本文主要是介绍socket 编程(变态剖析)+超多案例 : 模拟Xshell执行远程命令, 模拟QQ聊天, 时间格式化服务器, 高效解决黏包方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引入
首先在前面储备知识中了解了OSI七层模型的工作原理以及TCP与UDP的区别之后, 下面的内容就非常容易理解了
一.客户端 / 浏览器与服务端架构
在了解 socket 之前我们先要知道什么是 C/S, 什么是 B/C? 我们知道软件之间的通信是基于计算机的三层结构 (应用程序、操作系统、计算机硬件) 来进行的, 而 C/S 和 B/S 是互联网软件通信的两种模式
-
C/S 指的是客户端软件(client)—服务端软件(server) : 我们学习 socket 就是为了完成 C/S 架构的开发
-
B/S 指的是浏览器(Browser)------服务端软件(server) : 也是 C/S 架构的一种
二.什么是 socket
Socket 也叫 “套接字”
想要完成一个基于网络通信的 C/S 架构, 那么你必须要知道一堆的网络协议, 因为这些协议是网络通信的核心, 而 socket 诞生之后你就不必为每个协议的细节而苦恼了, 它帮你完成了一些底层该做的事情, 看下图:
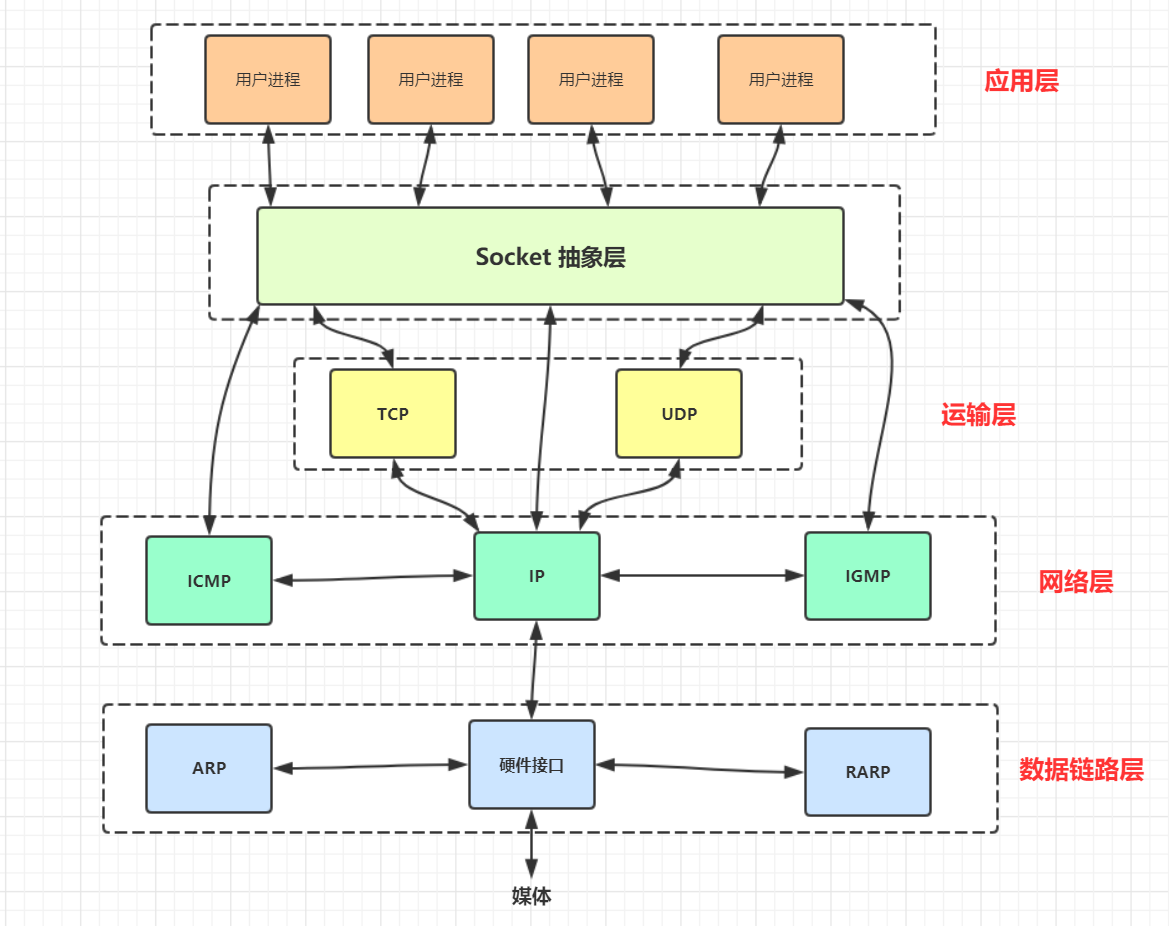
如图中所看到的:
Socket 是应用程与传输层及其以下层之间的抽象层, 它相当于一个门面, 将传输层及其以下部分复杂的 TCP/IP 协议族封装成简单的接口, 提供给应用层调用, 我们只需要遵循 socket 的规则去编写程序就自然遵循了网络通信协议
三.套接字的发展史以及分类
套接字起源于 20 世纪 70 年代加利福尼亚大学伯克利分校版本的 Unix,即人们所说的 BSD Unix。 因此,有时人们也把套接字称为“伯克利套接字”或“BSD 套接字”。一开始,套接字被设计用在同 一台主机上多个应用程序之间的通讯。这也被称进程间通讯,或 IPC。套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的
1.基于文件类型的套接字家族
- 套接字家族名称 : AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
2.基于网络类型的套接字家族
- 套接字家族名称 : AF_INET
AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET
3.传输协议类型
- 流式套接字 : SOCK_STREAM
流套接字用于提供面向连接、可靠的数据传输服务。该服务将保证数据能够实现无差错、无重复送,并按顺序接收。流套接字之所以能够实现可靠的数据服务,原因在于其使用了传输控制协议,即TCP协议
- 数据报套接字 : SOCK_DGRAM
数据报套接字提供一种无连接的服务。该服务并不能保证数据传输的可靠性,数据有可能在传输过程中丢失或出现数据重复,且无法保证顺序地接收到数据。数据报套接字使用UDP协议进行数据的传输。由于数据报套接字不能保证数据传输的可靠性,对于有可能出现的数据丢失情况,需要在程序中做相应的处理
- 原始套接字 : SOCK_RAW
原始套接字与标准套接字(标准套接字指的是前面介绍的流套接字和数据报套接字)的区别在于:原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取TCP协议的数据,数据报套接字只能读取UDP协议的数据。因此,如果要访问其他协议发送的数据必须使用原始套接
