链家专题
链家web安全面试经验分享
吉祥知识星球http://mp.weixin.qq.com/s?__biz=MzkwNjY1Mzc0Nw==&mid=2247485367&idx=1&sn=837891059c360ad60db7e9ac980a3321&chksm=c0e47eebf793f7fdb8fcd7eed8ce29160cf79ba303b59858ba3a6660c6dac536774afb2a6330#rd 《

链家笔试:斐波那契数列中的第k个数
斐波那契数列中的第k个数 题目描述: Fibonacci数列:1、1、2、3、5、8、13 …..的第k项是多少(1<=k<=10000) import java.util.Scanner;public class Main {public static void fib(int k) {int a = 1, b = 1;while(k > 0) {k--;if(k == 0) Syst
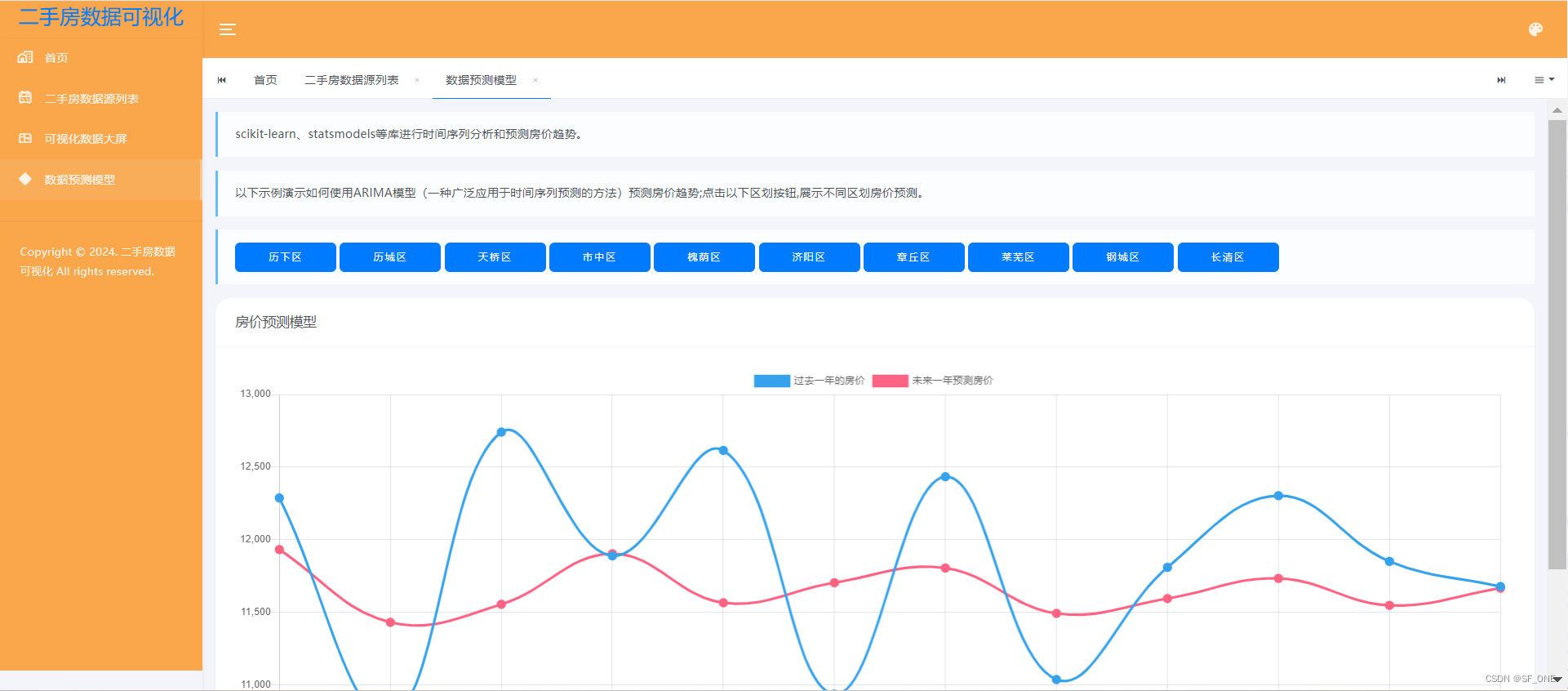
基于python的二手房数据分析建模及可视化研究,爬取链家二手房数据,可视化分析,房价预测模型
介绍 主要涉及通过爬取济南市链家二手房数据,然后对数据进行处理,包括缺省值处理,高德地图获取二手房地址所属市区,经纬度等数据处理。然后通过python的flask框架编写后端接口,把数据响应给前端。然后前端通过AJAX请求数据,拿到数据以后通过bootstarp,JQuery,Echarts进行数据多维度的统计与展示;最后通过获取某个区划内一年内的房价数据进行的预测。主要功能涉及,数据源爬取,数

