本文主要是介绍【大数据处理技术实践】期末考查题目:集群搭建、合并文件与数据统计可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
集群搭建、合并文件与数据统计可视化
- 实验目的
- 任务一:
- 任务二:
- 实验平台
- 实验内容及步骤
- 任务一:搭建具有3个DataNode节点的HDFS集群
- 集群环境配置
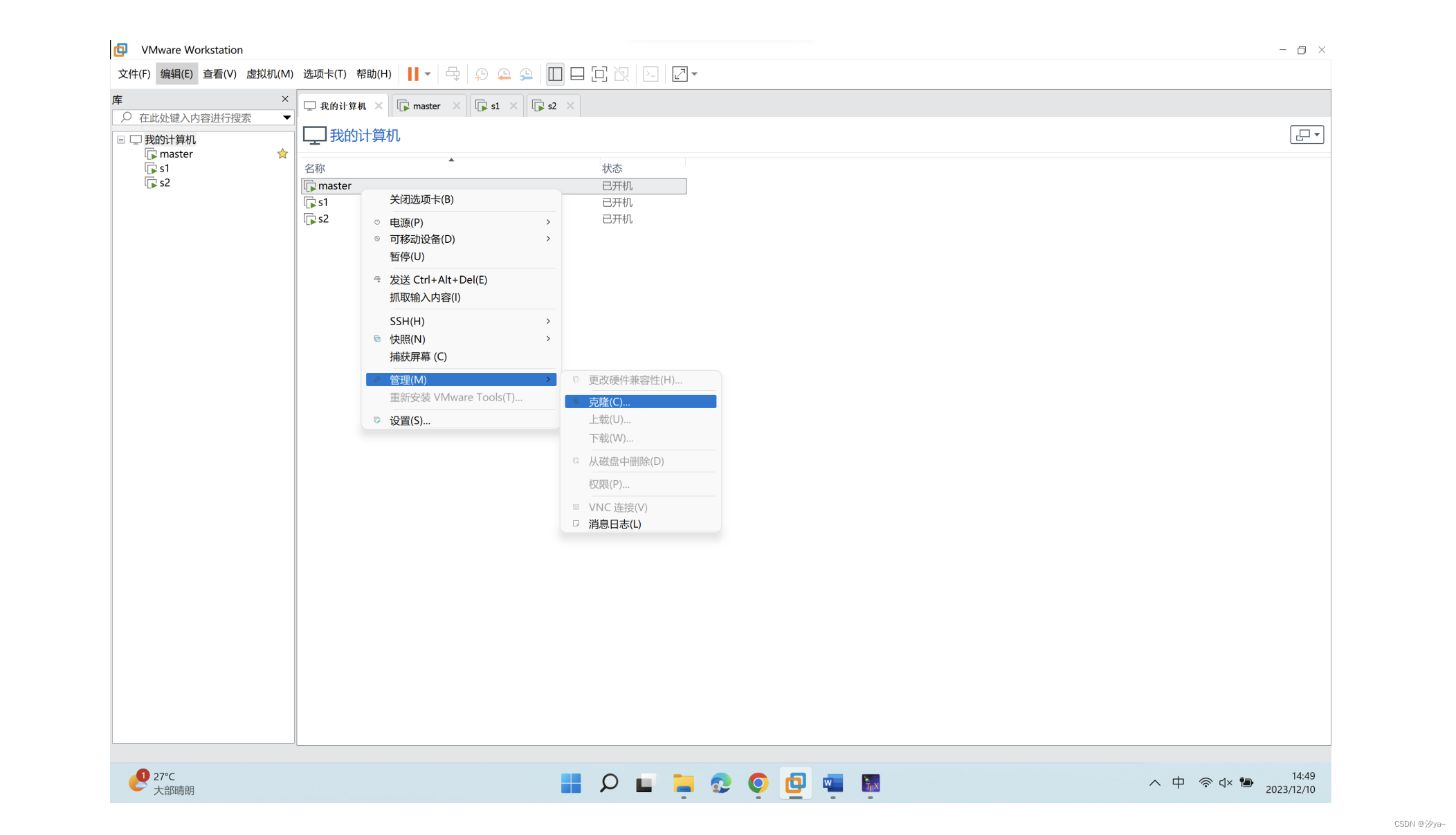
- 克隆的方式创建 Slave 节点
- 修改主机名
- 编辑 hosts 文件
- 生成密钥
- 免认证登录
- 修改 hadoop 的配置文件
- 编辑 workers 文件
- 复制配置后的 hadoop 目录传到从机上
- 启动集群
- 任务二之实验一 :编程实现合并文件MergeFile的功能
- 数据下载与上传至Hadoop
- 打开 eclipse
- 编写实现合并文件MergeFile的功能的java代码
- 启动 Hadoop 并运行 Java 代码,合并文件
- 查看合并后的文件
- 任务二之实验二:对网站用户购物行为数据集进行统计分析
- 数据预处理
- 查看前 5 行记录,每行记录都包含 5 个字段如下:
- 对用户的购物行为“behavior_type”进行统计,并将统计结果通过柱状图进行呈现
- 按月对用户的购物行为“behavior\_type”进行统计,并将结果通过柱状图进行呈现
- 总结
- 实验报告下载
实验目的
任务一:
采用虚拟机的方式搭建一个具有3个DataNode节点的HDFS集群,将搭建过程记录在实验报告中。采用虚拟机的方式,先配置好Hadoop的主节点,然后通过克隆的方式创建Slave节点,实现3节点的HDFS集群
任务二:
实验一:使用任务一搭建的集群,编程实现合并文件MergeFile的功能:
将数据集trec06p\_sample中的文件合并成为一个文件。假设集群的用户目录为hdfs://localhost:9000/user/hadoop,将合并的结果输出到hdfs://localhost:9000/user/hadoop/merge.txt 中
实验二:使用任务一搭建的集群,对网站用户购物行为数据集进行统计分析:
