0.4和0.2分,而之所以选择中位数作为中心点是为了防止异常值的影响,针对主题也可以与需求方商讨赋予不同的权重。
9.2.2用户相似度模型
用户相似度模型可以让用户优先看到与之相似的用户的评论数,关于相似度的计算,本质上就是计算两个向量的距离,两个向量的距离越近,它们的相似度就越大。
1.pearson相关系数
衡量两个定距变量线性相关性的统计量,优缺点:皮尔逊相关系数较易理解且计算方便,但是在使用过程中需要假设数据是成对地取自于正态分布,并且从指标的几何意义上来说,它反映了两个向量线性方向的相关关系(成比例关系),非线性的相关关系无法体现。
2.欧几里得距离
优缺点:欧几里德距离是所有距离公式中广为人知且最简单的一种,但是就大部分统计问题而言,其效果不甚理想。每个维度对其贡献都是相等的,并且容易受单位量纲的影响,没有考虑到总体变异对距离远近的关联。为了弥补单位量纲上的差异,可以先对每个维度做标准化处理,然后计算欧几里德距离。
3.夹角余弦相似度
与欧几里得距离不同,夹角余弦相似度侧重于两向量之间方向差异的度量,对量纲上的铭感度较小,所以适用于对绝对数值不敏感、主观评价等数据。
4.马氏距离
本质上是数据协方差距离,考虑了不同维度之间的关系。优缺点:马氏距离去除了各维度之间的相关性,这点也是马氏距离最大的优点。若两个向量中多个维度相关性较高,则某个维度的影响会被多次使用,这显然会对最后的结果产生误差。
9.2.3情感性分析
1.文本挖掘基础知识
(1)分词模型:最大概率模型、隐马尔科夫模型、混合模型
(2)词典:若干单词组成的库,可在知网词典获取停用词、副词、否定词
2.基于规则情感性分析方法
针对每个片段判断其情感极性得分,汇总计算得到情感累计得分:
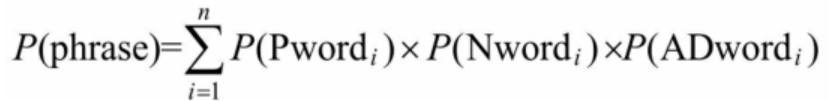
3.词汇极性判断
介绍一种算法SO-PMI,可以有效地从大量词汇中找出那些接近正向或负向的情感词,然后人为地进行最终判定,从而大大减少人工识别的时间。具体步骤如下(选自《基于平滑SO-PMI算法的微博情感词典构建方法研究》)。
4.关键词提取
TF-IDF(词频-逆文档频率),依据TF给单词赋予IDF的权重,结果从大到小排序得到关键性排序列表,TF-IDF与词在文档中出现的次数呈正比,与该词在整个语句中出现次数成反比。这种算法的优点为:简单快速,结果比较符合实际情况。这种算法也有相应的缺点:单纯以“词频”衡量一个词的重要性不够全面,有时重要的词可能出现的次数并不多,而且这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的(一种解决方法是,对全文的第一段和每一段的第一句话给予较大的权重)。
9.2.4R语言实例代码
中文常用的是“jiebaR”程序包。
1.分词
worker()
type:"mix"混合模型、"mp"最大概率模型、"hmm"HMM模型、"query"索引模型
dict:DICTPATH系统词典
hmm:HMMPATH,HMM模型路径
user:USERPATH用户词典
idf:IDFPATH ,idf词典
stop_word:STOPPATH停用词词典
write:T,是否将文件分词结果写入文件,默认为FALSE
qmax:20,最大成词的字符数,默认为20个字符
topn:5,关键词数,默认为5个
encoding:“UTF-8”,输入文件的编码,默认为UTF-8
detect:T,是否编码检查,默认为 TRUE
symbol:F,是否保留符号,默认为FALSE
lines:1e+05,每次读取文件为最大行数
output:NULL,输出路径
bylines:F,按行输出
user_weight:“max”,用户权重
#加载包
install.packages("jiebaR")
library("jiebaR")#加载分词环境
wk<-worker()
wk['爸妈第一次出国,很放心,他们告诉我会很开心,我就心满意足了']
wk #查看分词引擎配置
2.配置词典
show_dictpath() #查看默认词典位置
dir(show_dictpath()) #查看目录#打开系统词典文件jieba.dict.utf8,并打印前10行
scan(file="C:/Program Files/R/R3.2.5/library/jiebaRD/dict/jieba.dict.utf8",what=character(),nlines=10,sep='\n',encoding='utf-8',fileEncoding='utf-8')#打开用户自定义词典文件user.dict.utf8,并打印前10行
scan(file="C:/Program Files/R/R3.2.5/library/jiebaRD/dict/user.dict.utf8",what=character(),nlines=10,sep='\n',encoding='utf-8',fileEncoding='utf-8')
3.增加自定义词典
需要针对添加某些特定的词,即用户自定义词典。(自定义词典在TXT文件中,需要UTF-8编码,词典中第一行读不进去,需要从第二行开始读)
#增加自定义词典
wk["我喜欢量子号的邮轮"]#设定空间默认路径
setwd("C:\\Users\\用户路径")
#用户自定义词典名称
userdic<-'trip_dic.txt'
#加载分词引擎,导入自定义词典
wk = worker(user=userdic,bylines=TRUE,lines=5000000)
#分词
wk["我喜欢量子号的邮轮"]
4.增加停用词词典
进一步对文本数据进行处理
#用户自定义词典和停用词词典名称
userdic<-'trip_dic.txt'
stopword<-'stopword_adj.txt'
wk = worker(user=userdic,stop_word=stopword,bylines=TRUE,lines=5000000) #加载分词引擎,导入自定义词典