4.早期套接字的应用
早期套接字并不是用来网络通信的, 一般是用来处理一台计算机之上两个进程之间的相互通信
我们知道计算机开启两个进程, 申请的是内存的空间, 两个进程的内存空间是相互隔离的, 并且是物理隔离, 为的是保证数据的安全性, 那么进程与进程之间的数据是的不到交互的
但是硬盘是所有程序公用的, 于是就可以把一个进程的数据先写到硬盘中去, 让另一个进程从硬盘中取, 这样就实现了进程与进程之间的数据交互
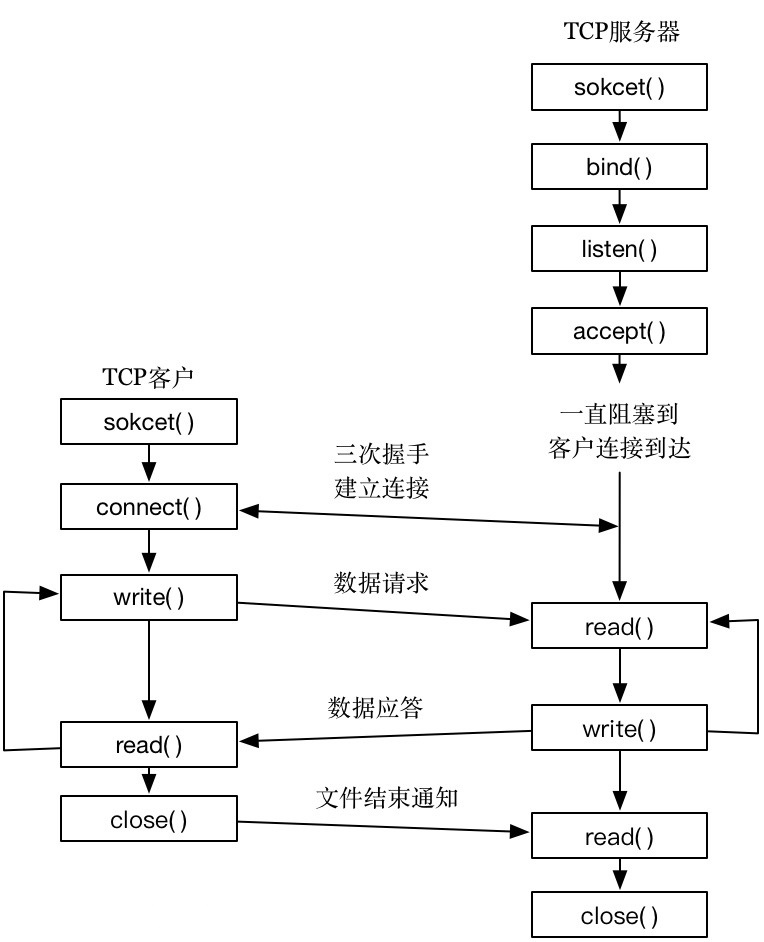
四. 套接字的工作流程
客户端与服务端之间的连接过程主要可以分为四个步骤
1.服務器绑定 IP + Port 并建立监听
客户端初始化Socket动态库后创建套接字,然后指定客户端Socket的地址,循环绑定Socket直至成功,然后开始建立监听,此时客户端处于等待状态,实时监控网络状态
2.客户端向服务端发送请求
客户端的Socket向服务器端提出连接请求,此时客户端描述出它所要连接的Socket,指出要连接的Socket的相关属性,然后向服务器端Socket提出请求
3.连接请求确认并建立
当服务器端套接字监听到来自客户端的连接请求之后,立即响应请求并建立一个新进程,然后将服务器端的套接字的描述反馈给客户端,由客户端确认之后连接就建立成功
4.连接建立成功之后进行数据收发
然后客户端和服务器两端之间可以相互通信,传输数据,此时服务器端的套接字继续等待监听来自其他客户端的请求(下面会一步步实现)
五.Socket 模块的常用函数(方法)
1.Socket 的实例化 (得到一个套接字对象)
-
格式 :
socket(family, type, protocal=0) -
三个参数 : 1.常用协议族, 2.socket 类型, 3.指定的协议(默认0)
- AF_INET(默认值)、AF_INET6、AF_UNIX、AF_ROUTE等
- SOCK_STREAM(TCP类型)(默认值)、SOCK_DGRAM(UDP类型)、SOCK_RAW(原始类型)
- 通常不写, 默认为"0", 使用默认的协议和类型:
s=socket.socket() # 等同于下面 socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 等同于上面 s=socket.socket(socket.AF_INET,socket.SOCK_DGRAM) # 如果想用UDP就得这样写
2.服务端套接字函数
| 函数 | 说明 |
|---|---|
| s.bind() | 绑定地址(host,port)到套接字, 在AF_INET下,以元组(host,port)的形式表示地址 |
| s.listen() | 开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量,该值至少为1,一般为5就够用了 |
| s.accept() | 被动接受TCP客户端连接,(阻塞式)等待连接的到来 |
3.客户端套接字函数
| 函数 | 说明 |
|---|---|
| s.connect() | 主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误 |
| s.connect_ex() | connect()函数的扩展版本,出错时返回出错码,而不是抛出异常 |
4.公共用途的套接字函数
| 函数 | 说明 |
|---|---|