对用户的购物行为“behavior\_type”进行统计,并将统计结果通过柱状图进行呈现按月对用户的购物行为“behavior\_type”进行统计,并将结果通过柱状图进行呈现
实验平台
- 操作系统:Linux(CentOS)
- 可视化工具:R语言
- JDK 版本:1.8
- Java IDE
- Eclipse
- Hadoop
实验内容及步骤
任务一:搭建具有3个DataNode节点的HDFS集群
集群环境配置
克隆的方式创建 Slave 节点
- 1.采用虚拟机的方式,先配置好 Hadoop 的主节点, 此处选用之前配置好的节点作为 master 主机,然后通过克隆的方式创建 Slave 节点,实现 3 节点的 HDFS 集群
修改主机名
- 2.修改主机名,三台虚拟机都要进行的
#给3台虚拟机设置主机名分别为master、s1和s2。#在第一台机器操作hostnamectl set-hostname master#在第二台机器操作hostnamectl set-hostname s1#在第三台机器操作hostnamectl set-hostname s2
设置完毕后需重启虚拟机:reboot
编辑 hosts 文件
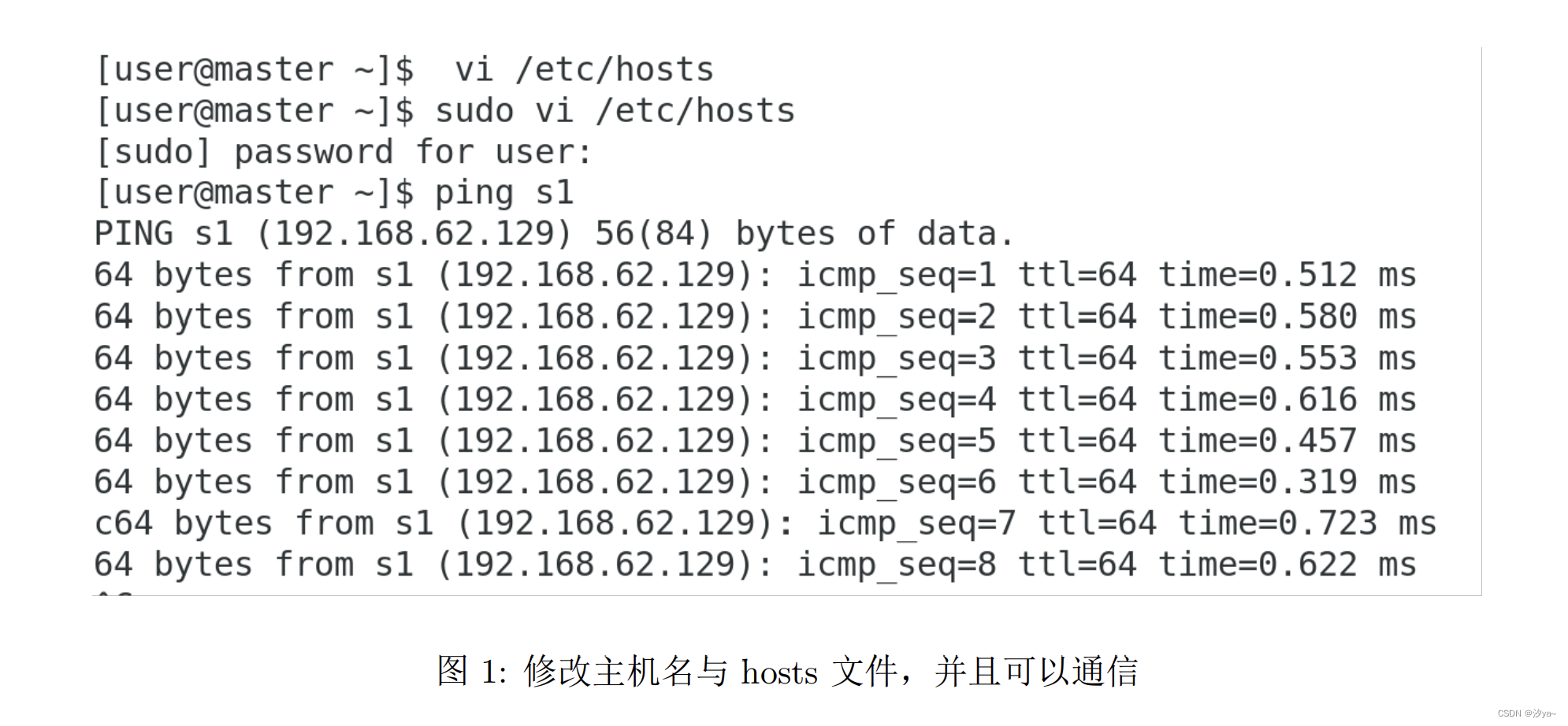
- 3.编辑 hosts 文件使三者之间能够通信,三台虚拟机都要进行的
# hosts 配置文件是用来把主机名字映射到IP地址的方法# 编辑hosts文件,进入编辑模式 i:sudo vi /etc/hosts# 在最后添加192.168.62.128 master192.168.62.129 s1192.168.62.130 s2
生成密钥
-
- 在主机上生成密钥, 三台主机都操作
ssh-keygen -b 1024 -t rsa

免认证登录
-
- 使 master 能免认证登录其他两个主机
#进入 .ssh目录中
cd .ssh
#id_rsa:私钥 id_rsa.pub :公钥
#在master中对s1和s2进行免密登录?需要把master的公钥放到s1和s2的authorized_key文件里
# 查看mster的公钥
cat id_rsa.pub
