本文主要是介绍python采集链家二手房信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
都说现在的房价很高,具体有多高呢,我们一起来看看。
现在网上关于房子的价格以及交易信息鱼龙混杂,与实际情况相差比较大,目前链家平台的数据应该是相对比较可靠的,所以这次我们就打算去链家爬一爬。
说到爬虫,前面也有说过,无非就三个主要的步骤
1、获取目标网页或接口
2、从目标网页或接口中解析并提炼出你要的数据字段
3、数据保存
我们今天就以链家平台上北京地区二手房为例,首先是打开目标网页。
https://bj.lianjia.com/ershoufang/
网页下面有分页,一共提供了 100 页数据,也就是说这 100 页都是我们的目标网页,所以第一件事就是要获取到总页数。
打开开发者模式可以看到,有个字段 totalPage 字段,这个字段就是总页数,如下图。
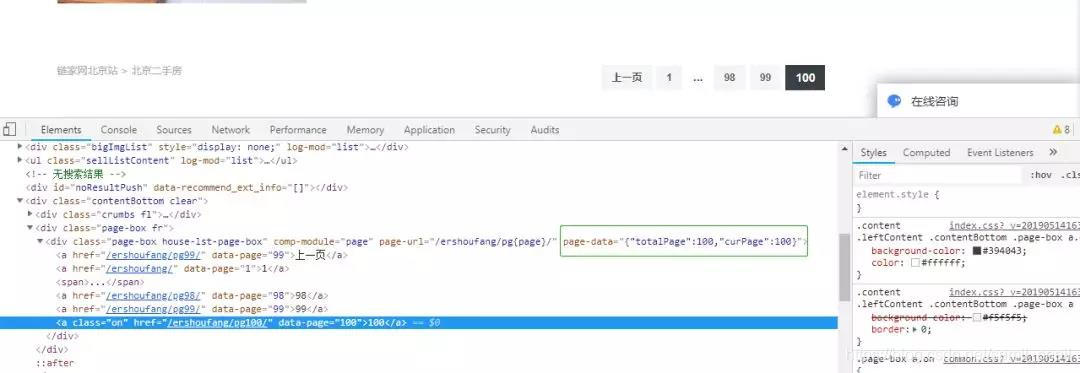
有了总页数之后呢,接下来就是要对这 100 个页面循环解析了,把我们要的字段和数据都解析出来。
为了获取更详细的数据,这里我们进入到详情页去解析数据,同样打开开发者模式,看到有总价 total(总价)、unitPriceValue(单价)、areaName(位置)等字段,这些就是我们要获取的主要字段。
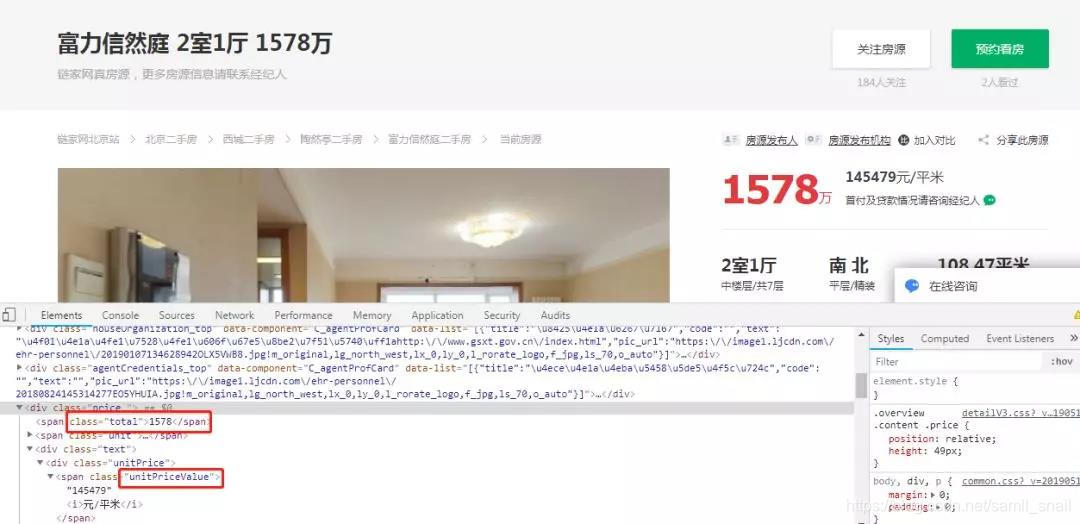
解析得到字段数据后,就要把数据保存起来,保存数据的方式一般有保存到数据库(Mysql、MongoDB)和保存到本地文件(txt、excel、csv),为了方便起见,这里我们将数据只保存到本地 csv 文件。
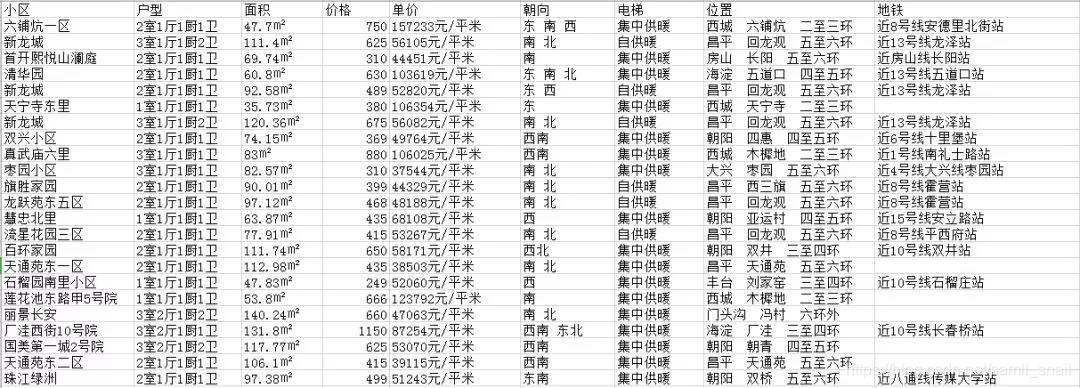
上面说的就是这个爬虫的大致过程,下面是一段主要代码,在公众号后台回复关键字【链家】可获取完整代码,有需要 csv 文件数据的也可以后台私信联系我哈。
def getContent(self, url):totalPage = self.getTotalPage(url)totalPage = 2 #为了方便调试,我这里把总页数写死了# 循环处理每个目标页面for pageNum in range(1, totalPage+1 ):url = "https://bj.lianjia.com/ershoufang/pg{}/".format(pageNum)print("正在获取第{}页数据: {}".format(pageNum,url))response = requests.get(url, headers = self.headers)soup = BeautifulSoup(response.text, "html.parser")links = soup.find_all("div", class_ = "info clear")for i in links:link = i.find("a")["href"]detail = self.parseDetail(link)self.datas.append(detail)#为了防止反爬限制休眠1stime.sleep(1)# 数据存储到csv文件中data = pd.DataFrame(self.datas)# 自定义字段columns = ["小区", "户型", "面积", "价格", "单价", "朝向", "电梯", "位置", "地铁"]data.to_csv("./lianjiaData.csv", encoding='utf_8_sig', index=False, columns=columns)
这篇关于python采集链家二手房信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