| s.recv() | 接收TCP数据,数据以字符串形式返回,缓冲区(bufsize)指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略 |
| s.send() | 发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小(提示: 在输入空的时候小于) |
| s.sendall() | 完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常 |
| s.recvfrom() | 接收UDP数据,与recv()类似,但返回值是(data_bytes,address)。其中data_bytes是接收的bytes类型的数据,address是发送数据的地址, 以元组(‘IP’, port)形式表示 |
| s.sendto() | 发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数 |
| s.close() | 关闭套接字 |
| s.getpeername() | 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port) |
| s.getsockname() | 返回套接字自己的地址。通常是一个元组(ipaddr,port) |
| s.setsockopt(level,optname,value) | 设置给定套接字选项的值。 |
| s.getsockopt(level,optname[.buflen]) | 返回套接字选项的值。 |
5.面向锁的套接字方法
| 函数 | 说明 |
|---|---|
| s.setblocking(flag) | 如果flag为0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值),非阻塞模式下,如果调用recv()没有发现任何数据,或send()调用无法立即发送数据,那么将引起socket.error异常 |
| s.settimeout(timeout) | 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) |
| s.gettimeout() | 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None |
6.面向文件的套接字函数
| 函数 | 说明 |
|---|---|
| s.fileno() | 返回套接字的文件描述符 |
| s.makefile() | 创建一个与该套接字相关连的文件 |
六.基于TCP实现的套接字
TCP 基于连接通信, 所以必须先启动服务端, 在启动客户端
1.模拟打电话简单通信连接
- 服務端
import socket🍓买手机
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 第一个参数,是基于网络套接字, 第二个是种类:tcp称为流式协议,udp称为数据报协议(SOCK_DGRAM)🍓插卡/绑卡(绑定地址和端口号)
phone.bind(('127.0.0.1', 8060))
# 一个元组,这里绑定的是一个本机回环地址,只能本机和本机通信,一般用于测试阶段🍓开机 (处于监听状态)
phone.listen(5)
# 5 是设置的半连接池,限制的是请求数,只能同时与一台客户机通信,其它的挂起🍓等待电话连接(等待客户机的请求连接)
print('等待连接...')