# 在master的.ssh目录中执行
ssh-copy-id s1
ssh-copy-id s2
ssh-copy-id master
# s1和s2之间免密登录
#在s1的.ssh目录中执行
ssh-copy-id s2
#在s2的.ssh目录中执行
ssh-copy-id s1
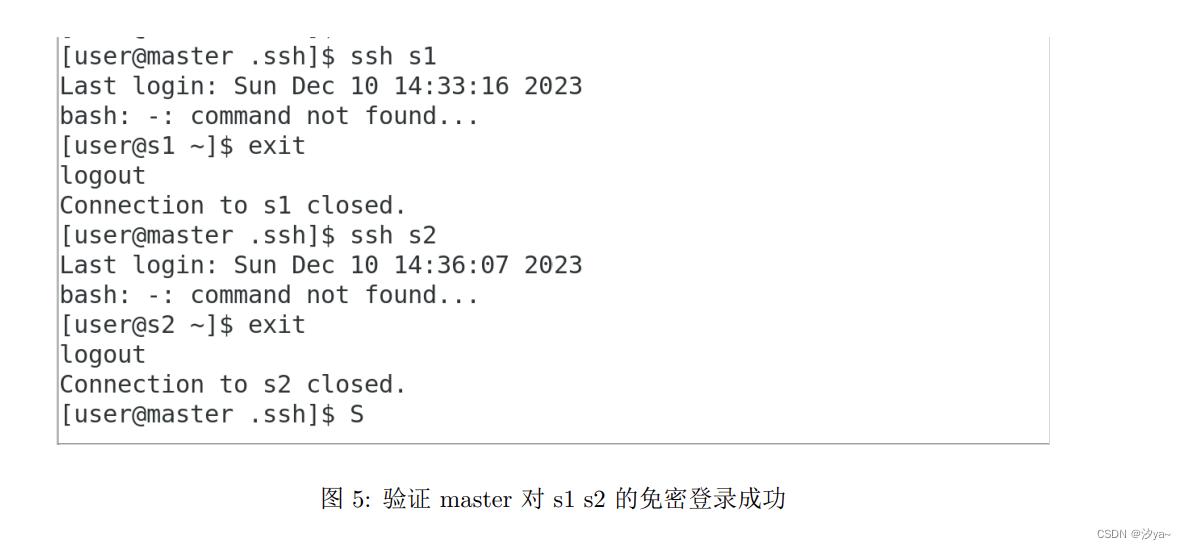
#在master验证能否免密登录
ssh s1

修改 hadoop 的配置文件
(注意各配置文件中配置的路径要修改成自己虚拟机实际的相关环境配置路径)
#进入Hadoop的/etc目录下。注意这个路径要根据自己虚拟机中Hadoop的安装路径修改
cd /home/user/usr/demo/hadoop-3.2.4/etc/hadoop
修改hadoop-env.sh文件
vim hadoop-env.sh
#修改JAVA_HOME的路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64
# 修改yarn-env.sh文件的JAVA_HOME。
vim yarn-env.sh
#修改JAVA_HOME的路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64
# 修改core-site.xml文件
vim core-site.xml
# 添加
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/user/demo/hadoop-3.2.4/tmp</value></property>
</configuration>
# 配置hdfs-site.xml
vim hdfs-site.xml
# 添加
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.permissions</name><value>false</value></property>
</configuration>
# 编辑mapred-site.xml文件
vim mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
