本文主要是介绍「翻译」Flexible and Feasible Support Measures for Mining Frequent Patterns in Large Labeled Graphs,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在大标签图中挖掘频繁模式的灵活可行的方法
Jinghan Meng
南佛罗里达大学计算机科学与工程系
jmeng@mail.usf.edu
Yi-Cheng Tu ∗
南佛罗里达大学计算机科学与工程系
tuy@mail.usf.edu
摘要
近年来,图数据库的热度迅速增长。本文着重于将单图作为一种有效模型来表示信息和其相关图的挖掘的技术。在单图情况下的频繁模式挖掘中,存在两个主要问题:支持方法和搜索方案。本文提出了一种新的支持方法的构建框架,可以将现有的基于最小图和基于重叠图的支持方法结合起来。我们的框架基于出现/实例超图的概念。在此基础上,结合现有方法的优点,提出了两种新的支持方法:最小实例测度minimum instance (MI)方法和最小顶点覆盖测度minimum vertex cover (MVC)方法。特别地,我们证明了现有的基于最小图像的支持方法是MI方法的上界,它也是线性时间可计算的,并且导致接近模式实例数的计数。虽然MVC方法是NP难问题,但它可以在多项式时间内近似为一个常数因子。我们还为两种方法提供了多项式时间的松弛措施并且对所有现今存在的超图情况下的方法给出了边界定理。我们进一步证明了基于超图的框架能够统一本文研究的所有支持方法。该框架还具有灵活性,因为在其中可以定义更多支持方法来构造其变体。
关键词
数据挖掘;图挖掘;支持方法;超图
- 介绍
图在复杂结构的建模中变得越来越重要,如化合物、双分子结构、社交网络、航空地图和网络。近年来,人们对挖掘图数据库中的兴趣模式进行了深入的研究。这类工作通常涉及计算特殊模式(即子图)的频率。正如许多问题所显示的那样,频繁模式被认为可以揭示建模系统的基本特征。任何频繁模式挖掘问题的明确定义都取决于支持方法作为兴趣模式频率的概念。1在基于事务的频繁模式挖掘设置中,支持方法的开发非常简单,因为我们只需要计算包含查询参数的单个图(在图形数据库中)。这个问题在单图情况中更有趣且更具挑战性,在这个图表中,频繁模式只能在一个通常由大量顶点和边组成的图表中找到。
在单图环境中,支持方法的设计是非常重要的,因为这种方法必须满足几个需求。例如,一个模式支持的明显定义是它在输入图中出现的次数(参见第2节中的更多详细信息)。但是,此定义具有这样一个特点:当扩展至具有更多边/顶点的图时,代价可能会增加。不难看出这样的特性是不可取的:当查询模式增长时,搜索变得更具选择性,因此代价应该减少。首先由Vanetik等人提出。[16]抗单调性作为支持方法设计的一项基本准则,得到了图形挖掘界的广泛认可。Vanetik等人[16]还提出了一种反单调支持方法,称为最大独立集支持(MIS)。MIS建立在一个重要的概念上,即重叠图,它是一个由原始图(数据库)中的查询模式实例作为顶点和边缘等实例的重叠组成的图。MIS的主要问题是缺乏有效的算法——它被证明是NP难的。它的扩展(例如Calders等人开发的最小集团划分(MCP)方法)。[3])也会产生同样的问题。
另一种支持方法称为基于最小图像支持(MNI)方法[2]是基于顶点图像技术的作为另一种反单调支持,MNI只需要线性时间来计算。然而,由于缺乏直观性,MNI支持存在严重短板。具体地说,忽略查询模式的拓扑结构和出现的部分重叠,MNI会任意地高估模式的频率,降低了其实际应用价值。基于重叠图的支持(以MIS表示)和MNI支持及其变体代表了频繁图挖掘中定义支持方法的两个主要工作主体。虽然两者都是反单调的,但它们却一个具有直观性一个具有效率性。因此,本研究的主要目标是开发新的支持方法,结合两种方法的优点:它们是快速的(线性/多项式时间),避免了计算错误支持方法的高成本,以及直观的,没有像在基于MNI的方法中那样过多的计数模式。
在本文中,我们首先介绍了出现/实例超图的概念,它是基于模式的出现或实例构建的图。基于超图概念,我们定义了两种新的支持方法:最小实例(MI)方法和最小顶点覆盖(MVC)方法。对于MI支持方法,我们证明,现有的MNI方法是它的上界,换句话说,它比MNI更接近MIS对于模式的支持。与MNI一样,MI也是线性时间可计算的。MVC返回的频率甚至更接近MIS。虽然计算MVC方法是NP难的,但MVC具有k-竞争近似算法。此外,我们还提供了MVC和MIS方法的多项式可计算松弛。这使得MVC和MIS更加高效,同时仍然提供有意义的频率值。
我们进一步证明,我们新的基于超图的方法是一个统一的框架,它不仅封装了MI和MVC,还封装了包括MIS和MNI在内的现有支持方法。具体地说,我们首先证明在超图情况下有一个自然的MNI映射。对于MIS,我们证明它与实例超图(即最大独立边缘集(MIES))中定义的支持方法是等效的(在值和计算复杂性方面)。文中还提出了描述基于超图框架中所有支持方法之间差异的边界定理。为了总结本文的主要结论,我们分别将MIS、MIES、MIES和MVC的多项式松弛值、MVC、MI、MNI表示为σMIS、σMIES、νMIES、νMVC、σMVC、σMI、σMNI。所有上述支持方法束和计算复杂性如下。

此外,我们还展示了新框架作为一个平台可用于定义和支持各种支持方法的潜力。图1是超图框架的示意图,在一个小的数据图中显示了一个边缘模式的支持方法计数。
简而言之,在超图框架中,模式在数据图中的出现被视为边。从MIS支持方法和MVC支持方法的角度来看,将边中的顶点视为一个集合,分别使用最大独立边集和最小顶点覆盖集的基数作为支持方法。MNI和MI支持方法将边分解为子边(子集),然后采用子边的最小清晰图计数作为支持。通过这种方式,MNI和MI支持方法将计算复杂性降低到线性时间(以出现次数为单位)。
本文的其余部分组织如下:在第2节中,我们正式解决了问题,并概述了问题的必要背景;在第3节中,我们介绍了新的支持方法,并研究了它们的特点;在第4节中,我们提出

图1:显示模式和超图框架的支持方法的示例。在这种情况下,我们有σMIS=2≤σMVC=3≤σMI=4≤σMNI=5
了一个框架,统一了本文中提到的所有支持方法,并讨论了其潜力。定义和研究各种支持方法;在第5节中,我们简要回顾了相关工作;在第6节中,我们总结了本文。
- 准备工作
在这一部分中,我们将介绍基本的符号来描述这个问题和必要的背景。
2.1标签图
在本文中,我们只考虑一个有标号的图的情况,后面简称为图。在本文的所有配图中,顶点的阴影表示其标签。
定义1.一个(无向图)标签图
G=(VG,EG,λG)
包含一组顶点VG,边集EG ⊆VG×VG:= {(u,v)|u,v∈VG,u≠v}和一个标记函数λG: VG→Σ将图的每个顶点映射到字母表∑中的元素上。
定义2.图S=(VS,ES,λS)是G=(VG,EG,λG)的一个子图,如果VS是VG的一个子集,ES是EG的一个子集,对于所有v∈VS,λS(v)=λG(v)。
定义3.模式P=(VP,EP,λP)是一个标记图,我们用作对另一个图的查询。
定义4.设P是是一个图的模式,用p来表示它的子图,用p⊆P表示。我们称p为P的子模式,同样地,我们称P为p的超模式。
2.2图同构
考虑到在大数据集图G中确定模式P的问题,我们需要技术来确定P是与G同构还是G的子图,从而确定模式P是否出现在数据集图G中。
定义5.图G1同构于G2,前提是G1和G2顶点集之间存在双射(一对一映射)。
f:VG1→VG2
保留顶点标签并且
(v1,v2)∈EG1当且仅当(f(v2),f(v2))∈EG2.