conn, client_addr = phone.accept()
# (conn:三次握手建立的链接,client_addr:客户端的 IP 和端口)print(conn)
print(client_addr)🍓开始通信:收/发消息
data = conn.recv(1024) # 最大接受的字节数1024
print('来自客户端的数据:', data)
conn.send(data.upper()) # 返回数据🍓挂掉电话连接 (关闭连接)
conn.close()🍓关机 (关闭服务器)
phone.close()
- 客户端
import socket🍓买手机
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
print(phone)🍓拨电话 (客户端地址会变,不需要绑定地址)
phone.connect(('127.0.0.1', 8060))
# 指定服务器 IP 和端口,一个元组,这里是客户机与服务端建立连接🍓开始通信:发/收消息, 通信循环
while True: msg = input('请输入消息>>').strip()if len(msg) == 0:continuephone.send(msg.encode('utf-8'))data = phone.recv(1024) # 最大接受字节数1024print(data.decode("utf-8"))🍓关闭客户端
phone.close()
- 问题 : 重启服务端报错
Address already in uer(端口被占用) 解决方法
🍓在 bind( ) 函数之前加上一条'socket'配置
phone.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) # 表示重用 ip 和 端口🍓或者更改服务端端口号
2.tcp 实现一个简单聊天程序
一来一回, 并且一个连接断开才可以连接下一个
- 服务端
import socketphone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
phone.bind(('127.0.0.1', 8060))
phone.listen(5)while True:print('start recv...')conn, client_addr = phone.accept()print(f"鏈接了一个客户端{client_addr}")while True:try:data = conn.recv(1024)if len(data) == 0: breakprint(f'来自客户的数据:\033[1;30;46m{data.decode("utf-8")}\033[0m')user = input("请输入发送内容(q退出)>>")if user.lower() == "q":breakconn.send(user.encode("utf-8"))except ConnectionResetError:breakconn.close()
- 客户端
import socketphone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
phone.connect(('127.0.0.1', 8060))while True:msg = input('输入发送内容(q退出)>>').strip()if msg.lower() == "q":breakif len(msg) == 0:continuephone.send(msg.encode('utf-8'))data = phone.recv(1024)print(f"来自派大星的消息 : \033[1;30;46m{data.decode('utf-8')}\033[0m")phone.close()
3.tcp 模拟xshell实现远程执行命令
有一些功能无法实现 : cd 等
- 服务端
from socket import *
import subprocessserver = socket(AF_INET,SOCK_STREAM)
server.bind(("127.0.0.1",8090))
server.listen(5)while 1:print("等待连接...")conn,addr = server.accept()print(f"来自{addr}的连接")while 1:try:cmd = conn.recv(1024)# 运行系统命令obj = subprocess.Popen(cmd.decode("utf-8"),shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE,)stdout = obj.stdout.read()stderr = obj.stderr.read()date = stdout + stderrconn.send(date) # 返回命令执行的结果except Exception:breakconn.close()
- 客户端
from socket import *client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))while True:cmd = input('>>').strip()if len(cmd) == 0: continuedata = client.recv(1024)print(data.decode('gbk'))