【Python】动态页面爬取:获取链家售房信息(学堂在线 杨亚)
一、内容来源 任务:学会爬取一个网站的部分信息,并以".json"文件形式保存 课程来源:大数据分析师(第一期)(北邮 杨亚) 爬取网站:链家二手房 链家新房 二、准备工作 对于准备阶段,可参考: 【Python】Scrapy入门实例:爬取北邮网页信息并保存(学堂在线 杨亚) 1、创建工程 在cmd.exe窗口,找到对应目录,通过下列语句创建工程 scrapy startproject
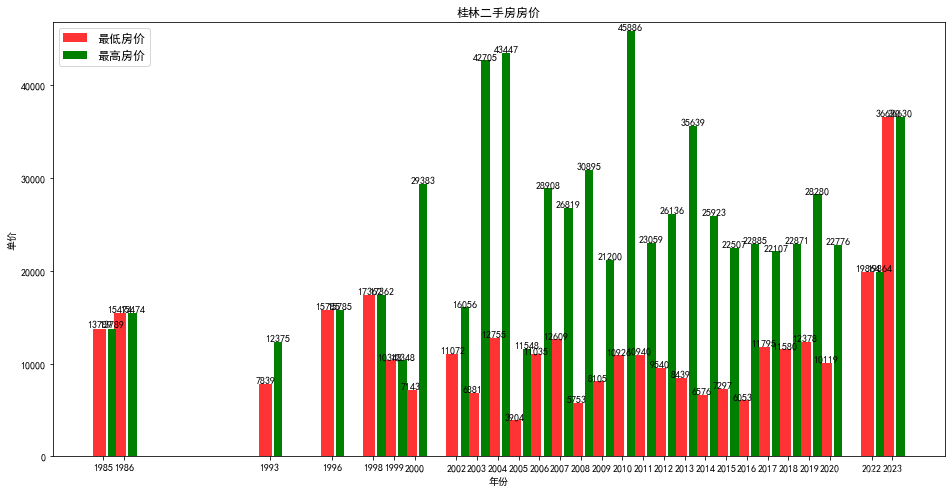
爬取链家二手房房价数据存入mongodb并进行分析
实验目的 1.使用python将爬虫数据存入mongodb; 2.使用python读取mongodb数据并进行可视化分析。 实验原理 MongoDB是文档数据库,采用BSON的结构来存储数据。在文档中可嵌套其他文档类型,使得MongoDB具有很强的数据描述能力。本节案例使用的数据为链家的租房信息,源数据来自于链家网站,所以首先要获取网页数据并解析出本案例所需要的房源信息,然后将解析后的数据存

2002-2018年链家-住房交易微观数据
数据集名称:链家-住房交易微观数据(共31万余条) 时间范围:2002-2018年 数据来源:链家官网 相关说明:数据指标:地理位置、市场行情、房屋户型、所在楼层、房屋构造、所处区域、房屋价格、交易时间、电梯、地铁、建筑时间等26项指标 数据用途:1.房价市场行情 2.房价的影响因素 3.工具变量 关键词:微观数据 住房交易 交易时间 房屋价格 工具变量 部分数据截图: 下
链家全国各省城市房屋数据批量爬取,别再为房屋发愁!