一般来说,同构是两个图(如G1和G2)顶点集之间的保边双射。在这种情况下,可以将G1作为G2的副本,反之亦然。
定义6.图G的自同构是从G到它自身的同构。
定义7.图G1是与G2子同构图,如果G1与G2的子图同构。
为了让我们知道一个模式在数据图中出现了多少次,我们需要在数据图中定义出现的概念和模式的实例。
在本文中,当没有混淆的时候,是为了简单起见我们将图G=(VG,EG,λG)写成G=(VG,EG)。
定义8.给定一个模式P=(VP,EP)和一个数据集图G=(VG,EG),一个出现就是从模式P到G的子图的同构f,也就是说f也是从P到G的子图同构。
定义9.给定一个模式P=(VP,EP)和一个图G=(VG,EG),当P和S之间存在同构时,G的子图S是模式P在G中的一个实例。
注意,出现和实例是两个不同的概念。出现是模式P和数据集图G的子图之间的同构,而实例是与模式P同构的G的子图。可以有多个出现将模式P映射到一个实例。例如,在图2中,三角形图案在数据图中有6个出现f1、f2、f3、f4、f5、f6,而它只有一个实例,即顶点1、2和3诱导的子图。出现和实例是我们提出的支持方法框架中的关键组件。
2.3重叠概念和支持方法
定义支持方法的目的是计算数据图G中模式P的外观。支持方法的定义如下:
定义10.数据图G中模式P的支持方法是一个函数σ:G×G→R+,它将(P,G)映射到一个非负σ(P,G)上。
一种自然的方法定义模式支持方法的是使用其出现数,但是该方法不满足反单调性,即模式的方法不能超过其子模式的方法[16,14]。更直观的支持方法是数据集图形中模式实例数。然而,这种方法也不是反单调的[16,14]。
反单调性是支持方法的基本要求,因为现有的频繁模式挖掘算法大多依赖于它来安全地在搜索空间中删减不频繁的模式分支以提高效率。正式地说,我们有
定义11.如果G中模式p对于任何模式p及其超模式p的支持方法σ是反单调的,我们有σ(P,G)≥σ(P,G)。
为了应对上述挑战,Vanetik等人[16]提出了第一个非平凡反单调支

图2:显示三角形模式的示例在数据图中有6个出现和1个实例。我们有一个1的错误方法,但MNI方法等于3——它高估了模式的计数。
持测度,即基于最大独立集(MIS)支持。MIS支持是在基于数据图的所谓重叠图的基础上开发的。我们将这种方法的主要思想描述如下。首先,我们应该解释重叠的概念。
定义12.顶点重叠:如果顶点集f1(VP)和f2(VP)相交,则数据图G=(V,E)中模式P=(VP,EP)出现f1和f2的顶点重叠,即f1(VP)∩f2(VP)≠∅其中fi(vp)=fi(v):v∈vp,i=1,2。如果S1和S2的顶点集相交,即VS1∩VS2≠∅,则存在模式P的实例S1=(VS1,ES1)和S1=(VS2,ES2)的顶点重叠。
定义13.边重叠:如果f1(EP)和f2(EP)的边集相交,即f1(ep)∩f2(ep)≠∅其中fi(EP)={(fi(u),fi(v)):(u,v)∈EP}, i=1,2,则数据图G=(v,e)中模式P=(VP,EP)出现的边重叠。如果S1和S2的边集相交,即ES1∩ES2≠∅,则存在模式P的实例S1=(VS1,ES1)和S1=(VS2,ES2)的边重叠。
定义14.给定模式P=(VP,EP)和数
据集图G=(V,E),出现(实例)重叠图是一个图O,其中O的每个顶点表示P在G中的出现(实例),如果两个出现(实例)重叠(从上面定义的重叠的意义上来说),则两个顶点u和v是相邻的。
在这篇文章中,我们主要研究出现是如何重叠的,我们只考虑顶点的重叠。
定义15.图G=(V,E)的独立(顶点)集是V的一个子集,因此没有相邻的。
定义16.给定模式P=(VP,EP)和数据图G=(V,E),基于最大独立集的支持定义为出现的最大独立顶点集或实例重叠图O的基数:
σMIS(P,G) = maxI|I|,
其中I是一个独立的O集。我们使用符号|·|来表示集合中元素的数量。
MIS支持的主要缺点是计算效率,如[11]所示,最大独立集问题在图顶点数量上是NP难的。因为MIS[16]基于重叠图,所以顶点在数据图中表示模式的实例。因此,计算MIS作为支持方法也是NP难的2。
Bringmann和Nijssen[6]提出了一种支持方法,称为基于图像的最小支持(MNI)。它基于一种不同于重叠图的技术。这里的主要概念是图像,它是数据图中模式(下文称为节点)中顶点的存在。例如,在图2中,模式中的节点v1有3个不同的图像,因为在数据图中存在到顶点1、2、3的出现映射v1(例如,f1(v1)=1、f3(v1)=2和f5(v1)=3)。
定义17.给出一个模式P=(VP,EP),一个数据图G=(V,E),如果P在G中有m次出现{f1,f2,··· ,fm},基于最小图(MNI)支持被定义为
σMNI(P,G) = min v∈VP |{fi(v) : i = 1,2,··· ,m}|.
