本文主要是介绍链家地产页面抓取实验以及二手房信息统计概览,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目参考:LianJiaSpider
原本该练习项目是想用来搜索购物网站某商品的降价抢购信息的,比如《什么值得买》。
但是那个网站貌似有防爬虫机制,因此转移目标,改搜搜二手房信息,想想应该会有人有这种需求的,呵呵呵呵呵呵呵呵。。。。。
正好链家地产的页面可以顺利抓取,而且该网站的房源信息查询条件是直接拼接在URL中的,拼接规则极其简单。所以就拿这个网站下手了=。=
涉及工具
主要还是用MAVEN构建项目,引入了几个基础包:
apache httpclient - 用于处理HTML请求
jsoup - 用于处理HTML页面文档
mysql-connector-java + c3p0 - 用于连接数据库
项目主要设计
单例模式URL管理
由于在查询某一搜索条件的结果页的时候,往往遇到分页的情况需要分析当前结果页是否有分页,如果有则添加所有分页的URL,留着后期处理,因此要将URL设计成一个公共的资源。
目前该项目爬虫为单一线程,但是为了后期扩展成多线程模式,要让所有爬虫能访问URL列表资源,并且能动态添加URL记录,就应该考虑
到同步的问题。因此,将URL资源设计成单例模式管理。代码如下(核心是stack,同步锁暂未添加):
public class URLPool {private static URLPool Instance;private Stack<String> stack;private URLPool(){stack = new Stack<String>();}public static URLPool getInstance(){if(Instance == null){Instance = new URLPool();}return Instance;}//批量添加URLpublic void batchPush(List<String> URLS){for(String URL : URLS){if(!stack.contains(URL)){stack.push(URL);}}}//添加URLpublic void pushURL(String URL){if(!stack.contains(URL)){stack.push(URL);}}//是否有更多URLpublic boolean hasNext(){return !(stack.isEmpty());}//弹出一个URLpublic String popURL(){if(hasNext()){return stack.pop();} else {return null;}}
}
HttpClient 请求
主要使用HttpClient封装一个GET方法来请求HTML。同时,为后期模拟浏览器方便,预留了RequestHeader修饰方法。代码如下
GET方法
public static final String CHARSET = "UTF-8";public static String httpGet(String pageUrl, HttpHeader header) throws Exception{return getAction(pageUrl, header);}public static String httpGet(String pageUrl) throws Exception{return getAction(pageUrl, null);}private static String getAction(String pageUrl, HttpHeader header) throws Exception{@SuppressWarnings("resource")HttpClient client = new DefaultHttpClient();HttpGet httpGet = new HttpGet();httpGet.setURI(new