本文主要是介绍实验笔记之——基于TUM-RGBD数据集的SplaTAM测试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前博客对SplaTAM进行了配置,并对其源码进行解读。
学习笔记之——3D Gaussian SLAM,SplaTAM配置(Linux)与源码解读-CSDN博客SplaTAM全称是《SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM》,是第一个(也是目前唯一一个)开源的用3D Gaussian Splatting(3DGS)来做SLAM的工作。在下面博客中,已经对3DGS进行了调研与学习。其中也包含了SplaTAM算法的基本介绍。学习笔记之——3D Gaussian Splatting及其在SLAM与自动驾驶上的应用调研-CSDN博客。https://blog.csdn.net/gwplovekimi/article/details/135647242?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22135647242%22%2C%22source%22%3A%22gwplovekimi%22%7D在原博客中也对TUM-RGBD数据集的freiburg1_desk_seed0进行了测试,感觉效果一般般,为此本博文打算对下载的TUM几个序列都进行测试看看效果。
本博文为本人实验测试SplaTAM过程的实验记录,本博文仅供本人实验记录用~
目录
运行过程
rgbd_dataset_freiburg1_desk
rgbd_dataset_freiburg1_desk2
rgbd_dataset_freiburg1_room
rgbd_dataset_freiburg2_xyz
rgbd_dataset_freiburg3_long_office_household
总结与分析
运行过程
注意:要修改configs/tum/splatam.py中的scene_name来决定训练哪个序列
(之前的desk训练时间大概30分钟左右,还是打开一下tmux吧)
tmux new -s desk2
tmux new -s room
tmux new -s xyz
tmux new -s household(开启运行的环境)
conda activate splatam(开始测试运行)
python scripts/splatam.py configs/tum/splatam.py运行后,可以看到experiments文件如下:

忘记指定GPU了,都挤到一块板子上跑了

等待一段时间,下面看看再各个序列的测试效果
要训练完才可以可视化建图与定位的效果(注意跟训练一样要修改对应的config文件来选用序列,seed统一都为0)
(最终的建图效果)
python viz_scripts/final_recon.py configs/tum/splatam.py(训练过程的可视化)
python viz_scripts/online_recon.py configs/tum/splatam.pyrgbd_dataset_freiburg1_desk
SplaTAM Testing using TUM-Dataset freiburg1
SplaTAM Testing using TUM-Dataset freiburg1
训练完结果如下:PSNR只有21.49算是比较差的吧,当然deth恢复的精度是3.38cm以及定位精度是3.34(论文里面是3.35)这个结果还是不错的。细看论文会发现,论文里面对于TUM数据集好像只用来验证定位精度,而mapping性能都是采用Replica与ScanNet++。目前不打算花太多时间去逐一验证了,有小伙伴验证了的话可以给个评论看看是否如论文的效果,因为在tum数据集上,个人感觉mapping效果一般般~

rgbd_dataset_freiburg1_desk2

结果如下:
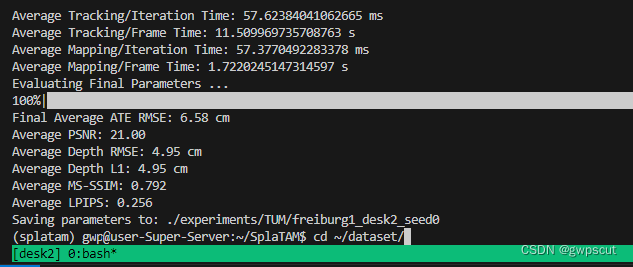
这个效果比上面的要更差一些,可以发现各个性能指标都差一些(此处定位精度是是6.58cm,论文是6.54cm)。
视频效果如下所示:
SplaTAM Testing using TUM-Dataset freiburg1
rgbd_dataset_freiburg1_room
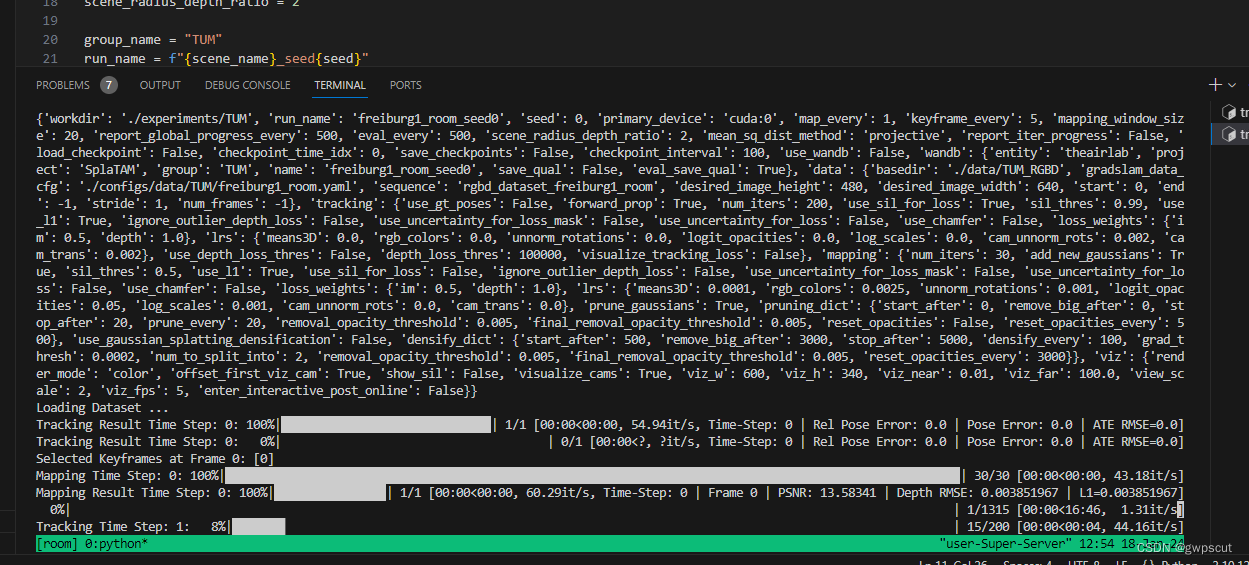
结果如下(此处定位精度是11.49cm,论文结果是11.13cm)

视频效果如下所示:
SplaTAM Testing using TUM-Dataset freiburg1
rgbd_dataset_freiburg2_xyz
rgbd_dataset_freiburg3_long_office_household
总结与分析
综合下来,几个数据集下的表现,tracking的结果跟论文给出的差不多,而mapping的psnr都比较差(论文验证psnr性能指标是用其他几个数据集),而depth的恢复精度(L1)都是3~4cm这个结果还是比较好的(不过毕竟用了RGBD~),
后面有时间再试试用手机实测来看看吧,不过目前看来用数据集测试的效果都比较差,实时性也很一般,比如rgbd_dataset_freiburg1_desk序列都训练30多分钟了,PSNR还只有21左右,应该3DGS性能不至于这样,可能是因为一些参数的设置包括剪枝等等的操作吧~感觉还是有比较大可以研究的空间~
这篇关于实验笔记之——基于TUM-RGBD数据集的SplaTAM测试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