换句话说,对于模式P中的每个节点v,MNI支持标识了其唯一图像的计数c,c = |{fi(v) : i = 1,2,··· ,l}|。然后,MNI支持测量G中的P方法,为模式P中所有节点的最小计数c。MNI可以配置为允许对图像中的误差存在一定的容忍度[6]。给定一个参数k,支持方法可以根据包含模式k节点的每个连接子图彼此匹配的位置被定义。
定义18. 给定一个模式P=(VP,EP),一个数据图G=(V,E),一个正整数参数k,如果P在G中有M次出现{f1,f2,··· ,fm},基于k图像的最小支持被定义为
σMNI(P,G,k) = min V’ |{fi(V0) : i = 1,2,··· ,m}|,
其中,V0是VP和|V’| = k.的连接子集。
利用映射到G中唯一节点数最少的P中的节点,保证了MNI的反单调性,σMNI(P,G,k)的反单调性证明是相似的。
与NP难的MIS支持相比,MNI支持的一个明显优势是计算时间。原因是,它只需要一组图像用于模式中的每个节点,并且确定每个集的最小不同图像数可以在O(n)中完成,其中n是模式的出现次数。然而,MNI支持有一个明显的缺点,即缺乏直观性。让我们重温图2中的例子:三角形图案的MIS模式是1,而MNI支持是3,因为每个节点的最小图像数是3。与我们的直觉不一致的是,模式
中6个出现的f1、f2、f3、f4、f5、f6重叠,只有一个实例,即顶点1、2和3诱导的子图。
MIS和MNI支持代表了频繁子图挖掘支持措施设计中的两个主要工作方向。两者都是反单调的,但它们站在计算效率和对模式频率的高估的远端。虽然MIS返回的是最小的计数,但没有有效的算法来计算它[3]。MNI需要线性时间来计算,但可以为模式返回任意大的计数[2]。MIS和MNI都有不同于本节中提到的基本形式的变体。我们将在第5节中介绍一些变体。在这里,我们只强调这些变体不会显著改变MIS和MNI的特性。
直观地说,MNI支持返回的计数接近于模式的出现次数。但是,根据实例数量确定模式的支持方法更为自然(请注意,MIS计算的是独立实例的数量)。回想一下图2中的例子:实例的数量是1,但是它的MNI支持方法是3,这并不符合常识。然而,众所周知,作为支持测度的实例数并不是反单调的,本文提出了两种反单调的支持方法,实现了接近模式实例数的计数和错误支持方法。
- 新的支持方法
在本节中,我们首先介绍了一个名为“出现/实例超图”(occurrence/instance hypergraph)的新概念,从中构造新的支持方法。这种概念简化了确定具有所需功能的支持方法的问题。请注意,这种方法不同于MIS中使用的重叠图和MNI中使用的事件图像。与实例(子图)和引用(同构)不同,我们将节点(即模式中的顶点)图像表示为顶点,将引用/实例表示为边。
定义19。超图H=(V,E)由n个顶点的集合V = {v1,v2,··· ,vn}和m个边的集合E = {e1,e2,··· ,em}组成,其中每个边都是V的非空子集。一个简单的超图H是一个超图,如果其中没有一条边是另一条边的子集,也就是说,如果它是ei ⊆ ej,i=j。一个k-均匀超图是一个所有边都有k大小的超图。
为了讨论相关支持方法的特点,我们还引入了对偶超图的概念。
定义20. H =(V,E)的对偶超图H∗=(E,X)是将原超图的顶点和边的信息互换,顶点通过E = {e1, e2, ···, em}给定,边缘是通过X = {X1,X2,··· ,Xn}给定的。其中Xj = {ei : vj ∈ ei},j = 1,2,··· ,n, Xj是H中包含顶点vj的全部的边。
作为一项关键技术,我们展示了如何将模式的出现和实例集成到超图中,并在超图中定义支持方法。
定义21.如果模式P = (Vp,Ep)有m个出现点{fi : i = 1,··· ,m}则g中p的出现超图定义为H0 = (V,E),其中V = f1(Vp)∪f2(Vp)∪ ···∪fm(Vp), and E = {ei : i = 1,··· ,m}, each ei = fi(Vp).换句话说,超图顶点集V是所有模式节点图像的集合,每个边ei是由引用fi映射的模式节点图像的集合。我们也给每个ei一个标签fi,以便区分它们。
定义22.如果模式P = (Vp,Ep) 在数据图G中有m个实例{Si = (Vsi,Esi) : i = 1,··· ,m},P在G中的实例超图被定义为Hi=(V,E),其中V = VS1∪VS2∪···∪VSm, E = {ei : i = 1,··· ,m}, each ei = Vsi。我们也给每个ei一个标签Si来区分它们。
对于下面的讨论,我们要强调的是,由于出现(实例)超图中的所有边都与相同的模式相关,因此它们包含相同数量的顶点,这意味着出现(实例)超图是统一的超图。
让我们用图3来展示超图是如何构造的:出现的超图H0=(V,E)具有顶点集V = {1,2,3, 4,5,6, 8,9,10,11, 13,15,16,17}和边集E = {e1,e2,e3,e4,e5,e6} = {{1,2,3}, {4,5,6}, {4,6,8}, {8,9,10}, {11,13,17}, {11,15,16}}。注意,在出现(实例)超图中,每个边表示一个出现(实例)。在图3中,实例超图也具有相同的边集,因此它看起来像是出现超图。然而,在许多其他情况下,超图的出现和实例是不同的。例如,在图2中,三角形图案的引用超图有6个边,因为有6个引用。尽管所有边都有相同的顶点集{1,2,3}但它们被视为6个不同的边,因为边标签不同。另一方面,图2中模式的实例超图只有一条边,因为有一个实例。我们之所以给每个边都贴上这样的标签,是为了从数据图中保存必要的信息,以便研究各种支持方法。
出现超图和实例超图之间的差异部分是由于模式的拓扑结构,或者更具体地说是自同构造成的。当一个模式具有非标识自同构时,多次出现会将该模式投影到数据集图的同一个子图中。当模式不允许自同构时,它的出现和实例超图非常相似。
如图3所示,由超图边表示的模式出现在不同的程度和位置上重叠。在出现(实例)重叠图中,每个出现(实例)转换为一个顶点,如果两个出现(实例)重叠,则在它们之间生

图3:三角形图案的出现/实例超图
成一条边。因此,不完全考虑出现(实例)重叠的方式。例如,在图3中,e3和e2在两个顶点上重叠,但e3和e4在一个顶点上重叠。我们认为,与基于重叠图的支持方法(如MIS[16])相比,超图框架可以保留更多此类信息,并为进一步的调查提供更多的视角和灵活性。
3.1最小实例支持方法
如上所述,MNI支持方法对子图模式的结构不敏感。为了解决MNI支持的这个问题,我们考虑了给定模式的结构,并定义了一个新的支持方法。让我们使用图4所示的示例来解释其主要思想。
我们可以看到三个模式节点v1、v2和v3,每个节点有两个图像

图4:MNI vs MI 支持方法
{1,4}, {2,3}, 和 {3,2},因此该模式的方法支持MNI为2。但是,它忽略了两个引用在顶点2和3上重叠的事实。显然,两个节点v2和v3在子模式中是对称的,这意味着子模式上存在一个映射到另一个的自同构。因此,v2,v3可以被认为是一个集合{v2,v3}它有一个图像{2,3}作为集合。这一观察结果引出了一种新的支持方法的定义,它利用了模式的拓扑结构,减少了MNI的高估。