# 编辑yarn-site.xml文件
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
编辑 workers 文件
# 编辑 workers 文件
vim workers
# 添加
master
s1
s2
复制配置后的 hadoop 目录传到从机上
scp -r /home/user/usr/demo/hadoop-3.2.4/ s1:/home/user/usr/demo/hadoop-3.2.4/
scp -r /home/user/usr/demo/hadoop-3.2.4/ s2:/home/user/usr/demo/hadoop-3.2.4/启动集群
-
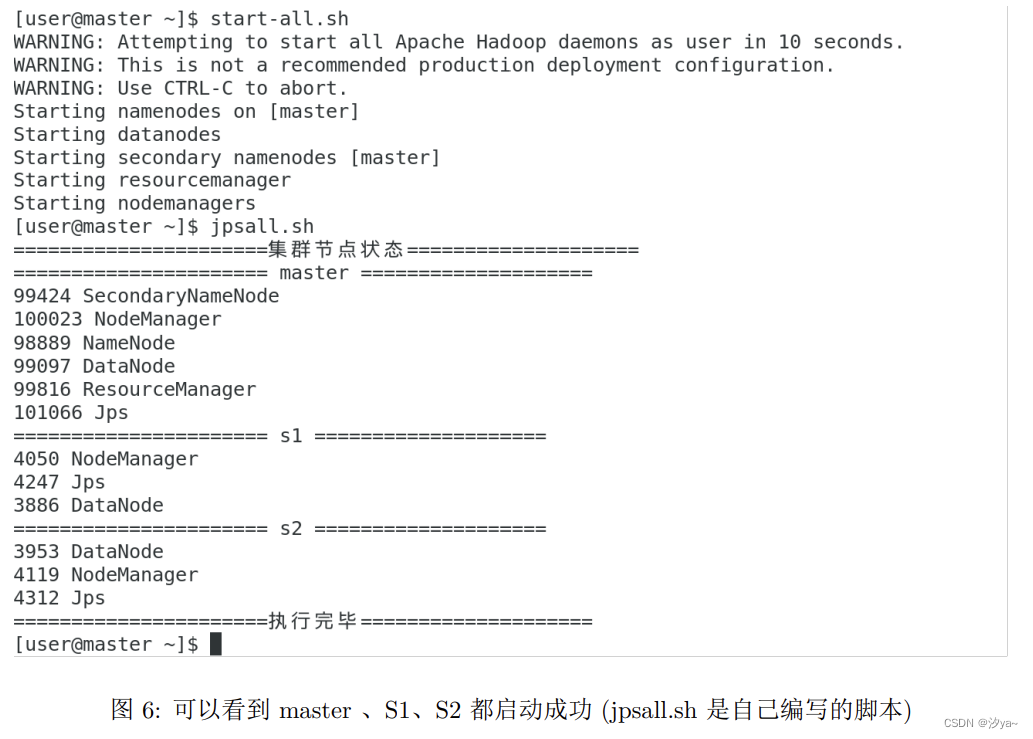
在 master 上面使用
start-all.sh启动
-
通过web端访问
http://master:8088/cluster查看当前集群的进程状态
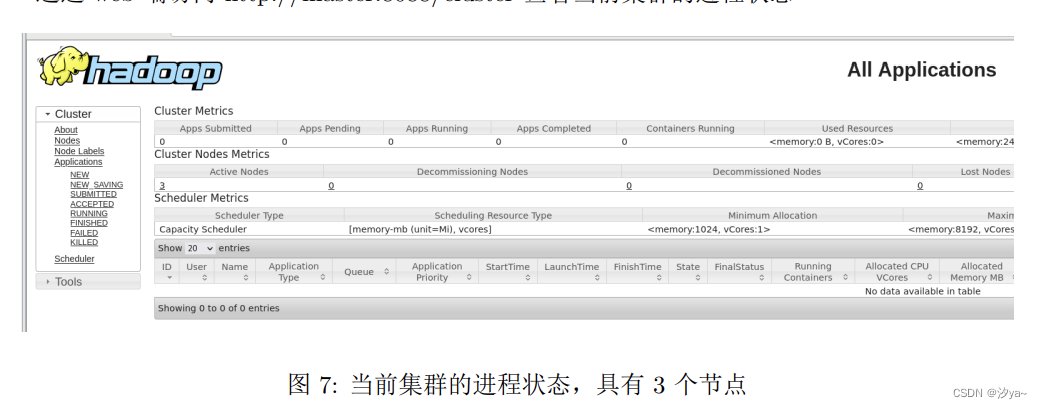
-
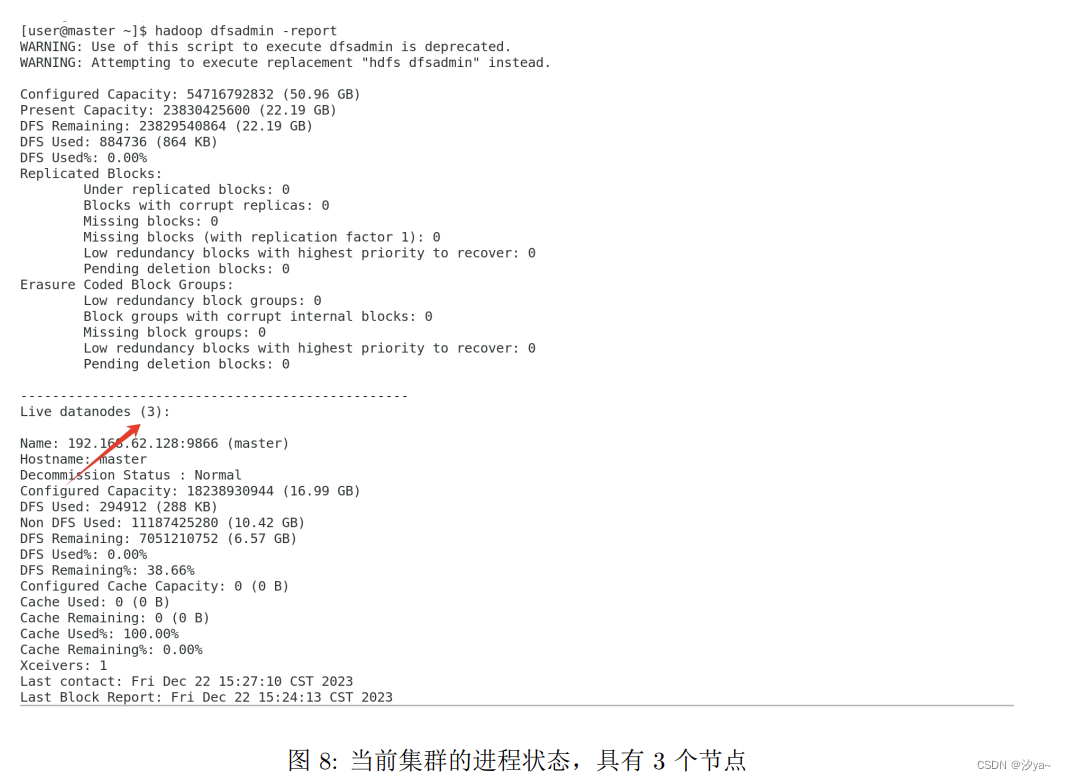
通过
hadoop dfsadmin -report查看当前集群的进程状态,具有3个节点
任务二之实验一 :编程实现合并文件MergeFile的功能
使用任务一搭建的集群,编程实现合并文件MergeFile的功能:将数据集trec06p_sample中的文件合并成为一个文件。假设集群的用户目录为hdfs://localhost:9000/user/hadoop,将合并的结果输出到hdfs://localhost:9000/user/hadoop/merge.txt 中
数据下载与上传至Hadoop
将数据集– trec06p_sample/126下载解压到虚拟机的Downloads目录下,并上传到集群的hdfs://master:9000/user/hadoop/目录下
# 解压
unzip trec06p_sample.zip -d trec06p_sample
#上传
hdfs dfs -put trec06p_sample /user/hadoop
