本文主要是介绍AnyText: 多语言视觉文本生成与编辑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AnyText: 多语言视觉文本生成与编辑
论文介绍 Anytext: Multilingual Visual Text Generation and Editing
关注微信公众号: DeepGoAI
项目地址:https://github.com/tyxsspa/AnyText(已经3.3k+)
论文地址:https://arxiv.org/abs/2311.03054
本文介绍一款基于扩散模型的多语言视觉文本生成与编辑工具AnyText。其旨在图像中渲染准确且连贯的文本。AnyText 通过一个包含辅助潜在模块和文本嵌入模块的扩散流程实现文本的生成或编辑,可以在图像中无缝整合文本,支持多种语言,是首个针对多语言视觉文本生成的工作。
 上图展示了论文中的 文字生成和编辑的效果。可以说是非常逼真且自然。不仅如此,对于文字编辑,可以实现高质量的篡改编辑,属实是非常惊艳。
上图展示了论文中的 文字生成和编辑的效果。可以说是非常逼真且自然。不仅如此,对于文字编辑,可以实现高质量的篡改编辑,属实是非常惊艳。
 这里展示了更多编辑的效果,在不规整的掩码下,依然可以做到毫无违和感的编辑效果。
这里展示了更多编辑的效果,在不规整的掩码下,依然可以做到毫无违和感的编辑效果。
方法概述
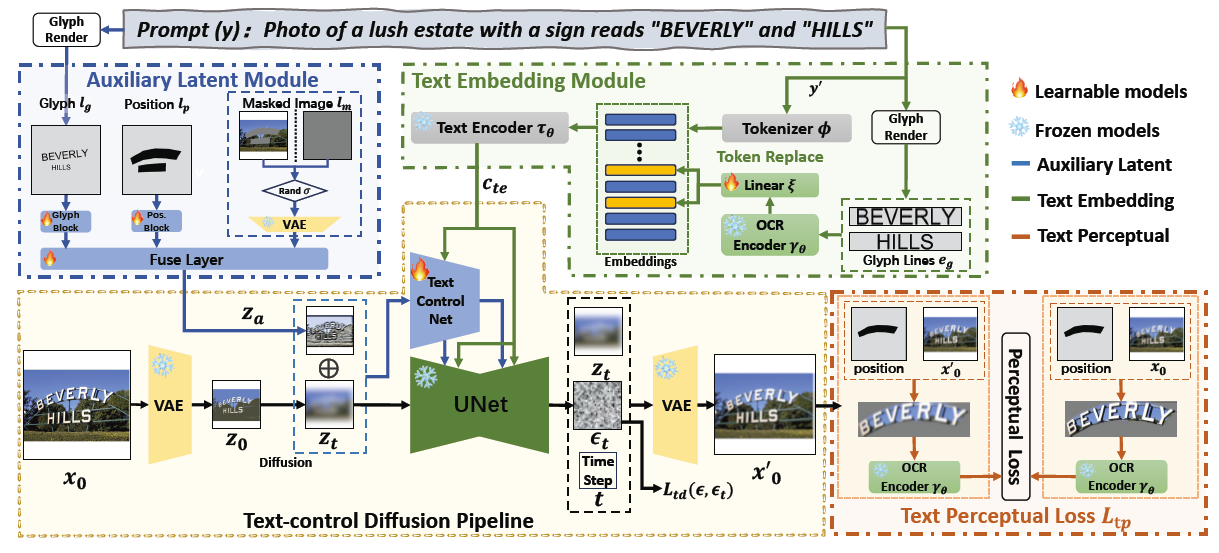 AnyText的框架,包括以下模块:
AnyText的框架,包括以下模块:
-
辅助潜在模块(Auxiliary Latent Module) :该模块使用文本符号、位置和遮罩图像等输入来生成文本生成或编辑的潜在特征。 -
文本嵌入模块(Text Embedding Module) :采用OCR模型编码笔画数据为嵌入,这些嵌入与来自分词器的图像标题嵌入混合,生成与背景无缝集成的文本。 -
文本控制扩散管道(Text-Control Diffusion Pipeline) :负责处理和生成文本,确保生成的文本与图像背景自然融合。 -
文本感知损失(Text Perceptual Loss) :在训练过程中使用,进一步提高生成质量。
工作流程大致如下:
-
输入处理 :首先通过辅助潜在模块处理输入数据(文本符号、位置和遮罩图像等),生成用于后续文本生成或编辑的潜在特征。 -
文本嵌入 :使用文本嵌入模块处理OCR模型编码的笔画数据和图像标题嵌入,为扩散管道提供所需的文本信息。 -
文本生成与编辑 :结合潜在特征和文本嵌入,通过文本控制扩散管道生成或编辑图像中的文本,确保文本与图像背景的自然融合。 -
损失计算 :在训练过程中,使用文本感知损失进一步优化模型性能,提高文本生成的准确性和自然度。 论文中主要训练辅助潜在模块,文本嵌入模块以及文本控制扩散管道中的部分参数,如ControlNet。训练目标定义为:
文本控制扩散管道
-
潜在表示生成:首先,使用变分自编码器(VAE)处理输入图像 ,生成潜在表示 。这里, 代表通过因子 下采样的特征分辨率, 表示潜在特征维度。
-
噪声添加:然后,潜在扩散算法逐步向 添加噪声,生成噪声潜在图像 ,其中 表示时间步。
-
条件集成:给定一组条件,包括时间步 ,辅助特征 由辅助潜在模块生成,以及文本嵌入 由文本嵌入模块生成,文本控制扩散算法应用网络 来预测添加到噪声潜在图像 的噪声,目标函数为:
辅助潜在模块