wk["我喜欢量子号的邮轮"]
5.关键词提取TF-IDF
#jiebaRuserdic<-'trip_dic.txt' #用户自定义词典名称stopword<-'stopword_adj.txt' wk <- worker(user=userdic,stop_word=stopword,lines=5000000) #加载分词引擎,导入自定义词典segment<-wk["R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大。"] #分词segmentfreq(segment) #计算词频
keys<-worker("keywords",topn=5) #设置关键词数量
vector_keywords(segment,keys) #计算关键词分值
TF-IDF的计算
6.词性标注
SO-PMI算法的第一步是找出相应词性的词汇,可以在work函数中设置tag来输出词性。
#用户自定义词典名称userdic<-'trip_dic.txt'stopword<-'stopword_adj.txt'wk = worker(user=userdic,stop_word=stopword,"tag",lines=5000000) #加载分词引擎,导入自定义词典segment<-wk["爸妈第一次出国,很放心,他们告诉我会很开心,我就心满意足了"] #分词
segment
9.3项目实践
9.3.1若干自定义函数
1.数据清理
“脏数据”指类似于url、空格、换行符、时间、英文字母、空值、字符长度过小等。
######################################################################
#函数功能:清理文本数据
#参数说明text:文本向量
dataclean<-function(text){text<- gsub(pattern="http:[a-zA-Z\\/\\.0-9]+","",text) #去除urltext <- gsub(pattern = " ", replacement ="", text) #gsub是字符替换函数,去空格text <- gsub("\t|\r|\v|\f|\n|\\\t", "", text) #有时需要使用\\\t text<- gsub(pattern="([0-9]{4}年)?([0-9]*月)?[0-9]{1,}日","",text)text<- gsub(pattern="([0-9]{4}年)","",text)text<- gsub(pattern="([0-9]{1,}月)","",text)text<- gsub(pattern="[0-9]{1,}","",text)text <- gsub("[a-zA-Z]", "", text) #清除英文字符text <- text[!is.na(text)] #清除对应sentence里面的空值(文本内容),要先执行文本名 text <- text[!nchar(text) < 2] #文本长度过小return(text)
}
##### 2.分句并打上相应标号######################################################################
#函数功能:分片段并打上标识
#参数说明:text:文本向量
splitsentence<-function(text){commentdata<-data.frame(id=seq(1,length(text),1),term=text)commentdata$term<-as.character(commentdata$term)#以标点符号作为分隔符把句子分成片段subcon<-strsplit(text,",|\\.|!|\\?|;|~|,|。|!|\\?|;|~|…|﹏﹏|。。。。。。|\\.\\.\\.\\.\\.\\.")temp<-unlist(lapply(subcon,length)) #计算每条评论片段数id<-rep(commentdata$id,temp) #生成每条评论标号,标号数量和片段数相同term<-unlist(subcon) #把片段结果对象变成向量#打上分句idgroupid<-function(x){subid<-seq(1:x)return(subid)}#生成片段标识subid<-paste(id,"-",unlist(lapply(temp,groupid)),seq="")subcondata<-data.frame(id=id,term=term,subid=subid)subcondata$term<-as.character(subcondata$term)subcondata$subid<-as.character(subcondata$subid)return(subcondata)
}
根据标点符号分段,为每个片段打上标签用于识别是否属于一条评论。
3.分词
######################################################################
#函数功能:分词
#参数说明:useridc:用户自定义词典文件名、stopword:停用词词典文件名、subdf:数据框,需要分词的数据,每一行为一条文本片段
