本文主要是介绍Cesium叠加超图二维服务、三维场景模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
Cesium作为开源的库要加超图的服务则需要适配层去桥接超图与Cesium的数据格式。这个工作iClient系列已经做好,相比用过超图二维的道友们可以理解:要用Openlayer加载超图二维,那就用iClient for Openlayer库去加载;同样的要用Cesium加载超图三维就要用iClient for Cesium库。
道友们一看:竟然要换库?我过来学cesium,你让我装iClient for Cesium?退!退!退!

道友不必惊慌! iClient for Cesium是在Cesium库基础上做增量开发,没有对原本的Cesium做改动,童叟无欺!直白点说,你装完 iClient for Cesium仍然可以按Cesium官方API文档进行Cesium的原生开发。
项目地址:cesium-demo
Cesium文档:Cesium Documentation
iClient for Cesium文档:iClient for Cesium Documentation
一、引入iClient for Cesium
1.下载
这里的引入不是重复引入,而是直接替换。
超图的包需要手动下载,没有npm仓库(其实Cesium有npm仓库和没npm一个样,npm下下来之后还是要手动复制)
SuperMap iClient3D for Cesium 产品下载
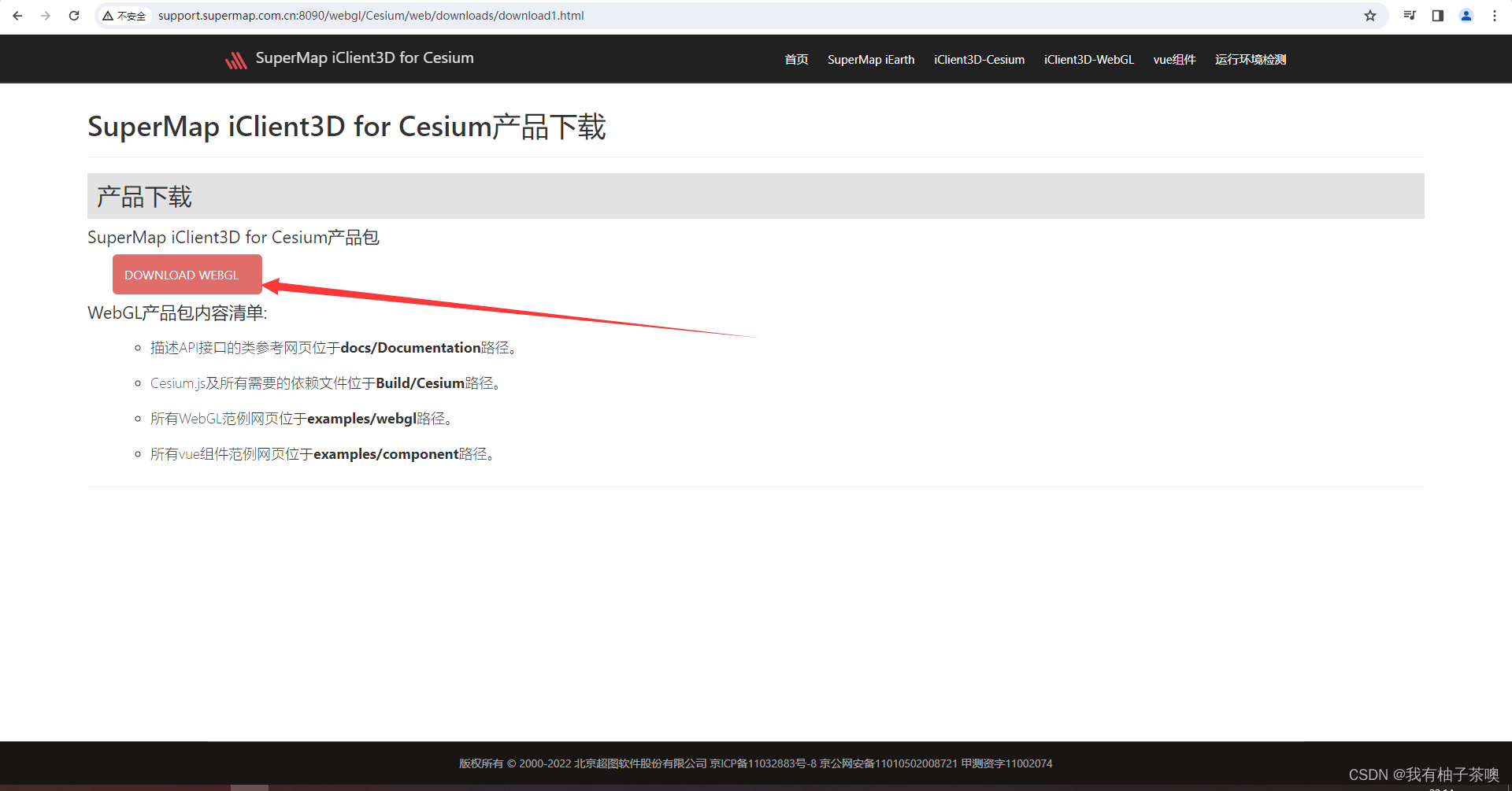
SuperMap技术资源中心|为您提供全面的在线技术服务
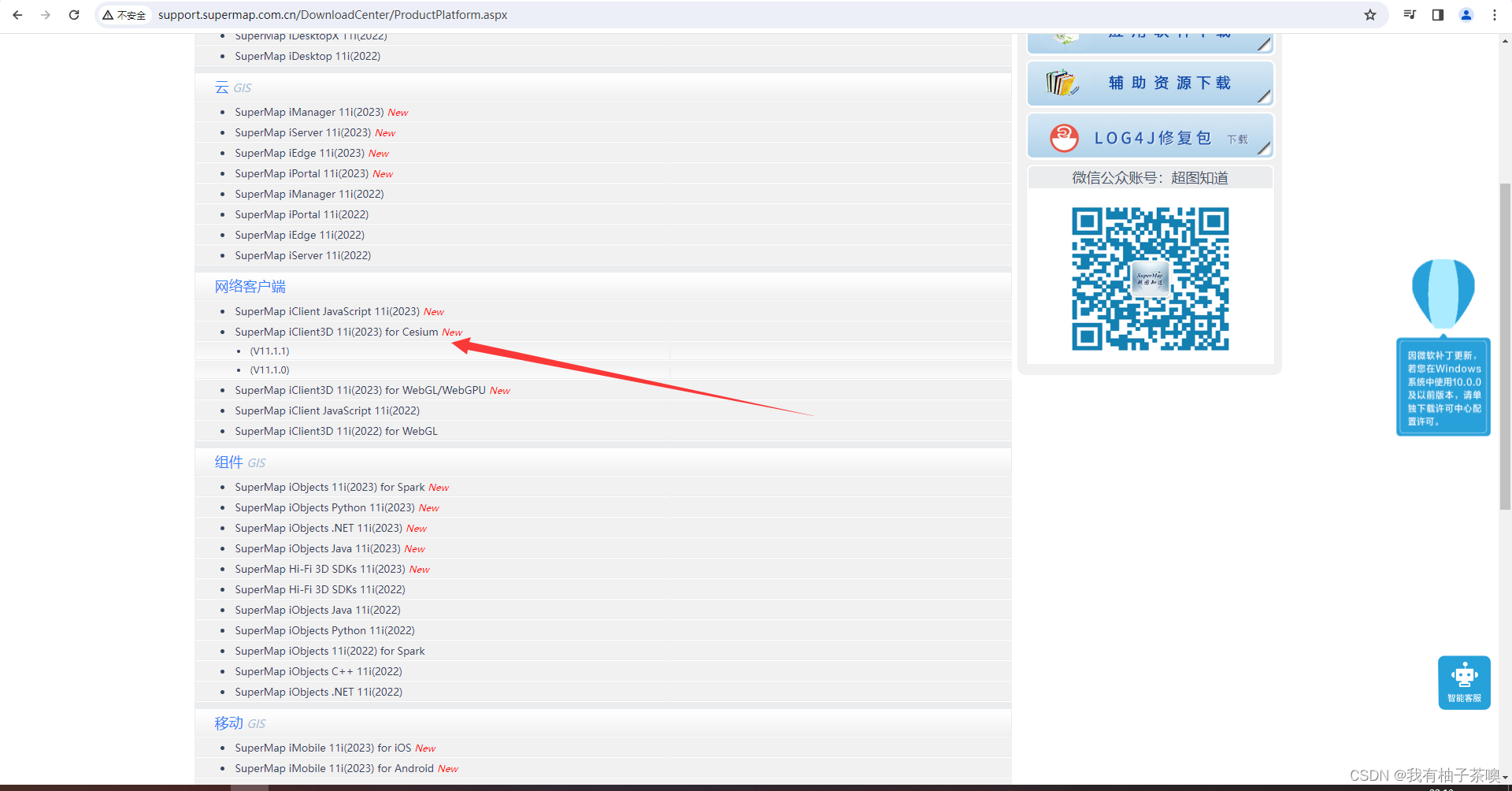
百度网盘