AnyText 使用三种辅助条件来产生潜在特征图 :字形 ,位置 和遮罩图像 。字形 通过在基于其位置的图像上渲染文本生成,位置 通过在图像上标记文本位置生成,在训练阶段,文本位置从OCR检测或手动注释获得;在推理阶段, 从用户输入获得。遮罩图像 指示在扩散过程中应保留的图像区域。通过融合层 合并 、 和 ,生成特征图 ,表示为 。 其中, 表示卷积融合层, 代表处理字形的模块, 代表处理位置的模块, 是VAE编码器,用于处理遮掩图像 。生成的特征映射 集成了文本的字形、位置和上下文背景信息。
文本嵌入模块
在AnyText中,作者提出了一种新颖的方法来解决多语言文本生成的问题。具体来说,作者将字形线条渲染成图像,编码字形信息,并替换来自标题的嵌入(caption tokens)。这些文本嵌入不是逐个字符学习的,而是利用了一个预训练的视觉模型,特别是PP-OCRv3的文本识别模型。然后将替换后的嵌入输入到基于Transformer的文本编码器作为标记,以获得融合的中间表示,这将被映射到UNet的中间层,使用交叉注意力机制。由于利用图像渲染文本,而不完全依赖于特定语言的文本编码器,作者的方法显著增强了多语言文本的生成。 文本嵌入模块的表示 定义为 。 其中 是处理过的输入标记 (caption)。然后在标记化和嵌入查找后获得标题嵌入(caption embeddings)。然后,每行文本被渲染到一个图像上,得到 。请注意, 只是通过在图像中心渲染单个文本行生成的,而 是通过在单个图像上的它们的位置渲染所有文本行产生的。然后图像 被输入到一个OCR识别模型 中以提取特征,然后应用一个线性变换 作为文本嵌入,以确保其大小与标题嵌入匹配。最后,所有标记嵌入都使用CLIP文本编码器 进行编码。
文本感知损失
作者提出文本感知损失来进一步提高文本生成的准确度。假设 代表去噪网络 预测的噪声,作者可以结合时间步 和噪声潜在图像 来预测 。这可以进一步与VAE解码器一起使用,以获得原始输入图像的近似重建,记为 。 通过从潜在空间到图像空间的转换,作者可以进一步监督文本生成到像素级别。借助位置条件 ,作者可以准确地定位生成文本的区域,并与原始图像 中的相应区域进行比较,专注于文本自身写作的正确性,排除背景、字符位置、颜色或字体样式等因素的干扰。因此,作者采用PP-OCRv3模型,作为图像编码器。通过对 和 在位置 进行裁剪、仿射变换、填充和标准化等操作,作者得到图像 和 作为OCR模型的输入。通过利用得到的在全连接层之前特征图 和 。这两者分别表示原始和预测图像位置 中的文本信息。文本感知损失表示为:
通过施加均方误差(MSE)惩罚,作者尝试最小化预测图像和原始图像在所有文本区域的差异。由于时间步 与文本质量相关,作者需要设计一个权重调整函数 。已经发现设置 是一个好的选择,其中 是扩散过程中的系数。
总结
AnyText 是一种先进的视觉文本生成与编辑工具,旨在改善和优化图像中的文本渲染。通过结合辅助潜在模块和文本嵌入模块,AnyText 能够在多种语言环境下生成清晰、准确的文本,并且可以轻松地集成到现有的扩散模型中,以提高文本的渲染和编辑质量。此外,AnyText 支持多行文本生成、适应变形区域的文本书写、多语言文本生成和编辑,以及插件式与现有模型的集成,展现了其在视觉文本处理领域的强大功能和灵活性。研发团队通过引入文本控制扩散损失和文本感知损失进行训练,显著提高了写作的准确性,使 AnyText 成为处理图像中文本问题的有力工具。此外,AnyText 项目还贡献了首个大规模多语言文本图像数据集 AnyWord-3M (目前还没有开源),为学术研究和实际应用提供了丰富资源。
其他更多细节请参阅论文原文
关注微信公众号: DeepGoAI
本文由 mdnice 多平台发布
这篇关于AnyText: 多语言视觉文本生成与编辑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