library("jiebaR")segword_trn<-function(userdic,stopword,subdf){wk = worker(user=userdic,stop_word=stopword,'tag',bylines=TRUE,lines=5000000) #载入分词空间tt<-wk[subdf$term] #分词函数temp_fc<-unlist(lapply(tt,length)) #给每个分词标号id_fc<-rep(subdf[,"subid"],temp_fc)term_fc<-unlist(tt)segterm_fc<-data.frame(id=id_fc,term=term_fc,cx=names(unlist(tt)))segterm_fc$id<-as.character(segterm_fc$id)segterm_fc$term<-as.character(segterm_fc$term)segterm_fc$cx<-as.character(segterm_fc$cx)segterm_fc$id_tot<-as.numeric(unlist(lapply(strsplit(segterm_fc$id,'-'),function(x) x[1])))return(segterm_fc)
}
载入jiebaR包》载入分词空间及自定义词典和停用词词典》wk函数分词》打标号辨识是否为同一评论。
9.3.2文本质量量化指标模型
library("jiebaR")
library(plyr)
library(dplyr)userdic<-'trip_dic.txt' #用户字典
stopword<-'stopword_adj.txt' #停止词
qualitydic<-'质量标准.csv' #质量标准
qualityword<-read.csv(qualitydic,header=TRUE,stringsAsFactors=FALSE) #导入质量指标相关词词典
content<-read.csv("评论数据.csv",header=TRUE,stringsAsFactors=FALSE) #导入文本
commenttext<-content$term
commenttext<-dataclean(commenttext) #数据清理
subcondata<-splitsentence(commenttext) #分句并转换成数据框并且表上subid
segworddata<-segword_trn(userdic,stopword,subcondata) #分词#文本质量评分
#1、主题覆盖量
qualitterm<-join(segworddata,qualityword)
qualitynum<-as.data.frame(qualitterm %>% group_by(id_tot) %>% summarise(n_distinct(class,na.rm=TRUE)))
names(qualitynum)[2]<-"quality_num"
qualitynum$qualitynum_flag<-qualitynum$quality_num
attach(qualitynum)
qualitynum[which(quality_num == 1), ]$qualitynum_flag<-0.2
qualitynum[which(quality_num == 2), ]$qualitynum_flag<-0.4
qualitynum[which(quality_num == 3), ]$qualitynum_flag<-0.6
qualitynum[which(quality_num == 4), ]$qualitynum_flag<-0.8
qualitynum[which(quality_num == 5), ]$qualitynum_flag<-1
detach(qualitynum)#2 文本分词数量
segwordnum<-as.data.frame(segworddata %>% group_by(id_tot) %>% summarise(n_distinct(term,na.rm=TRUE)))
names(segwordnum)[2]<-"segword_num"segword_num<-segwordnum$segword_num
segword_num_q2<-quantile(segword_num,0.2)
segword_num_q4<-quantile(segword_num,0.4)
segword_num_q6<-quantile(segword_num,0.6)
segword_num_q8<-quantile(segword_num,0.8)
segword_num_q10<-quantile(segword_num,1)segwordnum$segwordnum_flag<-segwordnum$segword_numattach(segwordnum)
segwordnum[which(segword_num >=0 & segword_num <=segword_num_q2), ]$segwordnum_flag<-0.2
segwordnum[which(segword_num > segword_num_q2 & segword_num <= segword_num_q4), ]$segwordnum_flag<-0.4
segwordnum[which(segword_num > segword_num_q4 & segword_num <= segword_num_q6), ]$segwordnum_flag<-0.6
segwordnum[which(segword_num > segword_num_q6 & segword_num <= segword_num_q8), ]$segwordnum_flag<-0.8
segwordnum[which(segword_num > segword_num_q8 & segword_num <= segword_num_q10), ]$segwordnum_flag<-1
detach(segwordnum)#3 评论点赞数
positive_num<-content$positivenum
positive_num_q2<-quantile(positive_num,0.2)+0.001