当接收的数据超过1024字节, 我们只能接收1024字节, 可以在客户端调高最大接收量, 但这并不是我们的解决方案, 于是我们就可以对接收的字节进行循环接收, 直到接收完为止
- 客户端循环接收数据
from socket import *client = socket(AF_INET,SOCK_STREAM)
client.connect(("127.0.0.1",8090))while True:cmd = input("cmd >>").strip()if len(cmd) == 0:continueclient.send(cmd.encode("utf-8"))while 1:date = client.recv(1024)print(date.decode("utf-8"),end="")if len(date) < 1024: break # 当接收的字节小于1024,则代表这次能收干净
九.基于 UDP 实现的套接字
udp 是无连接的, 所以县启动哪一段都没有关系
1.udp 实现与多个用户通信
可回多个客户端的信息, 回完一个紧接着可回下一个, 不需要连接
- 服務端
server = socket(AF_INET,SOCK_DGRAM)
server.bind(("127.0.0.1",8087))
while 1:msg,addr = server.recvfrom(1024)print(f'来自{addr[0]}的消息:{msg.decode("utf-8")}')inp = input("请输入发送内容>>").strip()server.sendto(inp.encode("utf-8"),addr)
- 客户端1
from socket import *client = socket(AF_INET,SOCK_DGRAM)
while 1:msg = input("请输入发送内容>>").strip()if len(msg) == 0:continueclient.sendto(msg.encode("utf-8"),("127.0.0.1",8087))msg,addr = client.recvfrom(1024)print(f'对方的消息 : {msg.decode("utf-8")}')
- 客户端二
from socket import *client = socket(AF_INET,SOCK_DGRAM)
while 1:msg = input("请输入发送内容>>").strip()if len(msg) == 0:continueclient.sendto(msg.encode("utf-8"),("127.0.0.1",8087))msg,addr = client.recvfrom(1024)print(f'对方的消息 : {msg.decode("utf-8")}')
2.udp实现时间格式化服务器
- 服务端
from socket import *
from time import strftimeserver = socket(AF_INET,SOCK_DGRAM)
server.bind(("127.0.0.1",8089))print("start recv....")
while True:msg,addr = server.recvfrom(1024)print(f"[{addr[0]}]连接成功")if not msg:fmt = "%Y-%m-%d %X"else:fmt = msg.decode("utf-8")time_fmt = strftime(fmt)server.sendto(time_fmt.encode("utf-8"),addr)
- 客户端
from socket import *client = socket(AF_INET,SOCK_DGRAM)print("输入时间格式, 返回格式化后的时间")
while True:inp = input("请输入时间格式(例:%Y %m %d)>>").strip()client.sendto(inp.encode("utf-8"),("127.0.0.1",8089))date = client.recv(1024)print(date.decode("utf-8"))
十.字符编码问题
使用 subprocess 模块执行系统命令得到的结果是字节,并且是是以当前平台的编码为准, 值得注意的是 : 在Windows平台上读出来的内容是 GBK 编码的, 在接收时就需要使用 GBK 解码, 且从管道里只能读一次结果
十一.黏包现象
ps : 只有 TCP 才会出现黏包现象, UDP 不会出现黏包现象
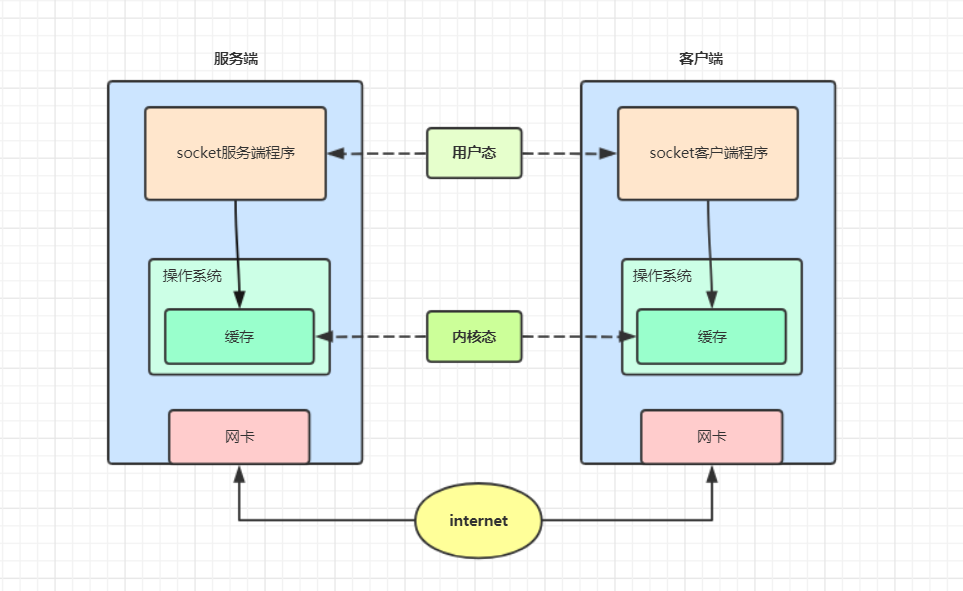
0.socket收发消息原理
其实我们发送数据并不是直接发送给对方, 而是应用程序将数据发送到本机操作系统的缓存里边, 当数据量小, 发送的时间间隔短, 操作系统就会在缓存区先攒够一个TCP段再通过网卡一起发送, 接收数据也是一样的, 先在操作系统的缓存存着, 然后应用程序再从操作系统中取出数据
1.为什么产生黏包
- 主要原因 : TCP称为流失协议, 数据流会杂糅在一起, 接收端不清楚每个消息的界限, 不知道每次应该去多少字节的数据
- 次要原因 : TCP为了提高传输效率会有一个nagle优化算法, 当多次send的数据字节都非常少, nagle算法就会将这些数据合并成一个TCP段再发送, 这就无形中产生了黏包
2.产生黏包的两种情况 :
- 发送端需要等待缓冲区满了才将数据发送出去, 如果发送数据的时间间隔很短, 数据很小, 就会合到一起, 产生黏包