1、前言 本文爬取的是链家的二手房信息,相信个位小伙伴看完后一定能自己动手爬取链家的其他模块,比如:租房、新房等等模块房屋数据。 话不多说,来到链家首页,点击北京 来到如下页面,这里有全国各个各个省份城市,而且点击某个城市会跳转到以该城市的为定位的页面 点击二手房,来到二手房页面,可以发现链接地址只是在原先的URL上拼接了 /ershoufang/,所以我们之后也可以直接

【Python_requests学习笔记(二)】基于requests和lxml模块,爬取链家房产数据
基于requests和lxml模块,爬取链家房产数据 前言 此篇文章中介绍基于requests,lxml模块和Xpath选择器,爬取链家房产数据的案例。 正文 1、需求梳理 抓取链家二手房网站中的房源信息,如房源名称、地址、户型、面积、方位、是否精装、楼层、年代、类型、总价。 2、爬虫思路 确认所抓数据在响应内容中是否存在 所抓取的内容在响应内容中存在分析url地址规律 第一页:ht
python爬虫 爬取链家二手房数据
一、简介 本次爬虫用到的第三方库如下: import randomimport requestsfrom lxml import etreeimport time 二、打开网页 打开链家官网,进入二手房页面,可以看到该城市房源总数以及房源列表数据。 三、所有源码 import randomimport requestsfrom lxml import etree

链家2018招聘京外笔试题(Android研发工程师)
写在前面 有段时间没有写博客了。最近主要是在深入学习Android和准备校招。 前段时间投了不少简历出去,陆陆续续也经历了几场笔试面试。趁着这几天开学的空闲,梳理一下周六晚做的链家笔试题。 链家在房源信息方面做得确实是国内首屈一指,我在上海实习期间就已经切切实实体味到了,真的是,感觉走到哪儿都有它家的门店。所以这次就投了一波简历来尝试一下。 总的来说,链家笔试的题目
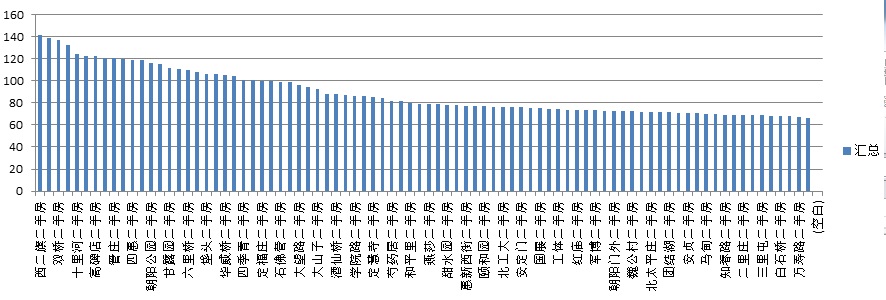
链家地产页面抓取实验以及二手房信息统计概览