#查看上传后的文件
hdfs dfs -ls -h /user/hadoop/trec06p_sample/126/

打开 eclipse
cd /usr/local/eclipse
./eclipse
编写实现合并文件MergeFile的功能的java代码
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;public class MergeAllFilesInDirectory {static class MyPathFilter implements PathFilter {public boolean accept(Path path) {return true; // 接受所有文件}}public static void main(String[] args) throws IOException {// 输入目录和输出文件路径String inputPath = "hdfs://master:9000/user/hadoop/trec06p_sample/126/";String outputPath = "hdfs://master:9000/user/hadoop/merge.txt";Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://master:9000");conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");FileSystem fsSource = FileSystem.get(URI.create(inputPath), conf);FileSystem fsDst = FileSystem.get(URI.create(outputPath), conf);// 获取目录下所有文件FileStatus[] sourceStatus = fsSource.listStatus(new Path(inputPath), new MyPathFilter());// 创建输出文件FSDataOutputStream fsdos = fsDst.create(new Path(outputPath));// 逐个读取文件并写入到输出文件中for (FileStatus status : sourceStatus) {FSDataInputStream fsdis = fsSource.open(status.getPath());byte[] data = new byte[1024];int read = -1;// 打印文件信息System.out.println("路径:" + status.getPath() + " 文件大小:" + status.getLen()+ " 权限:" + status.getPermission());while ((read = fsdis.read(data)) > 0) {fsdos.write(data, 0, read);}fsdis.close();}fsdos.close();fsSource.close();fsDst.close();}
}启动 Hadoop 并运行 Java 代码,合并文件
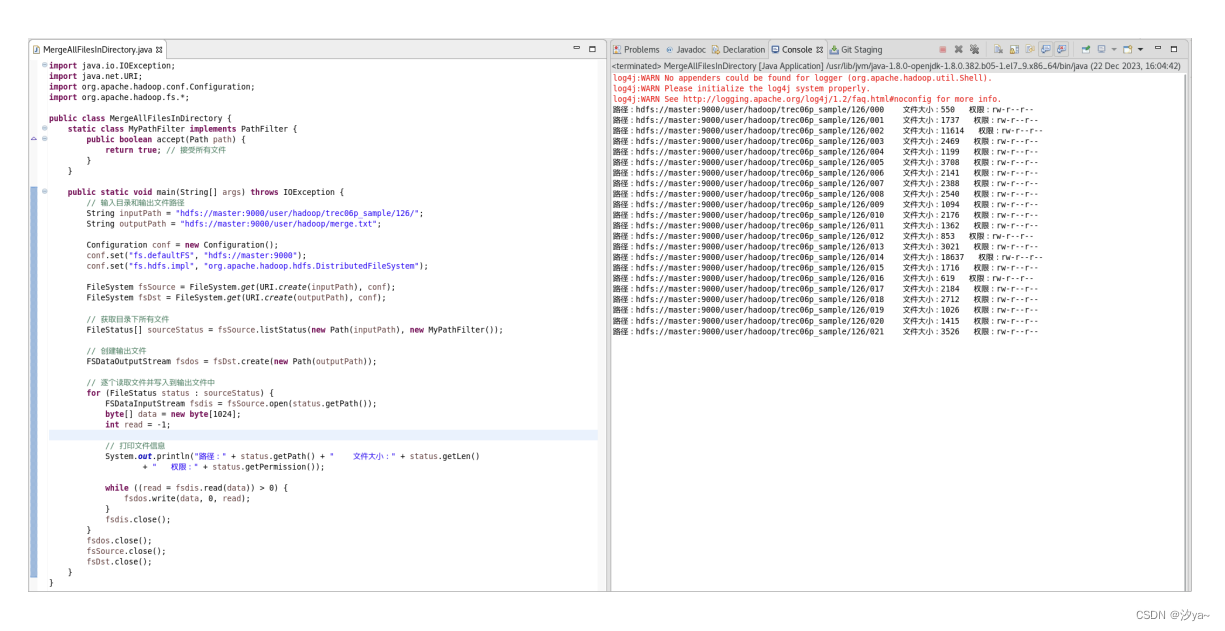
查看合并后的文件
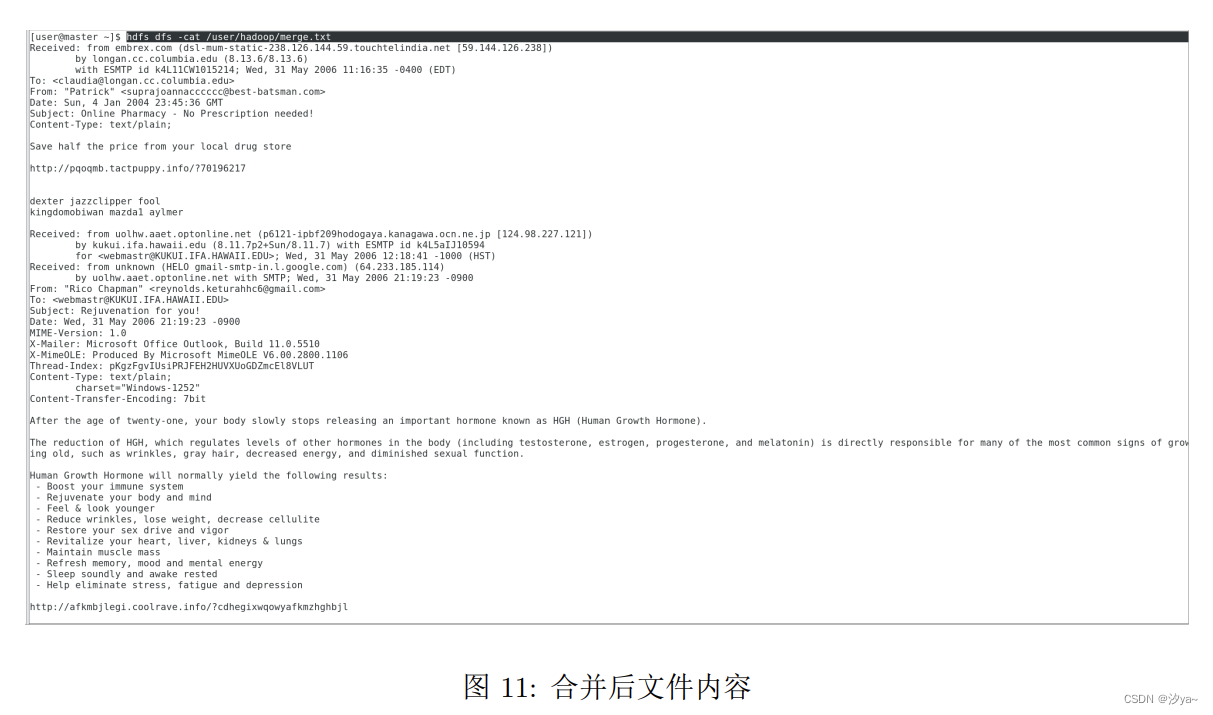
查看合并的结果:hdfs://localhost:9000/user/hadoop/merge.txt
通过web访问http://localhost:9870/explorer.html/user/hadoop,可以查看合并后的文件
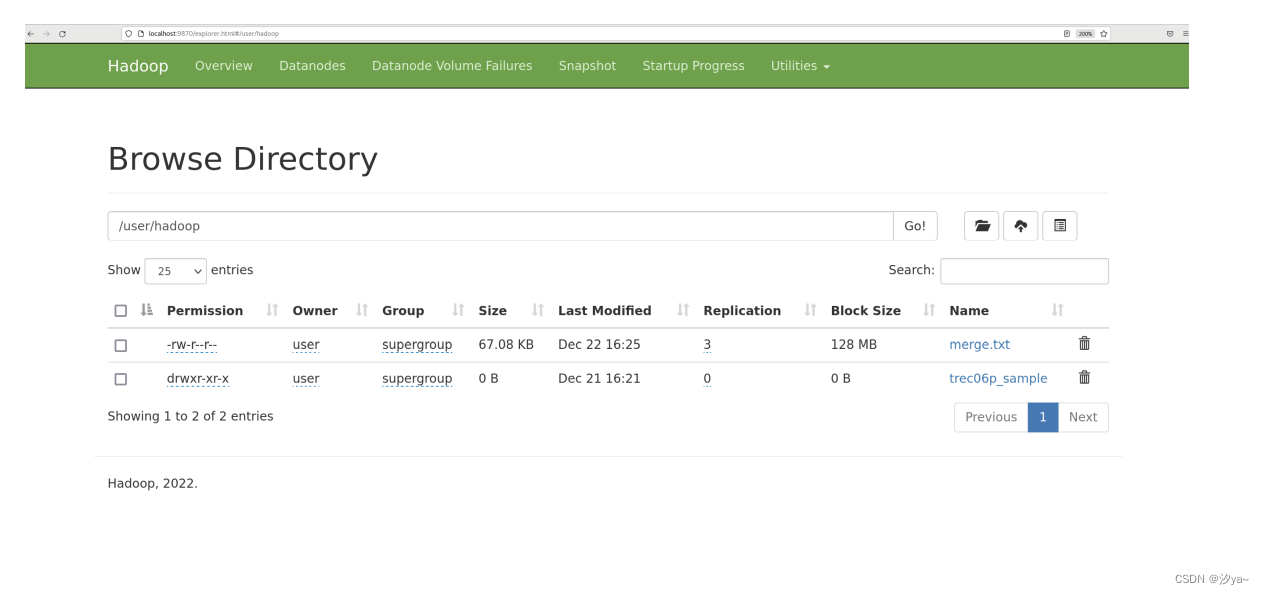
通过命令行使用 cat 命令查看合并后文件内容
hdfs dfs -cat /user/hadoop/merge.txt
任务二之实验二:对网站用户购物行为数据集进行统计分析
使用任务一搭建的集群,对网站用户购物行为数据集进行统计分析:
- 对用户的购物行为“behavior_type”进行统计,并将统计结果通过柱状图进行呈现
- 按月对用户的购物行为“behavior_type”进行统计,并将结果通过柱状图进行呈现
数据预处理
将数据集small_user下载解压到虚拟机的Downloads目录下,并上传到集群的hdfs://master:9000/user/hadoop/目录下