2.引入
引入方式与Cesium库一模一样,将下载后的包Build文件夹下的Cesium文件夹复制到public/static下,而后在index.html中引入,详细步骤见 初始化Cesium
二、加载超图二维
现在做三维的目的其核心概念为二三维一体化,所以在三维系统中叠加二维数据也是很重要的一个环节。
1.补充知识
Cesium中有3个核心对象,Cesium、Scene、Viever,Cesium对象是最底层的,其代表了整个Cesium 库和渲染引擎的实例,而Scene 对象是 Cesium 库中一个重要的组成部分,它表示一个场景,包含了地球、相机、光照、图层等元素,Viever则是对Scene进行了更高级的封装,Viewer继承了Scene的所有功能。总之这三个对象上的属性方法很多是共享的,记住这句话,不然看API会很懵。
2.imageryLayers
首先要明确原生Cesium中加载二维用什么。一般都用imageryLayers去加载,例如球体表面的影像就是如此叠加映射上去的,放大看,这些影像(无高程图片)都是平贴在球体表面的二维服务。与之相反的是地形、白膜等有高程的服务。
3.使用imageryLayers加二维
// Add an OpenStreetMaps layer
const imageryLayer = new Cesium.ImageryLayer(new Cesium.OpenStreetMapImageryProvider({url: "https://tile.openstreetmap.org/"
}));
scene.imageryLayers.add(imageryLayer);官网加载影像的示例代码,定义一个ImageryLayer对象,传OpenStreetMapImageryProvider对象(可以理解成数据源),最终添加到场景中的imageryLayers集合里去。
4.SuperMapImageryProvider
上面提到了加载oms地图只需要使用OpenStreetMapImageryProvider构造数据源,那么加载超图也只需要SuperMapImageryProvider即可,这个可以理解为将超图数据源转化成cesium的imageryLayer数据源,桥接适配层。
不同的是,OpenStreetMapImageryProvider是Cesium官方自己写的,并收纳到了Cesium源码中;而SuperMapImageryProvider是超图自己写的,毕竟超图没开源(bushi)。

加载代码贴上:
这里进行了简单封装,附加了关闭逻辑。
添加逻辑附加了图层定位;添加时顺便打上guid标识,方便后续关闭图层。
dealSuperMapService({ url, active, guid }) {const imageryLayers = this.viewer.imageryLayers;if (active) {const provider = new Cesium.SuperMapImageryProvider({url});// 皆为cesium原生,只有SuperMapImageryProvider为桥接层const layer = imageryLayers.addImageryProvider(provider);layer.guid = guid;this.viewer.flyTo(layer, { duration: 0 });} else {const layers = imageryLayers._layers;const target = layers.find(e => e.guid === guid);imageryLayers.remove(target);}},
三、加载超图三维场景
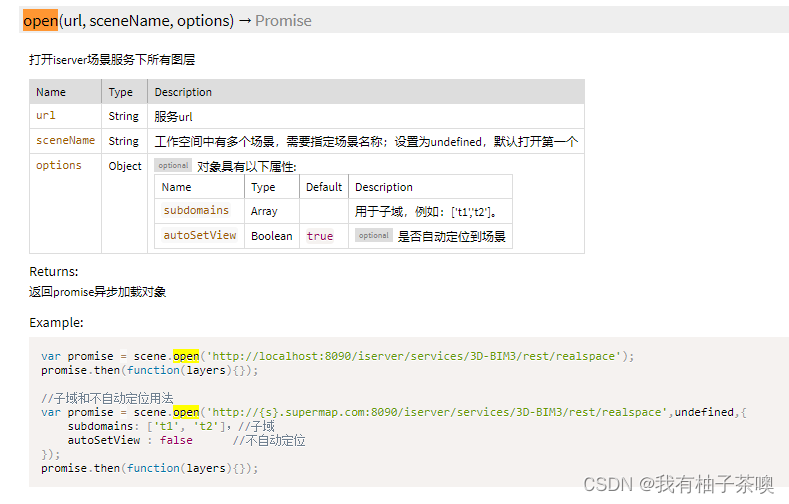
1. open()方法
此方法为超图所创,挂载Scene对象上,可以自行查看,Cesium文档中无此方法,下面是超图iClient for Cesium文档对open的简要介绍。
openSuperMapScene({ url, active }) {const scene = this.viewer.scene;if (active) {scene.open(url);} else {scene.layers.removeAll();}},
使用起来简单粗暴,直接往里面丢url即可,地址精确到realspace,也就是超图场景服务的地址,其为全加载,也就是说场景中的所有图层全部加载,无过滤功能。说其粗暴可不敢乱言,只因确实迷之操作,超图社区官方答复附上,该方法打开场景后不可以关闭。