项目参考:LianJiaSpider 原本该练习项目是想用来搜索购物网站某商品的降价抢购信息的,比如《什么值得买》。 但是那个网站貌似有防爬虫机制,因此转移目标,改搜搜二手房信息,想想应该会有人有这种需求的,呵呵呵呵呵呵呵呵。。。。。 正好链家地产的页面可以顺利抓取,而且该网站的房源信息查询条件是直接拼接在URL中的,拼接规则极其简单。所以就拿这个网站下手了=。= 涉及工具 主要还是用M
Python爬虫入门教程【16】:链家租房数据抓取
1. 写在前面 作为一个活跃在京津冀地区的开发者,要闲着没事就看看石家庄这个国际化大都市的一些数据,这篇博客爬取了链家网的租房信息,爬取到的数据在后面的博客中可以作为一些数据分析的素材。 我们需要爬取的网址为:https://sjz.lianjia.com/zufang/ 2. 分析网址 首先确定一下,哪些数据是我们需要的 可以看到,黄色框就是我们需要的数据。 接下来,确定一下翻页规
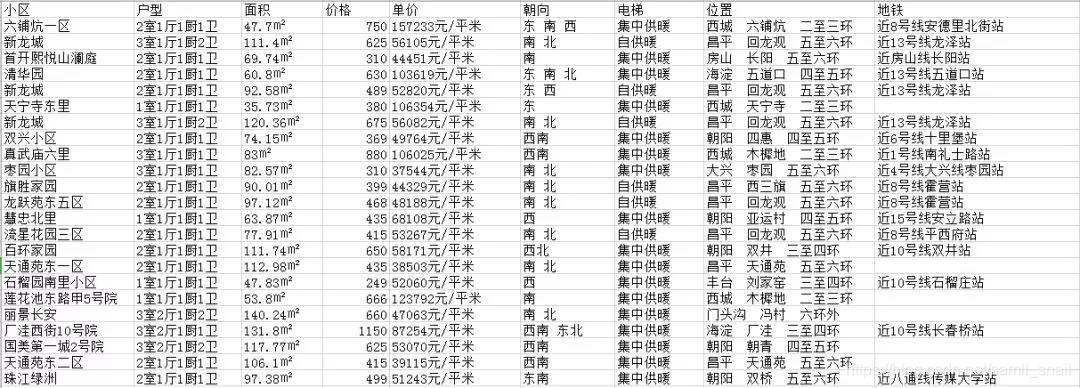
python采集链家二手房信息
都说现在的房价很高,具体有多高呢,我们一起来看看。 现在网上关于房子的价格以及交易信息鱼龙混杂,与实际情况相差比较大,目前链家平台的数据应该是相对比较可靠的,所以这次我们就打算去链家爬一爬。 说到爬虫,前面也有说过,无非就三个主要的步骤 1、获取目标网页或接口 2、从目标网页或接口中解析并提炼出你要的数据字段 3、数据保存 我们今天就以链家平台
TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享。 编辑:Cynthia 李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作。专注于数据仓库、任务流调度、元数据管理、自助报表等领域。之前在百度从事了四年的数据仓库和工具平台的研发工作。 导读:链家网大数据部门负责收集加工公司各产品线的数据,并为链家集团各业务部门提供数据支撑。本

北邮 python 爬虫爬取链家的新房数据进行数据处理
博主声明:用途仅供学习 items.py import scrapyclass MyItem(scrapy.Item):# define the fields for your item here like:name = scrapy.Field() # 名称place1 = scrapy.Field() # 地理位置place2 = scrapy.Field()place3