unzip small_user.zip //解压
head -5 small_user.csv //查看前几行
查看前 5 行记录,每行记录都包含 5 个字段如下:
- user_id(用户id)
- item_id(商品id)
- behaviour_type(包括浏览、收藏、加购物车、购买,对应取值分别是1、2、3、4)
- user_geohash(用户地理位置哈希值,有些记录中没有这个字段,且实验中不需要用到,后续把这个字段全部删除)
- item_category(商品分类)
- time(该记录产生时间)
head -5 small_user.csv

对用户的购物行为“behavior_type”进行统计,并将统计结果通过柱状图进行呈现
//首先在集群中安装R语言,然后通过运行下面R代码进行统计与可视化
# 读取数据
data <- read.csv("/home/user/Downloads/small_user.csv")# 统计用户行为类型
behavior_counts <- table(data$behavior_type)# 转换成数据框
behavior_data <- as.data.frame(behavior_counts)
names(behavior_data) <- c("Behavior_Type", "Count")# 绘制柱状图
library(ggplot2)ggplot(behavior_data, aes(x = factor(Behavior_Type), y = Count)) +
geom_bar(stat = "identity", fill = "gray", width = 0.1) + # 调整柱子宽度为0.5
labs(title = "User Behavior Count", x = "Behavior Type", y = "Count") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
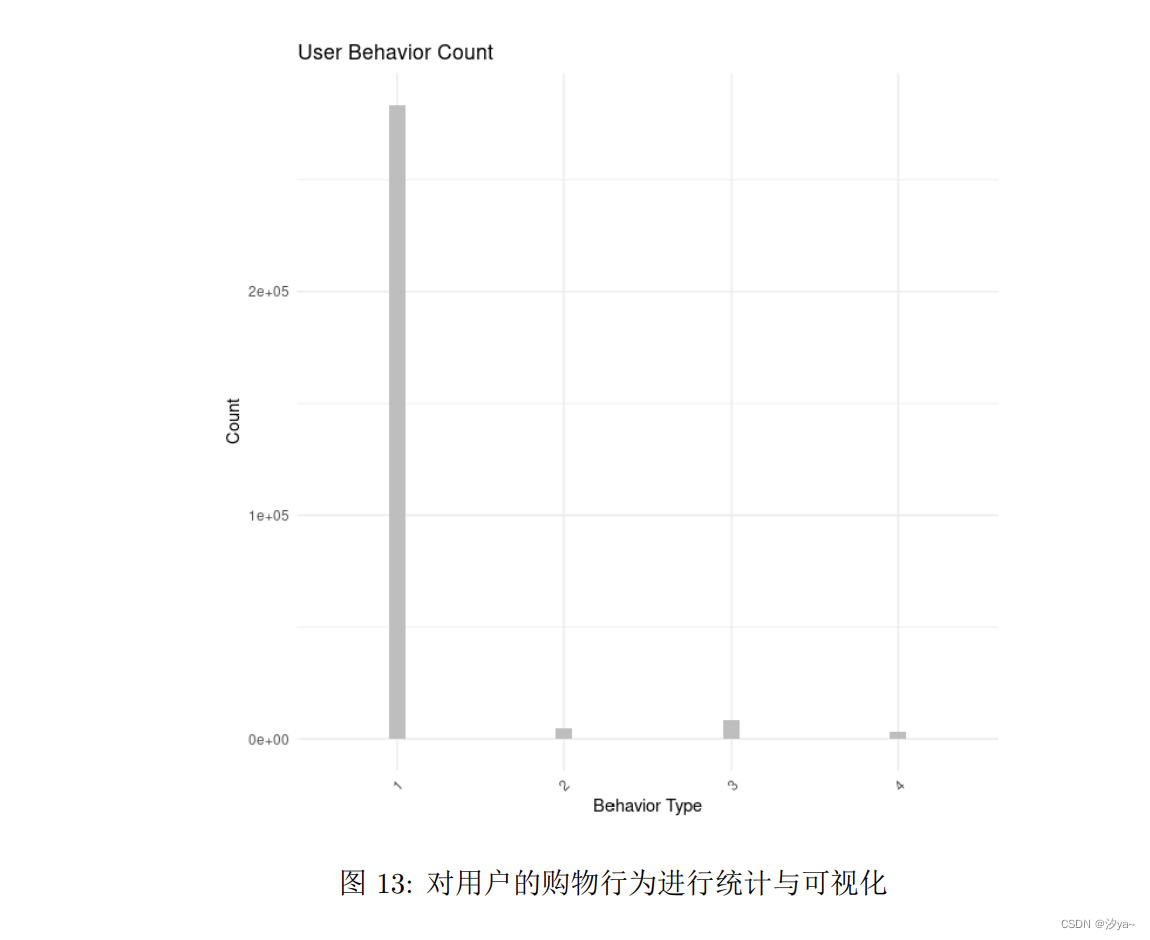
从上图可以得到:大部分消费者行为仅仅只是浏览。只有很少部分的消费者会购买商品。