在确定新的支持方法之前,让我们首先介绍一下支持概念。
给定一个模式P = (Vp,Ep),一个数据图G = (V,E),如果P在G中有m个出现{f1,f2,··· ,fm},我们将粗粒度节点子集W定义为Vp的一个子集。粗粒度节点子集图计数被定义为
c(W) = |{fi(W) : i = 1,2,··· ,m}|。
在图4中,如果粗粒度节点子集W是{v2,v3},则其粗粒度节点子集图像计数c(W) = |{{2,3},{3,2}}| = 1。对于节点子集M = {v2}, c(M) = |{{2},{3}}| = 2。
根据我们的观察,对称的模式节点应该包含在节点子集中,因此我们将传递节点子集的定义介绍如下。
定义24.图G中的一对顶点u和v是可传递的,如果G中至少有一个自同构f,即f(u)=v。
注意,在这个定义中,u和v可以相等。
定理1.对于图G中的顶点U、V和W,如果U、V和V、W对都是可传递的,则U、W对是可传递的。
证明.由于u,v和v,w对在g中都是可传递的,所以g有两个自同构f和g,这样f(u)=v和g(v)=w。因此,f和g的组成,表示为f ◦ g,也是g和f ◦ g(u)=w的自同构,表示u,w对在G中也是可传递的。
定义25.模式P = (Vp,Ep)中的传递节点子集t是Vp的一个子集,这样t中的任何一对顶点在P中都是传递的。
传递节点子集是粗粒度节点子集的一个特例,我们将证明使用这些概念可以将MNI和MI方法联系起来。
现在,我们准备使用粗粒度节点子集图像计数的定义来定义模式P的新支持方法。
定义26. 给定一个模式P = (Vp,Ep),一个数据图G = (V,E),让t是模式p的子图中的传递节点子集,所有这些t的集合表示为T = {T}。G中P的基于最小实例支持(MI)被定义为
σMI(P,G) = min T∈T
c(T)。
对于图4中的示例模式,有粗粒度节点子集{v1},{v2},{v3} 和 {v1,v2},因此σMI(P,G)=1。现在让我们研究一下MI支持的主要特性。

图5:一个例子展示模式被扩展到超级模式
定理2。MI支持措施是反单调的。
证明.给定数据图G中的模式p = (Vp,Ep)及其上模式P = (Vp,Ep),我们假设p在G中有m个出现{f1,f2,··· ,fm},P在G中有l个出现{f’1,f’2,··· ,f’l}。首先,我们有σMI(p,G) = minT∈T c(T)和σMI(P,G) = minT∈T0 c0(T)。通过定义,显然T ⊆T0。在下一步中,我们将证明,对于每个T ∈T,其在映射{f1,f2,··· ,fm}下的图像计数c(T)大于或等于其在映射{f’1,f’2,··· ,f’l}下的图像计数c’(t)。这是正确的,因为任何一个f’ i都是某些fi的一个扩展,它意味着f0’i(T) = fi(T), ∀ T ∈T。其中,T∈T c(T) ≥ minT∈T c’(T) ≥ minT∈T' c’(T)。因此我们有σMI(p,G) ≥ σMI(P,G)。
图5通过一个示例说明了MI支持方法的反单调性。
定理3.MI支持方法是线性时间可计算的。
证明.给定σMI(p,G) = minT∈T c(T),模式P有固定的T个数,很明显计算c(T)花费O(n)时间,其中n是出现次数。因此,σMI是线性时间可计算的。
定理4.给定一个模式P和数据图G,我们有
σMI(P,G) ≤ σMNI(P,G)。
证明.设W = {{v} : v ∈ VP}我们可以将MNI支持方法重写为σMNI(P,G) = minW∈W c(W)。
因为W ⊆ T,我们得到了σMI(P,G) = minT∈T c(T) ≤min W∈W c(W) = σMNI(P,G)。
在实践中,会有许多的案例,MI是一个比MNI严格较小的值。如图4,当考虑额外的粗粒的节点子集时,它们中的最小计数将减少。通过这种方式,我们可以获得支持计数MI,与MNI相比,它更接近于实例的数量。
综上所述,我们证明了MI方法是反单调的,可以用线性时间计算,并返回以MNI为界的频率。
3.2最小顶点覆盖支持方法
开发MI的目的是通过避免MNI过高估计来实现合理的计数。但是,MI不能处理图6所示的重叠类型。虽然独立实例的数量只有2个(例如,{1,5} 和 {4,8}是独立的),但我们仍然得到MI = MNI = 4。此外,只有三个可能的粗粒度节点子集{v1},{v2},{v1,v2},它们的图像计数为4、4和7。因此,MI的任何变体也不会有帮助。
对于某些数据图(如图6),模式节点之间的部分重叠似乎很重要,因此在这种情况下,将节点集划分为子集并使用它们各自的最小图像计数是不合理的。我们选择将所有模式节点视为一组,也就是说,我们不会在引用(实例)超图中破坏边。因此,可以选择每个出现(实例)中的每个节点图像来表示此出现(实例)。我们寻找少量的节点图像,这些图像一起表示所有的出现(实例)。直观地说,我们希望找到一个最小图像计数的最终版本,它使用具有代表性的节点图像而不是单个节点图像的最小计数,并获得更接近MIS的计数。
现在我们引入一个支持方法,它甚至比MI小,但是需要更多的时间来计算。中心思想与众所周知的顶点覆盖问题有关。
超图H=(V,E)的顶点覆盖是与H的每一条边相交的V的子集。最小顶点覆盖是具有最小基数的顶点覆盖。
在出现/实例超图框架下,我们可以将最小顶点覆盖转换为一个支持方法,以提供合理的引用/实例计数。
定义28.给出了数据图G中的模式P及其出现(实例)超图H=(V,E)。G中P的基于最小顶点覆盖(MVC)的支持被定义为
σMV C(P,G) = min C |C|,
其中C是H的一个顶点覆盖。
换句话说,MVC被定义为G中P的出现(实例)超图中最小顶点覆盖集的基数。例如,在图6中,出现超图中的边是{{1,5}, {1,6}, {1,7}, {1,8}, {2,8}, {3,8}, {4,8}}(实例)超图中的一个最小顶点覆盖集的基数。例如,在图6中,并且点集{1,8}是最小顶点覆盖,因此σMVC = 2。下面讨论MVC的特性。
定理5.MVC支持是反单调的。
证明.我们将证明,对于图G中的模式p及其超模式P,我们有σMV C(p,G) ≥ σMV C(P,G)。设{f1,f2,··· ,fm}和{f’1,f’ 2,··· ,f’m0}分别表示模式p和P的所有出现的集合。假设Hp和HP分别是p和P的超图。假设C是Hp

图6:MNI方法会过度估计模式计数,因为它忽略了部分重叠
的最小顶点覆盖,它与每个边fi(VP)相交。由于图P在G中的任何出现f0必须是图P在G中出现fi的扩展,因此我们得到该fi(Vp) ⊆ f0(VP)。如果C与fi(Vp)相交,则必须与f0(VP)相交。因此,HP的最小顶点覆盖C包含HP的顶点覆盖。因此C的基数大于或等于HP最小顶点覆盖的基数,即σMV C(p,G) ≥ σMV C(P,G)。
关于σMVC的反单调性的一个说明性例子,我们参考图5:当模式{v1,v2,v3}扩展到包括{v4}时,MVC支持仍然是1。例如,顶点集1是最小顶点覆盖,它仍然与每个扩展的超图边相交,因此它是超图的顶点覆盖中出现的超模式。