链家集团以大数据为行业升级赋能
在近日举办的2018年链家年度思享会上,链家研究院发布的2017房地产市场年报认为,2017年成为房地产市场“超级繁荣期”的尾巴,“品质时代”将是2018年关键词,回归价值将是2018年房地产市场的核心标志。 “房地产企业应当从开发型向服务型转变,我们的存量房不少,并且还在开发,随着经济增长从高速发展阶段转向高质量发展阶段,我们的房地产也应该从数量的增长转向质量的发展,这是未来房地产发展
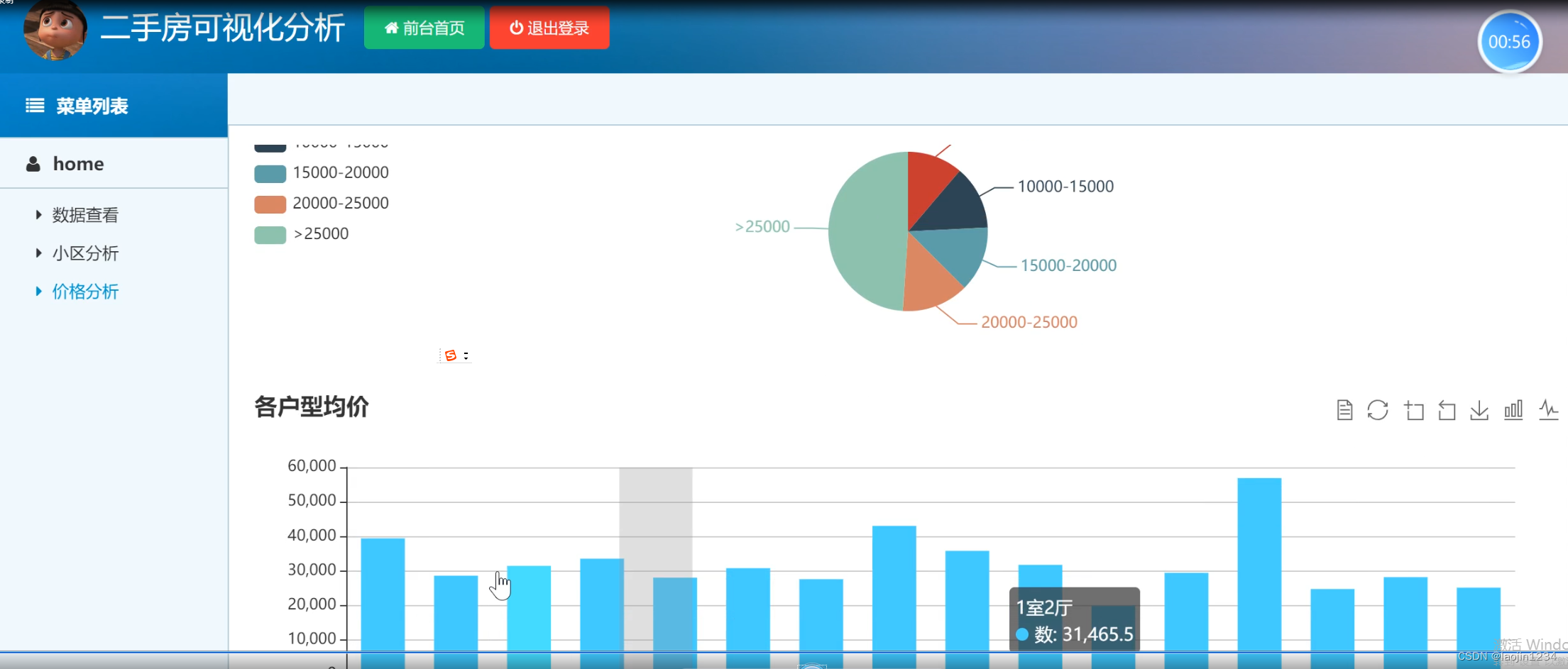
flask+mysql+广州链家可视化
flask+mysql+广州链家可视化,此系统有详细的录屏,下面只是部分截图,需要看完整录屏联系博主 系统开发语言python,框架为flask,数据库mysql,分为爬虫和可视化分析
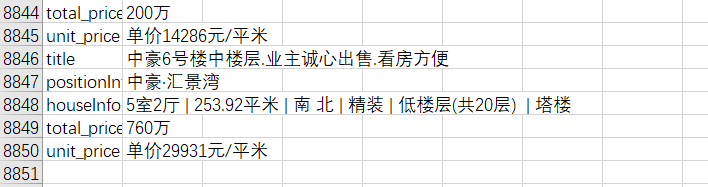
python爬虫之多线程爬取链家郑州郑东新区二手房信息
上次获取了链家658家的郑州二手房信息的房源,本次获取的为9600多家的房源信息,共一百页,但由于太多,所以就获取了前50页的内容。获取的速度也是非常的快。 代码如下: '''多线程爬取链家二手房信息'''# 导入第三方库import timeimport requestsimport threadingfrom lxml import etreefrom fake_userag
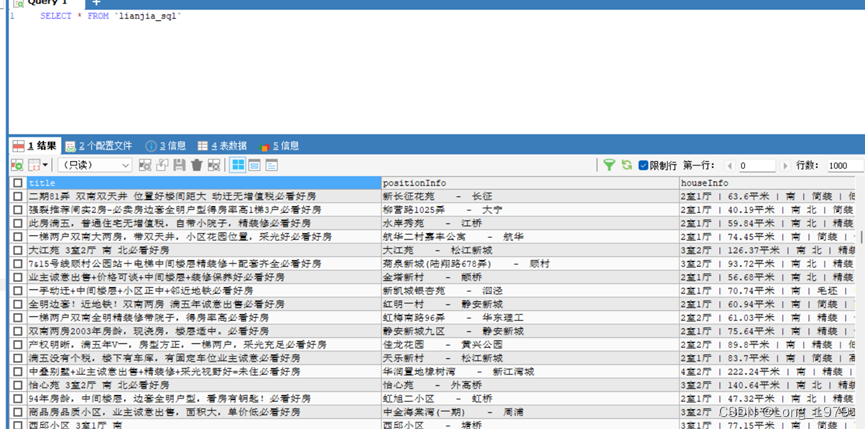
爬取上海链家二手房数据信息并使用mysql进行保存
需求: 爬取的网址是:上海二手房房源_上海二手房出售|买卖|交易信息(上海链家) 爬取的内容是:标题,房屋位置,房屋信息,价格(总价,真实价格),房屋标签 使用到的库:pymysql(作为数据存储方式),request(发送请求),BeautifulSoup(用于网页解析) 思路: 打开所要爬取的网页,进入网页源代码模式,按照自己的需求找到爬取的数据内容所在位置,接下来使用