本文主要是介绍阿里AnyText:多语种图像文字嵌入的突破,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
模型简介
随着Midjourney、Stable Difusion等产品的兴起,文生图像技术迅速发展。然而,在图像中生成或嵌入精准文本一直是一个挑战,尤其是对中文的支持。阿里巴巴的研究人员开发了AnyText,这是一个多语言视觉文字生成与编辑模型,旨在解决这些难题。
-
Github:https://github.com/tyxsspa/AnyText
-
AI快站模型免费加速下载:https://aifasthub.com/models/damo

核心特点
-
精准文本生成,AnyText能够在图像中生成或编辑精准文本,其对生成文字的把控可与专业PS相媲美。用户可以自定义规划文字出现的位置,以及图片的强度、力度、种子数等。
-
多语言支持,AnyText特别强调对中文的支持,同时还支持日文、韩文、英语等多种语言。这使得模型在电商、广告平面设计、电影制作等领域中尤为有用。

技术架构
AnyText采用了文本控制的扩散流程,包括辅助潜变量和文本嵌入两个重要模块。辅助潜变量模块用于生成或编辑文本的潜在特征,而文本嵌入模块则利用OCR模型将笔画数据编码为嵌入向量。
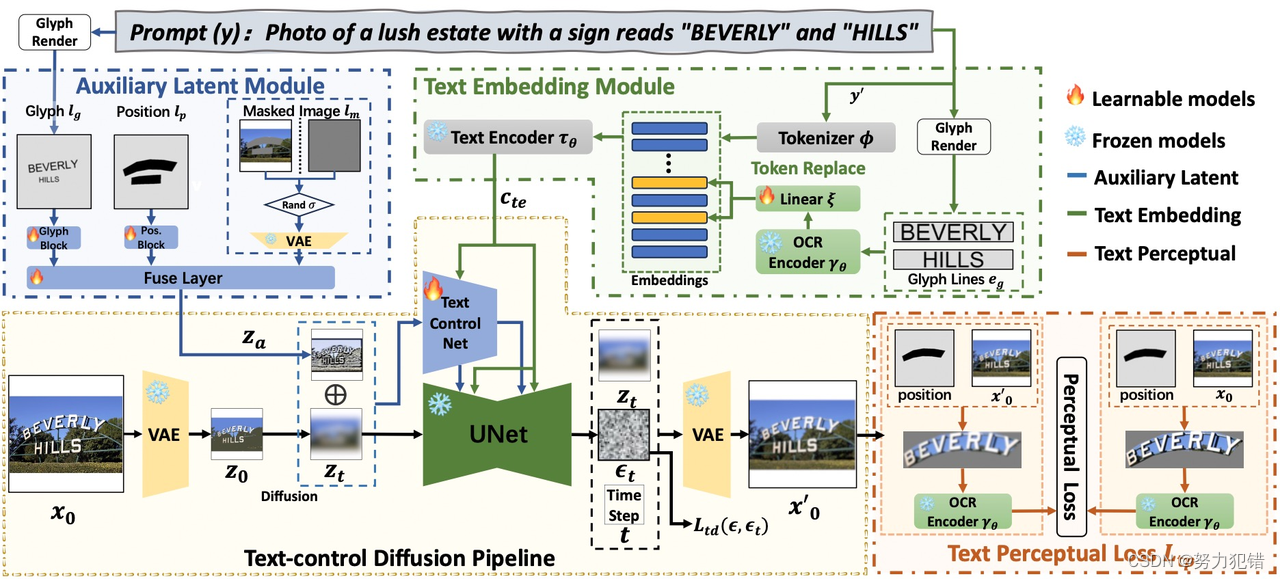
技术难点
-
数据集限制,大多数现有的大规模图像扩散模型的训练数据集缺乏手动注释或文本内容的OCR结果,这限制了模型在生成图像中嵌入精准文本的能力。
-
文本编码器局限性,许多开源扩散模型使用的文本编码器采用基于词汇的分词器,无法直接访问字符级别的信息。
-
损失函数不足,大多数扩散模型的损失函数旨在提高整体图像生成质量,缺乏对文本区域的专门监督和优化。