positive_num_q4<-quantile(positive_num,0.4)+0.001
positive_num_q6<-quantile(positive_num,0.6)+0.001
positive_num_q8<-quantile(positive_num,0.8)+0.001
positive_num_q10<-quantile(positive_num,1)+0.001positivenum<-data.frame(id_tot=content$id,positive_num=content$positivenum,positivenum_flag=positive_num)attach(positivenum)
positivenum[which(positive_num >=0 & positive_num <=positive_num_q2), ]$positivenum_flag<-0.2
positivenum[which(positive_num > positive_num_q2 & positive_num <= positive_num_q4), ]$positivenum_flag<-0.4
positivenum[which(positive_num > positive_num_q4 & positive_num <= positive_num_q6), ]$positivenum_flag<-0.6
positivenum[which(positive_num > positive_num_q6 & positive_num <= positive_num_q8), ]$positivenum_flag<-0.8
positivenum[which(positive_num > positive_num_q8 & positive_num <= positive_num_q10), ]$positivenum_flag<-1
detach(positivenum)#4 评论中照片数量
photonum<-data.frame(id_tot=content$id,isphoto=content$isphoto,photo_flag=content$isphoto)attach(photonum)
photonum[which(isphoto ==0), ]$photo_flag<-0
photonum[which(isphoto ==1), ]$photo_flag<-1
detach(photonum)#5评论分值偏移
score_num<-data.frame(id_tot=content$id,score=content$score,score_flag=0)
score<-content$score
median_score<-median(score)
diffscore<-abs(score-median_score)diffscore_q2<-quantile(diffscore,0.2)+0.001
diffscore_q4<-quantile(diffscore,0.4)+0.001
diffscore_q6<-quantile(diffscore,0.6)+0.001
diffscore_q8<-quantile(diffscore,0.8)+0.001
diffscore_q10<-quantile(diffscore,1)+0.001
###+0.001是为了避免集合空集的情况
attach(score_num)
score_num[which(score>median_score-diffscore_q2 & score<=median_score+diffscore_q2), ]$score_flag<-1
score_num[which((score>median_score-diffscore_q4 & score<=median_score-diffscore_q2)|(score>median_score+diffscore_q2 & score<=median_score+diffscore_q4)), ]$score_flag<-0.8
score_num[which((score>median_score-diffscore_q6 & score<=median_score-diffscore_q4)|(score>median_score+diffscore_q4 & score<=median_score+diffscore_q6)), ]$score_flag<-0.6
score_num[which((score>median_score-diffscore_q8 & score<=median_score-diffscore_q6)|(score>median_score+diffscore_q6 & score<=median_score+diffscore_q8)), ]$score_flag<-0.4
score_num[which((score>median_score-diffscore_q10 & score<=median_score-diffscore_q8)|(score>median_score+diffscore_q8 & score<=median_score+diffscore_q10)), ]$score_flag<-0.2
detach(score_num)#6 整合评论分
qualityscore<-join(qualitynum,segwordnum)
qualityscore<-join(qualityscore,positivenum)
qualityscore<-join(qualityscore,photonum)
qualityscore<-join(qualityscore,score_num)