- 接收方没有及时接收缓冲区的包, 造成多个包一起接收, 如果服务端一次只接收了一小部分, 当服务端下次想接收新的数据的时候, 拿到的还是上次缓冲区里剩余的内容
3.通过send数据长度的方式来控制接收 (解决黏包问题的方式)
- 服务端
from socket import *
import subprocessserver = socket(AF_INET,SOCK_STREAM)
server.bind(("127.0.0.1",8090))
server.listen(5)while 1:print("等待连接...")conn,addr = server.accept()print(f"来自{addr}的连接")while 1:try:cmd = conn.recv(1024)obj = subprocess.Popen(cmd.decode("utf-8"),shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE,)stdout = obj.stdout.read()stderr = obj.stderr.read()date = stdout + stderrdate_len = str(len(date)).encode("utf-8") # 得到数据长度conn.send(date_len) # 将数据的长度先发送conn.send(date) # 再发送真实数据except Exception:breakconn.close()
- 客户端
from socket import *client = socket(AF_INET,SOCK_STREAM)
# client.connect(("192.168.12.222",8090))
client.connect(("127.0.0.1",8090))while True:cmd = input("cmd >>").strip()if len(cmd) == 0:continueclient.send(cmd.encode("utf-8"))date_len = int(client.recv(1024).decode("utf-8")) # 先接收数据长度recv_len = 0while 1:date = client.recv(1024)recv_len += len(date)print(date.decode("gbk"),end="")if recv_len == date_len: break # 当数据长度与接收到的数据长度相等则结束
效率低 : 程序运行的速度远快于网络传输的速度, 如果在发送真实数据之前先send该数据的字节流长度, 那么就会放大网络延迟带来的性能损耗
4.使用 struct 模块实现精准数据字节接收 (比较高效解决tcp协议的黏包方法)
高效在哪? 为字节流加上一个自定义固定长度的报头, 报头中就包含了该字节流长度, 然后只需要将整个数据加报头 send 一次到对端, 对端先取出固定长度的报头, 然后在取真实的数据
struct 模块在前面章节我对它的使用做了简单介绍👉🏻struct 传送门
- 服务端
from socket import *
import subprocess
import struct
import jsonserver = socket(AF_INET, SOCK_STREAM)
server.bind(('127.0.0.1', 8080))
server.listen(5)while True:print('connection....')conn, client_addr = server.accept()print('已经连接:', client_addr)while True:try:cmd = conn.recv(1024)if len(cmd) == 0: breakobj = subprocess.Popen(cmd.decode('utf-8'),shell=True,stderr=subprocess.PIPE,stdout=subprocess.PIPE)stdout = obj.stdout.read()stderr = obj.stderr.read()# 制作一个报头字典(模板)header_dic = {'header_name': 'shawn','total_size': len(stderr) + len(stdout),'heash': 'songhaixing',}# 将报头(字典)序列化成字符串类型header_json = json.dumps(header_dic)# 将报头(字符串)转换成byte类型header_byte = header_json.encode('utf-8')# 将报头信息打包成4字节大小,里面包含的报头的长度header_size = struct.pack('i', len(header_byte))# 先发送打包的4bytes,4bytes包含了报头长度conn.send(header_size)# 再发送报头(客户端已经拿到了(解包出)报头的长度)conn.send(header_byte)# 发送真实数据data = stdout + stderrconn.send(data)# 可以合并到一起只send一次,但字符拼接又降低了效率(不推荐)# msg = header_size + header_byte + stdou t+ stderr # conn.send(msg)except Exception:breakconn.close()
🔰疑问 : 前面说到多次send会扩大网络延迟带来的效率问题, 那为什么还要分四次 send ?