定理6.给定一个模式P和数据图G,我们有
σMV C(P,G) ≤ σMI(P,G)。
证明. 假设模式P = (Vp,Ep)有m次出现{f1,f2,··· ,fm}。由于σMI(P,G) = minT∈T c(T),必须有一个粗粒度的节点子集达到这个最小计数σMI。我们将此节点子集表示为T,其图像表示为{ {fi(T) : i = 1,2,··· ,m}。由于fi(T) ⊆ fi(VP),因此{fi(T) : i = 1,2,··· ,m}的最小顶点覆盖C也是{fi(VP) : i = 1,2,··· ,m}。因此得到σMV C(P,G) ≤ |C|。在下一步中,我们将展示|C|≤|{fi(T) : i = 1,2,··· ,m}|。如果t只包含一个顶点,则|C| = |{fi(T) : i =1 ,2,··· ,m}|。如果t包含两个或多个顶点,我们可以假设C = {u1,u2,···ul},其中ui ∈ fi(T), i = 1,2,··· ,l。显然,我们有|C|=|{fi(T) : i = 1,2,··· ,l}| ≤|{fi(T) : i = 1,2,··· ,m}| = c(T) = σMI(P,G)。因此,σMV C(P,G) ≤ σMI(P,G)。
现在我们看到MVC是反单调的,并且被MI所约束。在第4.4节中,我们将进一步说明MVC方法实际上接近MIS。对于计算效率,MVC不幸地是NP难的——这很容易证明,因为它本质上涉及到求解出现超图中的最小顶点覆盖问题。幸运的是,在K-均匀超图中,MVC是K-近似的,通过选择最大的独立边集,并选取其中的所有顶点。最佳近似算法在多项式时间[7]下实现因子k-o(1)近似。总之,MVC返回的计数较小,但与MI相比需要更多的计算时间。
4.超图框架
我们工作的一个非常有趣的结果是,现有的支持方法类别(即,MNI和MIS)虽然由不同的技术构建,但也可以合并到新的超图集中。因此,我们有一个统一的框架,它封装了本文提到的所有主要支持方法。
4.1超图框架中的MNI
我们首先证明,MNI支持可以很容易地与出现超图和新的MI支持方法相关联。在超图设置中,mni及其参数k的变体将模式减少到包含一个或k模式节点的子集。通过回顾第3.1节中定义的粗粒度节点子集的概念,我们可以看到如何根据这些概念
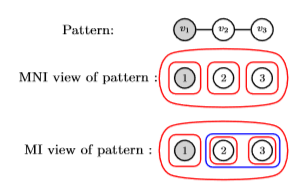
图7:MNI和MI在超图框架中的模式视图
解释σMNI(P,G)及其参数化版本σMNI(P,G,k)。
在模式P = (Vp,Ep),如果我们让W = {{v} : v ∈ VP},我们就可以重写MNI支持方法为
σMNI(P,G) = min W∈W
c(W)。
同样地,我们让Wk = {V 0 : connected V 0 ⊆ VP, |V 0| = k},那么σMNI(P,G,k)可以解释为
σMNI(P,G,k) = min V 0∈Wk
c(V 0)。
上述定义显示了σMNI(P,G)、σmni(p,g,k)和新的支持措施, σMNI(P,G,k)之间的联系。图7显示了在Hypergraph框架中如何使用MNI和MI。注意,MI不仅仅是从图形模式到超图版本的转换。例如,在图7中,如果我们将v3与v2断开,然后将其与v1连接,那么对v2和v3仍然处于可传递的节点子集中,而不再由模式图中的一个边连接。超图边用于捕获图案图所需的和基本的特征。从这个角度来看,超图确实是支持措施的一个合适且灵活的框架。
4.1超图框架中的MIS
我们现在证明,基于重叠图定义的MIS也可以映射到超图框架。为此,我们将在超图设置中引入一种新的度量方法,并证明它相当于MIS。
定义29.给定数据图G中的模式P

图8:数据图中一个小模式的实例超图及其对偶图
及其出现(实例)超图H=(V,E),最大独立边集(MIES)支持方法被定义为
σMIES(H) = max E’ |E’|
其中,E’是H的独立边集。
重叠图方法本质上类似于双超图的建立。根据双超图的定义,H中的所有边都是双H∗中的顶点,也是重叠图中的顶点。如果H中两条边ei,ej 在顶点v上重叠,那么ei,ej包含在双H∗的边Xv中,而(ei,ej)在重叠图中形成一条边。实际上,双H中的每一条边都等价于重叠图中的一个小集团。如果H∗是一个简单的超图,那么它与[18]中引入的重叠超图相同。图8中的示例显示了双超图和重叠图之间的相似性。
在超图框架内,我们将证明MIS等价于MIES,后者也是反单调的。为了实现这种分析,可以开发一个整数规划公式。这种公式也显示了MIES和MVC之间的关系,并作为降低诸如MIES和MVC等开销巨大的方法的计算成本的松弛(见第4.3节)。
让我们从MVC开始,假设超图H = (V,E)由n个顶点的集合V = {v1,v2,··· ,vn}和m个边的集合E = {e1,e2,··· ,em}组成。对于每个顶点,任意v ∈ V,我们有一个变量x(v)表示是否在顶点覆盖中选择v。约束条件表明,在每个超图边e中,至少应选择一个顶点,对象是最小化所选顶点的数量。现在我们可以写:
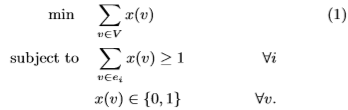
通过定义H的双超图H∗是一个顶点和边互换的超图,因此顶点由{ei : i = 1,2,··· ,m}给出,并且边是X = {X1, X2, ···, Xn},其中Xj是h中包含顶点vj的所有边的集合。让变量y(e)指示e是否在独立集内。约束条件表明,在每个边X中只选择一个顶点,对象是最大化独立顶点的数量。因此,H中最小顶点覆盖问题的对偶是H∗中的最大独立顶点集问题,其公式如下:
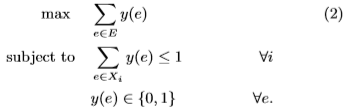
利用上述公式,我们可以证明MIS支持方法的大小与MIES相当。
定理7.给定数据图G中的模式P及其出现(实例)超图H=(V,E),我们有
σMIES(P,G) = σMIS(P,G)。
证明. 在出现超图H中确定最大独立边集的问题相当于在双超图H∗中确定最大独立顶点集,其中顶点对应于H中的边,反之亦然。虽然双超图和重叠图的形式不同,但它们的最大独立顶点集大小是相同的。我们使用线性规划技术来证明这个等价性。
在双超图H∗中,MIES等于最大优化问题的解(式(2)),而基于重叠图的MIS等于问题的解:max Pe∈E y(e)服从y(ej) + y(ek) ≤ 1,如果ej和ek重叠,y(e) ∈ {0,1}, ∀e。图8给出了一个示例。
我们将证明这两个最大优化问题的约束是等效的,因此它们的解值是相同的。此外,因为重叠图中的任何边(两个顶点)都包含在对偶超图边中,所以我们只需证明对于具有较大尺寸的Xi,对于y(e) ∈{0,1},等式E最大的Pe∈Xi y(e)相当于y(ej) + y(ek) ≤ 1,对于任何ej,ek ∈ Xi,1 ≤ j 6= k ≤ n,其中y(ej),y(ek)被限制为{0,1}。
很明显![]() 意味着 y(ej)+y(ek) ≤ 1对于任何ej,ek ∈ Xi,1 ≤ j 6= k ≤ n因为y(e),e ∈ Xi都是非负的。因此,我们需要证明y(ej)+y(ek) ≤ 1 对于任何 ej,ek ∈ Xi,1 ≤ j 6= k ≤ n意味着