qualityscore<-qualityscore[,c("id_tot","qualitynum_flag","segwordnum_flag","positivenum_flag","photo_flag","score_flag")]attach(qualityscore)
qualityscore$score_tot<-qualitynum_flag*0.3+segwordnum_flag*0.2+positivenum_flag*0.2+photo_flag*0.2+score_flag*0.1
detach(qualityscore)qualityscore[order(qualityscore$score_tot),]
可以具体查看一下得分较高的评论原文。
9.3.3用户相似度模型

uiddesc<-read.csv("用户数据.csv",header=TRUE,stringsAsFactors=FALSE) #导入用户特征数据#计算欧式距离
eu_dist<-function(a,b){dist<-sqrt(sum((a-b)^2))return (dist)
}
sample_uid<-c(4,3,6,4) #新用户
simindex_chain<-c() #建立相似度初始向量
#计算新用户与每个评论用户相似度
for (i in 1:nrow(uiddesc)){eudist<-eu_dist(sample_uid,unlist(uiddesc[i,-1])) ###欧式距离simindex<-1/(1+eudist)simindex_chain<-c(simindex_chain,simindex)
}#相似度结果
simiindex_df<-data.frame(id=c(1:nrow(uiddesc)),simindex=simindex_chain)
simiindex_df[order(-simiindex_df$simindex),]
根据得分,用户将会优先看到排名在前面的用户的评论。
9.3.4情感词分析
1.导入评论数据并清洗分词
library("jiebaR")
library(plyr)
library(dplyr)
userdic<-'trip_dic.txt' #用户字典
stopword<-'stopword_adj.txt' #停止词
postivedic<-"postive.txt" #正向情感词
negtivedic<-"nagative.txt" #负向情感词
advworddic<-"程度副词.csv" #程度副词字典
denyworddic<-"否定词.csv" #否定词字典#导入情感词并附上权重
postive=readLines(postivedic,encoding='UTF-8')
nagtive=readLines(negtivedic,encoding='UTF-8')
pos<-data.frame(term=postive,weight=rep(1,length(postive)))
neg<-data.frame(term=nagtive,weight=rep(-1,length(nagtive)))
posneg_tot<-rbind(pos,neg)advword<-read.csv(advworddic,header=TRUE,stringsAsFactors=FALSE) #导入程度副词、否定词
denyword<-read.csv(denyworddic,header=TRUE,stringsAsFactors=FALSE)content<-read.csv("评论数据.csv",header=TRUE,stringsAsFactors=FALSE) #导入文本
commenttext<-content$termcommenttext<-dataclean(commenttext) #数据清理
subcondata<-splitsentence(commenttext) #分句并转换成数据框并且表上subid
segworddata<-segword_trn(userdic,stopword,subcondata) #分词
2.关联情感词、否定词和程度副词
#关联情感词、程度副词和否定词
tstterm<-join(segworddata,posneg_tot)
tstterm<-join(tstterm,advword)
names(tstterm)[length(names(tstterm))]<-"adv_score"
tstterm<-join(tstterm,denyword,by='term')
names(tstterm)[length(names(tstterm))]<-"deny_score"
tstterm$adv_score[!complete.cases(tstterm$adv_score)]<--999
tstterm$deny_score[!complete.cases(tstterm$deny_score)]<--999
tstterm$id_tot<-as.numeric(gsub(" ","",tstterm$id_tot))
3.对片段进行窗口期判定及综合打分
#####################################################################
#函数功能:对片段进行情感性打分
#参数说明:idname:片段标号、fliename:带有否定词、副词和正负情感词的文本
