anytext专题
AnyText: 多语言视觉文本生成与编辑
AnyText: 多语言视觉文本生成与编辑 论文介绍 Anytext: Multilingual Visual Text Generation and Editing 关注微信公众号: DeepGoAI 项目地址:https://github.com/tyxsspa/AnyText(已经3.3k+) 论文地址:https://arxiv.org/abs/2311.03054 本文介绍一款基于扩散
阿里AnyText:多语种图像文字嵌入的突破
模型简介 随着Midjourney、Stable Difusion等产品的兴起,文生图像技术迅速发展。然而,在图像中生成或嵌入精准文本一直是一个挑战,尤其是对中文的支持。阿里巴巴的研究人员开发了AnyText,这是一个多语言视觉文字生成与编辑模型,旨在解决这些难题。 Github:https://github.com/tyxsspa/AnyText AI快站模型免费加速下载:https:/

阿里巴巴提出AnyText:首个解决多语言视觉文本生成的工作
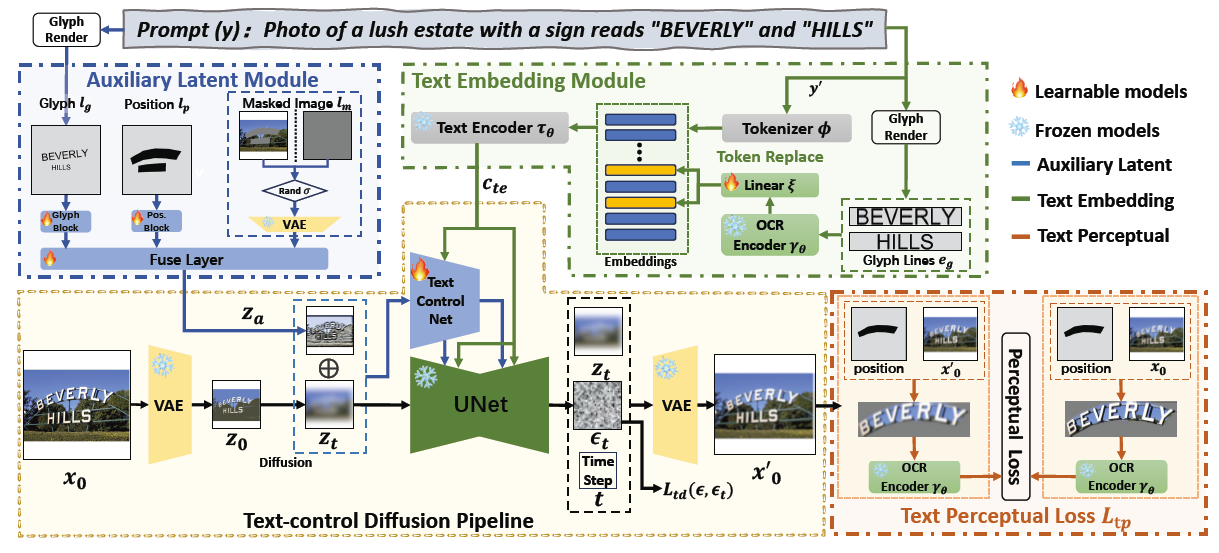
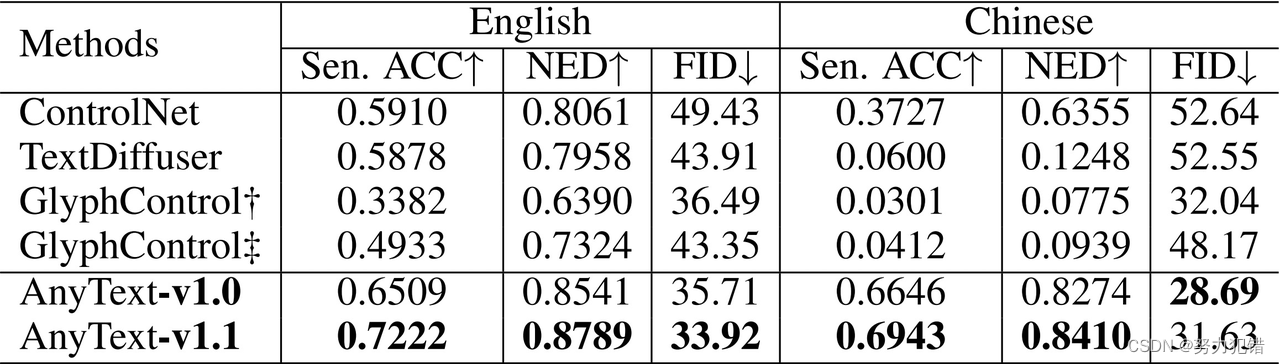
基于扩散模型的文本到图像在最近取得了令人瞩目的成就。尽管当前的图像合成技术已经非常先进,能够以高保真度生成图像,但当关注生成图像中的文本区域时,往往可能会暴露问题,因为合成文本通常包含模糊、不可读或不正确的字符,使得视觉文本生成成为该领域最具挑战性的问题之一。为了解决这个问题,本文引入了AnyText,这是一个基于扩散的多语言视觉文本生成和编辑模型,专注于在图像中呈现准确而连贯的文本。An

tyxsspa/AnyText 阿里生成文字
Dockerfile ################ # 使用 NVIDIA CUDA 11.8 开发环境作为基础镜像 FROM nvcr.io/nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04 # 设置非交互式安装模式以避免某些命令在构建过程中暂停 ENV DEBIAN_FRONTEND=noninteractive # 更新软件包列表并安装基本

ANYTEXT: MULTILINGUAL VISUAL TEXT GENERATION AND EDITING
ANYTEXT: MULTILINGUAL VISUAL TEXT GENERATION AND EDITING Yuxiang Tuo, Institute for Intelligent Computing, Alibaba Group, ICLR2024 (6668), Code, Paper 1. 前言 基于扩散模型的文本到图像最近取得了令人印象深刻的成就。尽管当前用于合成图像的