意味着 y(ej)+y(ek) ≤ 1对于任何ej,ek ∈ Xi,1 ≤ j 6= k ≤ n因为y(e),e ∈ Xi都是非负的。因此,我们需要证明y(ej)+y(ek) ≤ 1 对于任何 ej,ek ∈ Xi,1 ≤ j 6= k ≤ n意味着![]()
假设y(ej) + y(ek) ≤ 1,对于任意的ej,ek ∈ Xi,1 ≤j 6 = k ≤ n和y(e) ∈{0,1},∀e ∈ Xi。如果存在一个e ∈X i−{ej,ek},那么在重叠图中必须再有两个边{e,ej} 和 {e,ek},因为所有e,e i,ek都在顶点i处重叠,因此我们应该在顶点i处有y(e)+y(ej) ≤ 1,y(e)+y(ek) ≤ 1,y(ej) + y(ek) ≤ 1和y(e),y(ej),y(ej),y(ej)和y(e),y(ej),y(ek) ∈ {0,1}.同样地,我们可以把所有其它的e ∈ Xi加到这个等式中,这样我们就可以得到Pe∈Xi y(e) ≤ 1。最后得到了σMIES(P,G) = σMIS(P,G)。
我们以图8为例,其中重叠图中的MIS支持为2。仔细观察,例如,{e1,e3}形成最大独立集。实例超图中的MIES也是2。
定理8.MIES测度是反单调的。
证明.由于MIES等价于反单调MIS,所以它也是反单调的。
4.3多项式时间松弛
松弛技术将一个NP难问题转化为一个可在多项式时间内求解的相关问题。另外,由松弛得到的解给出了原问题解的信息。例如,线性规划的解给出了原始最大化(最小化)问题的最优解的上界(下界)。
在第4.2节中,我们介绍了问题的整数规划转换。在此基础上,我们准备放宽最小顶点覆盖问题的可积条件,得到线性规划问题,并正式定义了MVC和MIES方法的松弛版本。我们还证明它们都是反单调的。
定义30.给定数据图G中的模式P及其出现(实例)超图H = (V,E),其中V = {v1,v2,··· ,vn}和E = {e1,e2,··· ,em},图G中模式P的多项式MVC支持方法被定义为
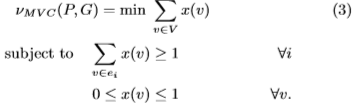
同样,我们放宽了极大独立边集问题的可积条件,得到了一个线性规划公式和另一个多项式时间支持。
定义31.给定数据图G中的模式P及其出现(实例)超图H=(V,E),其中V = {v1,v2,··· ,vn}和E = {e1,e2,··· ,em},双超图H∗=(E,x),X = {X1,X2,··· ,Xn},图G中模式P的多项式MIES支持方法被定义为
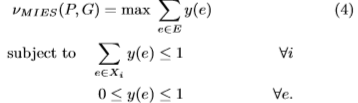
定理9.多项式时间MVC支持方法是反单调的。
证明. 我们将证明数据图G中任何模式p及其超模式P的νMV C(p,G) ≥ νMV C(P,G)。假设p和P在G中的出现超图分别为Hp = (V,E)和HP = (V 0,E0)。我们的方法是:利用LP(3)的解x∗ = vMV C(p,G)来构造另一个函数x∗∗使得x∗ ≥ x∗∗ ≥ vMV C(P,G),这样我们就能证明vMVC(p,G) ≥ vMVC(P,G)。
设vMV C(p,G) = Σv∈V x∗(v)为与Hp有关的LP(3)的解,对任意e∈E,Pv∈e x∗(v) ≥ 1,由此我们构造了一个函数x∗∗ = Σv∈V 0x∗∗(v)如下
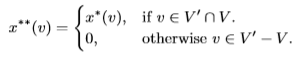
注意,对每个e’ ∈ E’都有e ∈ E使e ⊆ e’,因此,我们有
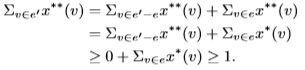
因此,x∗∗满足与HP有关的LP(3)的约束条件,即Pv∈e0 x∗∗(v) ≥ 1表示任何e’∈E’, 0 ≤ x∗∗(v) ≤ 1表示任何v∈v’。因此,我们得出x≥minpv∈v 0 x∗∗ ≥ min![]() x(v) = vMVC(P,G)。另一方面,我们有
x(v) = vMVC(P,G)。另一方面,我们有
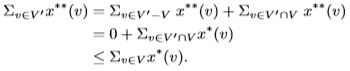
最后,我们得到Σv∈V x∗(v) ≥ Σv∈V 0x∗∗(v) ≥ vMV C(P,G),这意味着vMVC(p,G) ≥ vMVC(P,G)。
定理10.多项式时间MIES支持方法是反单调的。
证明.这个证明与定理9的证明类似。这里我们省略了细节。
4.4边界定理
为了探索新框架内所有支持方法之间的关系,我们从超图领域的经典结果中得出以下定理。我们首先研究MIES和MVC测量之间的差异。
定理11.给定模式P、数据图G和出现(实例)超图H=(V,E),我们有
σMIES(P,G) ≤ σMV C(P,G)。
证明. 假设i是一个最大独立边集,C是H中的最小顶点覆盖。对于每一个边e ∈ I,都有一个对应的顶点v ∈ C,使得v∈e。此外,对于任何e,e’∈ I,我们有e∩e’ = ∅,因此它们在C中的对应顶点是不同的。因此,我们得到|I|≤|C|,然后我们得到
σMIES(P,G) ≤ σMVC(P,G)。
上述定理表明,MVC方法大于MIES(根据定理7,等于MIS)。根据线性规划[15]中已有的结果,我们得出了σMIS、σMVC与相应线性规划问题中约束松弛产生的支持方法之间的关系。
定理12.给定一个模式P,数据图G和出现(实例)超图H,我们有
σMIES(P,G) ≤ νMIES(P,G) = νMV C(P,G) ≤ σMV C(P,G)。
证明.第一个和最后一个不等式直接由相应线性规划问题的定义给出。等式来自线性规划的对偶定理[15]。
定理12的一个关键思想是,我们可以在考虑超图的最大独立边集和最小顶点覆盖的松弛之间进行切换。在对偶线性规划松弛问题中,一个可行的原解的值大于或等于任何可行对偶解的值。此外,强对偶定理表明,如果原始程序有一个最优解,那么对偶也有一个最佳解,并且它们具有相同的目标值。
然而,定理12的结果表明,通过放宽原问题,我们进一步缩小了MVC和MIES/MIS之间的差距。
在实践中,如果每个顶点有一个包含在超图的边我们就会在原始版和松弛的版本的MVC之间有更强的一个联系。这将成非常有趣的未来的研究主题。
在定理4和6中比较了σMV C, σMI and σMNI。把所有的东西放在一起,我们有
σMIS = σMIES ≤ νMIES = νMVC ≤ σMVC ≤ σMI ≤ σMNI。
上述公式显示了一系列可在同一框架内构建并占用频谱不同位置的方法。
4.5框架内的其他扩展
我们相信,通过采用超图设置,我们可以利用资源丰富的经典超图定理来推进进一步的研究,并为支持方法之间的联系提供更深入的见解,甚至可以定义更多的支持措施。
在[5]中引入了顶点重叠的变体,称为有害重叠。我们提出了一个新的结构重叠概念,可以在研究错误支持方法时与有害重叠进行比较。此外,我们还介绍了结构重叠在支持方法研究中的应用。
在本节中,我们将定义12中的顶点重叠的概念称为简单重叠,以将其与两个新的重叠概念区分开来。
定义32.[5]如果∃ v ∈ VP,则P型的f1(v), f2(v) ∈ f1(VP)∩f2(VP)出现有害重叠(HO)。