解决方案
为了克服这些挑战,阿里巴巴的研究团队开发了AnyText模型和AnyWord-3M数据集。
-
AnyWord-3M数据集,AnyWord-3M是一个包含300万个图像-文本对的数据集,提供了中文、英文、日文、韩文等多种语言的OCR注释。这个数据集中的文本行超过900万行,字符和词汇总量超过2亿,覆盖了广泛的语言类型。
-
文本控制扩散损失,为了提升图像中嵌入文本的精准度,AnyText采用了文本控制扩散损失,这有助于控制生成的文本在指定位置和样式上的准确性。
-
文本感知损失,文本感知损失的作用是进一步增强生成文本的准确性,通过比较生成文本的特征表示与真实图像中相应区域的特征表示之间的差异。
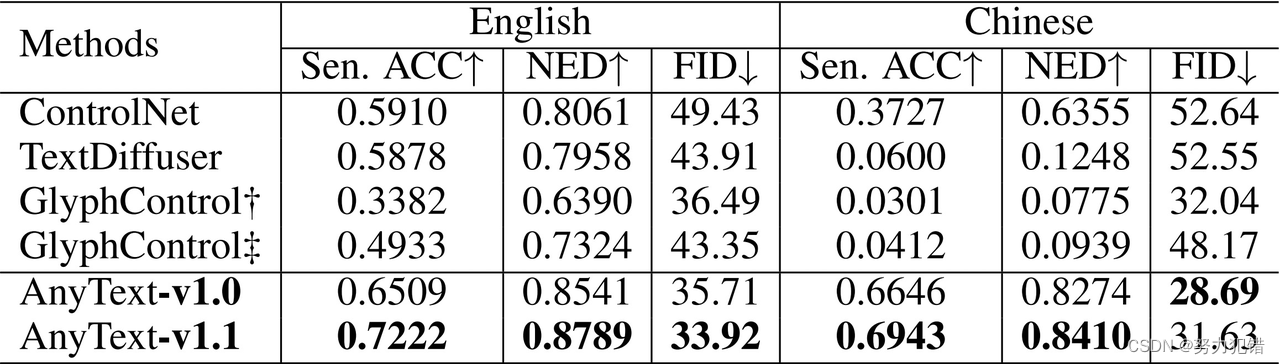
应用场景
-
电商和广告设计,AnyText在电商和广告领域中的应用非常广泛,可以用于创建各种促销材料和广告内容,尤其是在需要精确控制文本内容和样式的场景中。
-
电影和动画制作,在电影和动画制作中,AnyText可以用来生成含有特定文字的场景,如街道标志、广告牌等,增强场景的真实性和沉浸感。
-
插画和UI设计,对于插画师和UI设计师来说,AnyText提供了一种高效的方法来将文字融入到他们的作品中,尤其是当涉及到复杂的字体设计和布局时。
AnyText的未来展望
-
插件形式的集成,AnyText能以插件形式与其他开源扩散模型无缝集成,从而全面强化其图像嵌入精准文本的能力。
-
多领域应用,AnyText不仅适用于艺术和设计领域,还可以广泛应用于电商、广告、电影制作、动画设计、网页设计和UI设计等领域。
-
持续发展和创新,随着技术的不断发展和创新,预计AnyText将在未来提供更高精准度和更广泛的应用场景。
结论
AnyText作为一款多语言视觉文字生成与编辑模型,为文生图像领域带来了重大突破。其能够在图像中生成精准文本的能力,尤其是对中文的支持,解决了长期存在的技术难题。随着技术的进步和应用的深入,AnyText有望成为电商、广告、设计等多个领域的关键工具,推动整个AIGC领域的发展。
模型下载
Github
https://github.com/tyxsspa/AnyText
AI快站模型免费加速下载
https://aifasthub.com/models/damo
这篇关于阿里AnyText:多语种图像文字嵌入的突破的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!