其实在前面 socket 收发消息的原理图哪里就给出了答案, 数据先是发送到自己操作系统的缓存内, 时间间隔短, 数据量小的会被合在一起在发送, 这就是TCP协议nagle优化算法做的事(有提升效率的功能,当然也带来了黏包问题)
- 客户端
from socket import *
import json
import structclient = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))while True:cmd = input('请输入命令>>').strip()if len(cmd) == 0: continueclient.send(cmd.encode('utf-8'))# 接收byte_4byte_4 = client.recv(4)# 解包出报头长度header_len = struct.unpack('i', byte_4)[0]# 使用长度接收byteheader_byte = client.recv(header_len)# byte---->strheader_str = header_byte.decode('utf-8')# str---->dicheader_dic = json.loads(header_str)# 拿到真正数据的大小total_size = header_dic['total_size']recv_size = 0while 1:data = client.recv(1024)recv_size += len(data)print(data.decode('gbk'),end="")if recv_size == total_size:break
5.udp 没有黏包问题
udp 被称为数据报协议, 每次发送的数据都是一个数据报, 一次 sendto 对应一次 recvfrom, 不会产生黏包
udp 又被称为不可靠协议, 不可靠在哪里? 比如发送方发送了 10bytes 的数据, 而接收方只接收 8bytes 的数据, 那么剩下的两个 bytes 将会被丢弃, 并且在不同的平台有不同的表现, 下面我们来进行试验 :
- Windows 平台下试验客户端
from socket import *client = socket(AF_INET,SOCK_DGRAM)msg = "1234567890".encode("utf-8") # "utf-8"编码格式的数字和字母都是1bytes
msg2 = "12345".encode("utf-8") # 发送 5bytes
msg3 = "123".encode("utf-8") # 发送 3bytesclient.sendto(msg,("127.0.0.1",8989))
client.sendto(msg2,("127.0.0.1",8989))
client.sendto(msg3,("127.0.0.1",8989))
- 服务端
from socket import *server = socket(AF_INET,SOCK_DGRAM)
server.bind(("127.0.0.1",8989))date,addr = server.recvfrom(8) # 发送方发送 10bytes 只接收 8bytes
date2,addr2 = server.recvfrom(3) # 发送方发送 5bytes 只接收 3bytes
date3,addr3 = server.recvfrom(1) # 发送方发送 3bytes 只接收 1bytesprint(date.decode("utf-8"))
print(date2.decode("utf-8"))
print(date3.decode("utf-8"))
- 运行结果

- Linux 平台运行下试验客户端
from socket import *client = socket(AF_INET,SOCK_DGRAM)msg = "1234567891".encode("utf-8")
msg2 = "12345".encode("utf-8")
msg3 = "123".encode("utf-8")client.sendto(msg,("192.168.12.222",8989))
client.sendto(msg2,("192.168.12.222",8989))
client.sendto(msg3,("192.168.12.222",8989))
- 服务端
from socket import *server = socket(AF_INET,SOCK_DGRAM)
server.bind(("192.168.12.222",8989))date,addr = server.recvfrom(8)
date2,addr2 = server.recvfrom(3)
date3,addr3 = server.recvfrom(1)print(date.decode("utf-8")) # 注意:如果发送方发送的是汉字, 一个汉字三个字节, 如果接受不完整解码出来会报错
print(date2.decode("utf-8"))
print(date3.decode("utf-8"))
- 运行结果

发现只接收了最大接收量, 剩余的字节被丢弃了
十二.socketserver实现并发
下一篇介绍如何使用 socketserver 模块实现并发效果
这篇关于socket 编程(变态剖析)+超多案例 : 模拟Xshell执行远程命令, 模拟QQ聊天, 时间格式化服务器, 高效解决黏包方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