定义33.如果∃ v,w ∈ VP,则模式p中出现f1和f2的结构重叠(SO),满足v和w包含在模式P的子图中的可传递节点子集中,并且f1(v) = f2(w) ∈ f1(VP)∩f2(VP)。
结构重叠的概念源于考虑传递节点子集重叠的MI支持方法。在计算mi时,我们让节点v2和v3构成一个可传递的节点子集,它有两个映像{2,3} 和 {3,4},MI = 2。然而,这两个图像有相同的顶点3。现在我们有了g1和g2在结构重叠意义上的重叠。

图10:说明结构重叠、有害重叠和简单重叠之间关系的示例和维恩图
此外,我们使用图9和图10来说明结构重叠和有害重叠是不同的概念。例如,尽管存在g1和g2的结构重叠,但它们的有害重叠并不存在。原因是g1(Vp)∩g2(Vp) = {3},但3是两个不同节点的图像v2,v3,其中g1(v3)=3和g2(v2)=3。另一方面,f1和f2之间存在着有害的重叠,但它们之间不存在结构上的重叠。我们指出,有害重叠和结构重叠都意味着简单重叠,在某些情况下,存在简单重叠,但既不存在有害重叠,也不存在结构重叠(如图10中的f2和f3)。有害重叠和结构重叠可能同时存在(如图9中的g1和g3)。
Fiedler和Borgelt[5]解释说,两个事件的某种类型的重叠不应被认为是有害的。根据有害重叠的定义,对于模式P = (Vp,Ep),如果它的两个实例f1和f2存在简单的重叠,并且节点图像f1(Vp)和f2(Vp)中至少有一个节点的图像,则存在f1和f2的有害重叠。类似的论点也适用于我们的结构重叠概念。当一个简单的重叠存在时,另外,如果一对节点在p的子图中是可传递的,并且它们的图像都在f1(Vp)和f2(Vp)中,则存在f1和f2的结构重叠。也就是说,图同构问题的核心是图的拓扑结构,而结构重叠更能解决这一问题。
有害重叠和结构重叠的共同点是,与简单重叠相比,两者都是较弱的概念。因此,与有害重叠一样,结构重叠的概念也可以通过各种方式来探索支持测度理论的前沿。例如,可以使用结构重叠来决定两个出现(实例)是否重叠,而不是简单的重叠,然后继续构造重叠图。结果得到的重叠图比简单重叠图更稀疏(边更少)。因此,可以使用MIS、MCP和其他基于重叠图的方法来获取模式出现次数(实例)。在超图设置中,由于其与MI支持方法的密切联系,结构重叠可能被用于探索MI支持方法的变体。
- 相关工作
频繁子图挖掘(FSM)问题是在数据图中查找子图,然后枚举支持(或频率)高于某个最小支持阈值的所有子图。FSM可以分为两类:确定事务数据图(一个包含多个小图的图形数据库)中的频繁模式和单个大数据图。在过去的几年中,在图表事务设置中发表了富有成效的成果:一些具有代表性的出版物包括Borgelt和Berthold[1]、Yan和Han[20,21]、Inokuchi等人。[10],Hong等人[8],Huan等人[9]、Kuramochi和Karypis[12]。尽管已经研究了单一大图形设置下的FSM(如Kuramochi和Karypis[13,14],Elseidy等人[4]),它得到的关注较少。其原因是,在大数据图和计算支持中,在查找模式出现的两个阶段都更具挑战性。
针对单图设置支持计数的问题,目前主要有两种方法。第一个是建立良好的基于重叠图的支持方法,在Vanetik[16]中首次引入,其正式定义在Vanetik等人中给出。[17]以及证明基于重叠图的方法为反单调所需的充分必要条件。本文还提出并分析了基于重叠图的方法的几种变化和扩展,包括Kuramochi和Karypis[14]提出的精确和近似的MIS方法,以及Calders等人提出的基于重叠图的MCP方法。〔3〕。在[3]中,作者还提出了使用theta函数的lovasz方法,该函数在重叠图中被证明是在MIS和MCP之间有界的。这在本质上与另一个名为schrijver图方法[19]非常相似。
王等给出了基于重叠图的MIS的松弛。〔18〕。请注意,超图的概念在[18]中也被用来定义重叠图[16]的变体,方法是用超图边替换组并删除非支配的超图边。在我们的方法中,我们不构建重叠图,我们的超图顶点是查询模式的节点图像,边代表出现和实例。
- 结论与未来工作
本文提出了一种研究频繁子图挖掘支持方法的新框架。该框架将模式和数据图转换为包含模式的出现和实例以及原始图形的信息的超图,与仅包含后者的现有重叠图技术不同。通过这样做,最新的超图定理可以提供理论解释来解释出现之间的关系(映射为超图中的边)。在新的超图设置下,得到了令人兴奋的结果,包括线性时间MI方法,返回的计数更接近模式实例,MVC方法非常接近MIS,以及MIES方法,在超图框架下是MIS的等效版本。
在基于超图的框架下,有着丰富的理论和实验研究机会。特别是,以下方向的探索值得立即关注。(1)可以研究新的重叠概念,如第4.5节所述;(2)可以设计更多的支持方法来弥补MVC和MI之间的差距。例如,具有超线性时间复杂度但小于MI计数的支持方法;我们还可以探索MI变化的设计,该设计利用模式的多种拓扑属性来确定粗粒度节点子集;(4)在支持方法的设计中包含其他所需的特征。一个重要的例子被称为可加性,这意味着计算可以以并行的方式进行,因此它为理论结果的实现带来了巨大的价值;(5)在为不同的应用程序定义和选择支持方法时,可以在框架中引入更多的应用。
鸣谢
这项工作得到美国国家科学基金会(NSF)的支持(IIS-12539 80),部分由美国国立卫生研究院(NIH)授予R01GM086707。Jinghan Meng部分获得美国国立卫生研究院(NIH)R01GM086707的支持。
7.参考文献
[1] C. Borgelt and M. R. Berthold. Mining molecular fragments: Finding relevant substructures of molecules. In Data Mining, 2002. ICDM 2003. Proceedings. 2002 IEEE International Conference on, pages 51–58. IEEE, 2002.
[2] B. Bringmann and S. Nijssen. What is frequent in a single graph? In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pages 858–863. Springer, 2008.
[3] T. Calders, J. Ramon, and D. Van Dyck. Anti-monotonic overlap-graph support measures. In 2008 Eighth IEEE International Conference on Data Mining, pages 73–82. IEEE, 2008.
[4] M. Elseidy, E. Abdelhamid, S. Skiadopoulos, and P. Kalnis. Grami: Frequent subgraph and pattern mining in a single large graph. Proceedings of the VLDB Endowment, 7(7):517–528, 2014.
