本文主要是介绍python爬虫 爬取链家二手房数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、简介
本次爬虫用到的第三方库如下:
import randomimport requests
from lxml import etree
import time二、打开网页
打开链家官网,进入二手房页面,可以看到该城市房源总数以及房源列表数据。
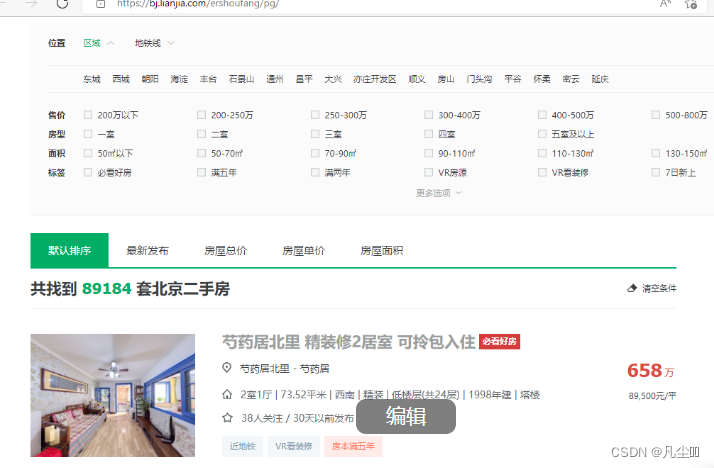
三、所有源码
import randomimport requests
from lxml import etree
import timeclass LianJia(object):def __init__(self):self.url = 'https://bj.lianjia.com/ershoufang/pg{}/'self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245.30'}# 获取响应def get_page(self, url):req = requests.get(url, headers=self.headers)html = req.text# 调用解析函数self.parse_page(html)# 解析数据 提取数据def parse_page(self, html):parse_html = etree.HTML(html)li_list = parse_html.xpath('//*[@id="content"]/div[1]/ul/li')# 传入字典house_dict = {}for li in li_list:# 传入字典house_dict['名称'] = li.xpath('.//div[@class="positionInfo"]/a[1]/text()')# # 总价# price=li.xpath().strip()house_dict['总价-万'] = li.xpath('//div[@id="content"]/div[1]/ul/li[6]/div[1]/div[6]/div[1]/span/text()')# # 单价house_dict['单价'] = li.xpath('//div[@id="content"]/div[1]/ul/li[6]/div/div/div[2]/span/text()')print(house_dict)# 保存数据def write_page(self):pass# 主函数def main(self):# 爬取页数for pg in range(1, 5):url = self.url.format(pg)self.get_page(url)# 休眠time.sleep(random.randint(0, 2))if __name__ == '__main__':start = time.time()spider = LianJia()spider.main()end = time.time()print('执行时间:%.2f' % (end - start))
爬取内容展示
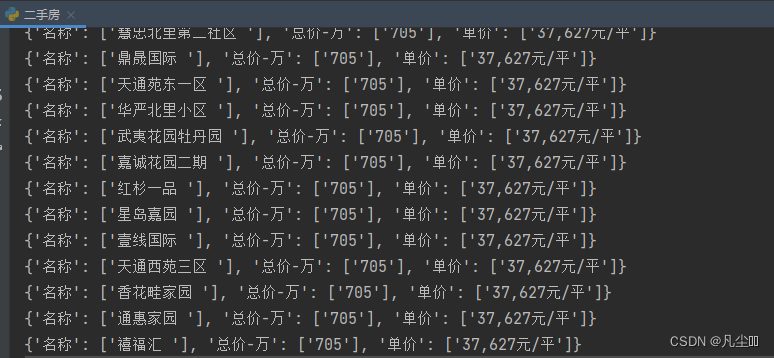
这篇关于python爬虫 爬取链家二手房数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