 2.addS3MTilesLayerByScp
2.addS3MTilesLayerByScp
仍然是超图自研方法,挂接在scene上,用于添加超图的三维切片缓存图层。相较于open()而言,可进行图层过滤,可以进行自由移除。S3M是超图自主研发的用于存储三维数据的格式。

dealSingleSuperMapScene({ url, active,layerName }) {const scene = this.viewer.scene;if (active) {const promise = scene.addS3MTilesLayerByScp(url, {name: layerName});promise.then(layer => {this.viewer.flyTo(layer, { duration: 0 });});} else {scene.layers.remove(layerName);}}
其中layers类是超图在cesium基础上加的,目的是用来管理场景中的所有图图层。


四、重点说下图层定位
1.吐槽
原本是不想说这个事的,主要是看到网上的资源太差了,这一方面的全是胡诌,随便举个例子,这是网上随便搜的,大多数都是这种。这有啥用,你高低整个几何定位吧?

2.图层定位
打开图层后定位到查看区域,这才是符合操作逻辑,增强用户体验的流程,上文档:
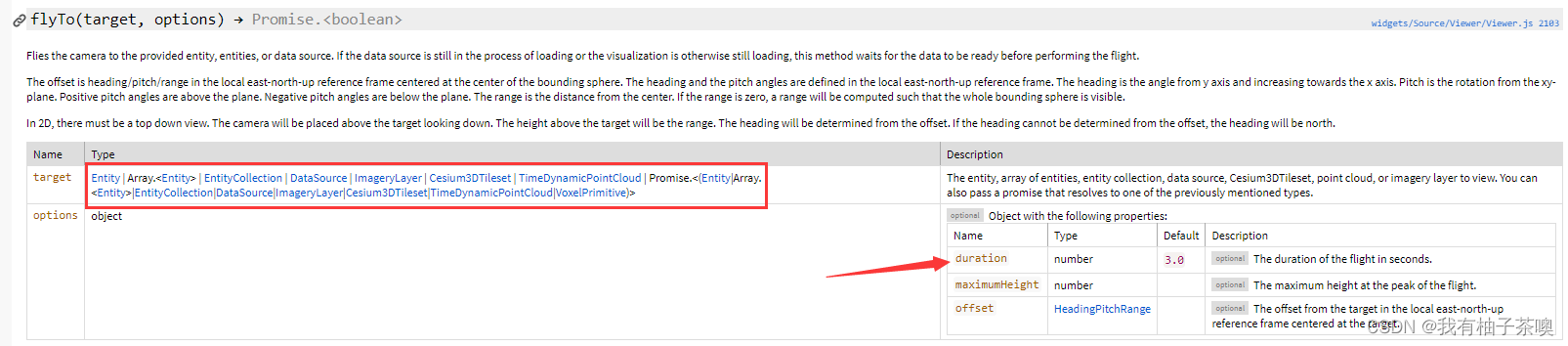
官方文档说的很清晰,flyTo方法的第一个参数支持的参数类型,其中之一就有ImagerLayer类型,结论就是二维图层可以直接当作target参数直接定位。

说完了二维图层的定位再来说说三维场景的定位,这里原本根据文档走,addS3MTilesLayerByScp返回的图层并不在flyTo的可选参数之中,因为返回的类型是S3MTileLayer类型,但超图文档flyTo并没有补充target的该类型,而该图层又可以直接flyTo定位成功,属于是文档不完善了。

这篇关于Cesium叠加超图二维服务、三维场景模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