[5] M. Fiedler and C. Borgelt. Support computation for mining frequent subgraphs in a single graph. In MLG. Citeseer, 2007.
[6] L. A. Gala´rraga, C. Teflioudi, K. Hose, and F. Suchanek. Amie: association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22nd international conference on World Wide Web, pages 413–422. ACM, 2013.
[7] E. Halperin. Improved approximation algorithms for the vertex cover problem in graphs and hypergraphs. SIAM Journal on Computing, 31(5):1608–1623, 2002.
[8] M. Hong, H. Zhou, W. Wang, and B. Shi. An efficient algorithm of frequent connected subgraph extraction. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pages 40–51. Springer, 2003.
[9] J. Huan, W. Wang, and J. Prins. Efficient mining of frequent subgraphs in the presence of isomorphism. In Data Mining, 2003. ICDM 2003. Third IEEE International Conference on, pages 549–552. IEEE, 2003.
[10] A. Inokuchi, T. Washio, and H. Motoda. Complete mining of frequent patterns from graphs: Mining graph data. Machine Learning, 50(3):321–354, 2003.
[11] R. M. Karp. Reducibility among combinatorial problems. In Complexity of computer computations, pages 85–103. Springer, 1972.
[12] M. Kuramochi and G. Karypis. An efficient algorithm for discovering frequent subgraphs. IEEE Transactions on Knowledge and Data Engineering, 16(9):1038–1051, 2004.
[13] M. Kuramochi and G. Karypis. Grew-a scalable frequent subgraph discovery algorithm. In Data Mining, 2004. ICDM’04. Fourth IEEE International Conference on, pages 439–442. IEEE, 2004.
[14] M. Kuramochi and G. Karypis. Finding frequent patterns in a large sparse graph. Data mining and knowledge discovery, 11(3):243–271, 2005.
[15] J. Pach and P. K. Agarwal. Combinatorial geometry, volume 37. John Wiley & Sons, 2011.
[16] N. Vanetik, E. Gudes, and S. E. Shimony. Computing frequent graph patterns from semistructured data. In Data Mining, 2002. ICDM 2003. Proceedings. 2002 IEEE International Conference on, pages 458–465. IEEE, 2002.
[17] N. Vanetik, S. E. Shimony, and E. Gudes. Support measures for graph data. Data Mining and Knowledge Discovery, 13(2):243–260, 2006.
[18] Y. Wang and J. Ramon. An efficiently computable support measure for frequent subgraph pattern mining. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 362–377. Springer, 2012.
[19] Y. Wang, J. Ramon, and T. Fannes. An efficiently computable subgraph pattern support measure: counting independent observations. Data Mining and Knowledge Discovery, 27(3):444–477, 2013.
[20] X. Yan and J. Han. gSpan: Graph-Based Substructure Pattern Mining. In Proceedings of the 2002 IEEE International Conference on Data Mining (ICDM 2002), 9-12 December 2002, Maebashi City, Japan, pages 721–724, 2002.
[21] X. Yan and J. Han. Closegraph: mining closed frequent graph patterns. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 286–295. ACM, 2003.
这篇关于「翻译」Flexible and Feasible Support Measures for Mining Frequent Patterns in Large Labeled Graphs的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!