word_segment <- function(idname,filename){ #-- 打行号#抽取片段filepart = subset(filename,id==idname)#对片段中每个分词打上idwordfile = data.frame(filepart,idx=1:nrow(filepart) )wordindex = wordfile$idx[!is.na(wordfile$weight)] #找出正负情感词在片段中的位置#-- 上下限表citeration = data.frame(wordindex,left = wordindex-3,right = wordindex+3,leftidx = c(wordindex[1]-4,head(wordindex,-1)),rightidx = c(tail(wordindex,-1),wordindex[length(wordindex)]+4),left_up=c(tail(wordindex-3,-1),wordindex[length(wordindex-3)]+3))#窗口期判定函数computevalue <- function(i,citeration,wordindex,filepart){left = ifelse(citeration$left[wordindex==i]<0,0,citeration$left[wordindex==i])right= citeration$right[wordindex==i]leftidx= ifelse(citeration$leftidx[wordindex==i]<0,0,citeration$leftidx[wordindex==i])rightidx= citeration$rightidx[wordindex==i]left_up=citeration$left_up[wordindex==i]wdidx=citeration$wordindex[wordindex==i]result = cbind(ifelse(right<rightidx,max((filepart$adv_score[max(left,leftidx+1):max(wdidx,left_up-1)]),na.rm=T),max(filepart$adv_score[max(left,leftidx+1):wdidx],na.rm=T)),ifelse(right<rightidx,max(filepart$deny_score[max(left,leftidx+1):max(wdidx,left_up-1)],na.rm=T),max(filepart$deny_score[max(left,leftidx+1):wdidx],na.rm=T)))return(result)}#--计算值result = data.frame(t(sapply(wordindex,computevalue,citeration,wordindex,filepart)))names(result) = c('adv','deny')final_result = data.frame(id=idname ,posneg=filepart$weight[wordindex],result)return(final_result)
}#####################################################################
#函数功能:综合计算每条评论总得分
#参数说明:texttb:评论文本(打上情感词、否定词和副词标签后的)#情感词综合打分
valuefun<-function(texttb){#抽取正负情感词所在的片段idnotnull<-data.frame(id=unique(texttb$id[complete.cases(texttb$weight)]))idnotnull$id<-as.character(idnotnull$id)tstterm_nnid<-join(texttb,idnotnull,type="inner")word_index<-unique(tstterm_nnid$id)system.time(score_combine<-lapply(word_index,word_segment,tstterm_nnid))score_combine_tb<-do.call("rbind", score_combine) score_combine_tb$id<-as.character(score_combine_tb$id)score_combine_tb$adv[score_combine_tb$adv==-999]<-1score_combine_tb$deny[score_combine_tb$deny==-999]<-1score_combine_tb$value<-score_combine_tb$posneg*score_combine_tb$adv*score_combine_tb$denysubconvalue<-aggregate(score_combine_tb$value,by=list(score_combine_tb$id),sum)subconvalue$idtot<-as.numeric(unlist(lapply(strsplit(subconvalue$Group.1,'-'),function(x) x[1])))commentvalue<-aggregate(subconvalue$x,by=list(subconvalue$idtot),sum)names(commentvalue)[1]<-'id'commentvalue$x<-round(commentvalue$x,2)return(commentvalue)
}
system.time(valuetb<-valuefun(tstterm))
9.3.5总结
至此,可以根据用户相似度,让用户看到与他相似用户的评论,并且可以按照文本质量评分及情感性分值根据产品策略进行排序。从技术运维的角度来说,算法的结束并不是技术的终结,后期自定义词库及调整打分权重都需要分析师根据实际样本做出调整,在数据分析领域永远没有完结的项目,除非业务被终结了。
这篇关于看书标记【R语言数据分析项目精解:理论、方法、实战 9】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