URI(pageUrl));String content = "";if(header != null){httpGet = header.attachHeader(httpGet);}BufferedReader in=null;try {HttpResponse response = client.execute(httpGet); if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) { in = new BufferedReader(new InputStreamReader(response.getEntity().getContent()));StringBuffer sb = new StringBuffer("");String line = "";while((line = in.readLine())!=null){sb.append(line).append("\n");}in.close();content = sb.toString();} else {throw new Exception("网络解析错误:" + response.getStatusLine());}} catch (Exception e) {throw e;} finally{if(in != null){in.close();}}return content;}
RequestHeader 修饰
public class HttpHeader {private HashMap<String,String> headerMap ;public HttpHeader (HashMap<String, String> map){this.headerMap = map;}public HttpHeader(){this.headerMap = new HashMap<String, String>();}public void addParam(String key, String value){this.headerMap.put(key, value);}public Map getHeaderMap(){return this.headerMap;}public HttpGet attachHeader(HttpGet httpGet){for(String key : this.headerMap.keySet()){httpGet.setHeader(key, this.headerMap.get(key));}return httpGet;}}
HTML处理(jsoup)
这里主要是将上边GET到的HTML字符串封装成jsop document的格式,然后用jsoup的API对文档进行分析,提取所需的数据。代码不贴了,API请参考:
jsoup cookbook
抓取结果及简单统计
原始数据
由程序抓取的记录存储在MySQL中。
EXCEL简单透视
通过简单EXCEL透视图表可以得到一些直观的数据,没有做深入挖掘,尝试了几个参数的组合。
查询条件:朝阳、海淀二手房(房屋售价也有限制,这就不说了)。
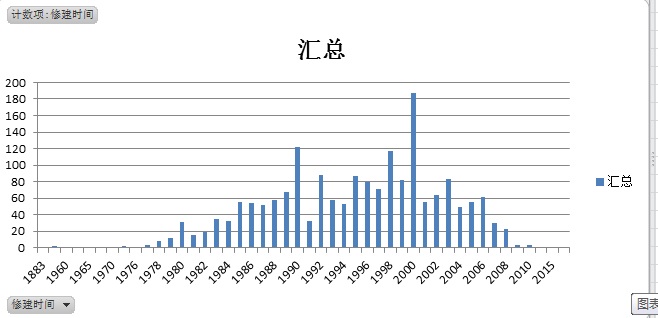
房屋修建时间分布
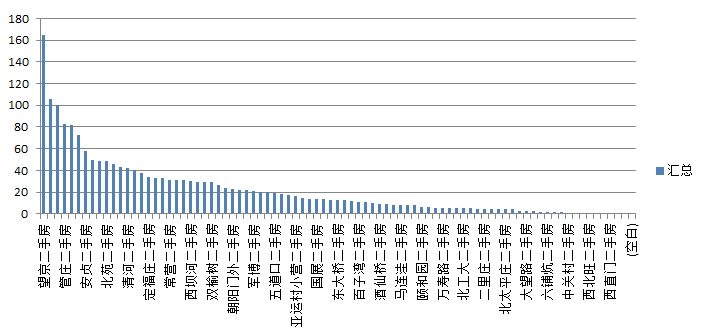
区域在售房屋数量分布
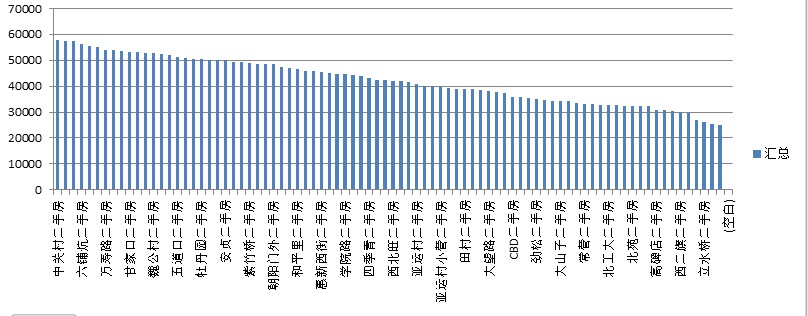
区域平米售价
楼型分布
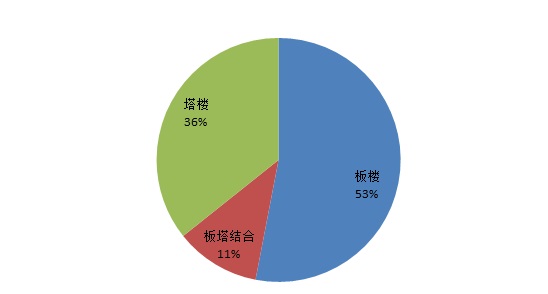
区域在售房屋平均面积
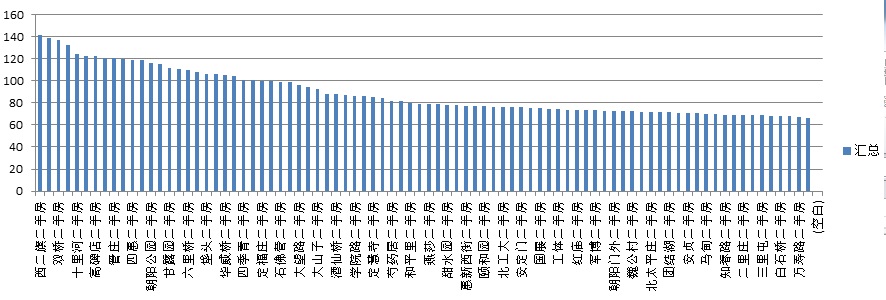
…..
啥也不说了,搬砖去了,呵呵呵呵呵呵呵。。。。。。。。。。。。
这篇关于链家地产页面抓取实验以及二手房信息统计概览的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