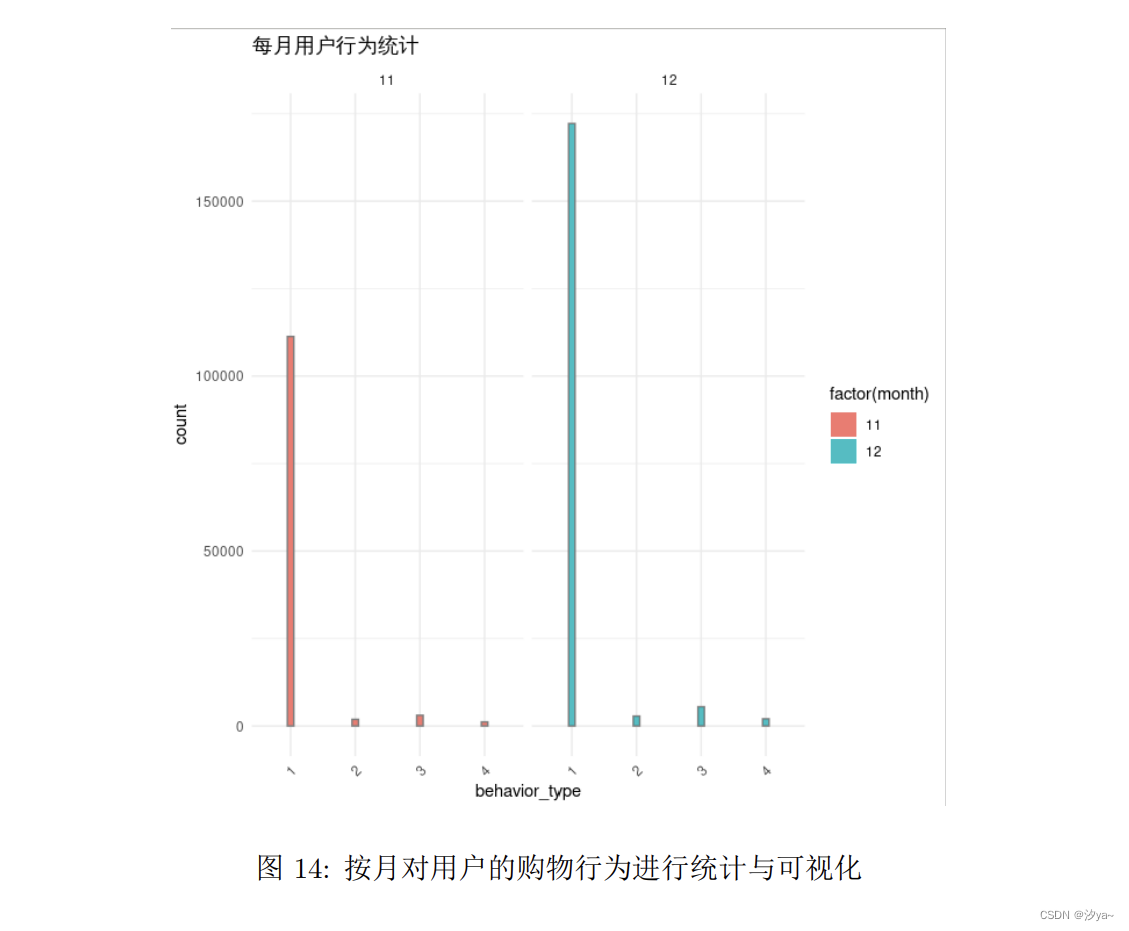
按月对用户的购物行为“behavior_type”进行统计,并将结果通过柱状图进行呈现
# 读取数据
data <- read.csv("/home/user/Downloads/small_user.csv")# 提取月份信息
data$month <- substr(data$time, 6, 7)# 使用ggplot绘制柱状图
library(ggplot2)ggplot(data, aes(x = factor(behavior_type), fill = factor(month), color = factor(month))) +
geom_bar(position = "dodge", width = 0.1) +
labs(title = "每月用户行为统计", x = "behavior_type", y = "count") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_color_manual(values = c("01" = "red", "02" = "blue")) +
guides(color = FALSE) +
facet_grid(. ~ month)
总结
本次实验深入探索了HDFS集群搭建及大数据处理技术的应用。成功地搭建了具有三个DataNode节点的HDFS集群,通过两种方式实现了该目标。在文件合并和统计分析实验中,我们编程实现了文件合并功能,并成功输出到HDFS指定路径。针对网站用户购物行为数据集,我们对用户行为进行了全面的统计分析,并通过柱状图清晰展现了购物行为的分布情况,为后续数据挖掘提供了可视化支持。这次实验不仅加深了对HDFS集群搭建的理解,也锻炼了在大数据环境下进行文件操作和数据分析的能力。未来的工作将进一步探索大数据技术,以更广泛的数据集和更复杂的分析挑战来拓展这些技能。
实验报告下载
下载
这篇关于【大数据处理技术实践】期末考查题目:集群搭建、合并文件与数据统计可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




