多语种专题

GPT-SovitsV2,支持多语种,多音字优化,更好的音色,ZeroShot(WIN/MAC)
语音克隆项目GPT-Sovits发布了V2版本,在早些时候做了V1版本的整合包,但是那个版本的整合包操作比较麻烦,上手难度高。正好趁着V2,一起更新了。 【GPT-SovitsV2,支持多语种,多音字优化,更好的音色,ZeroShot(WIN/MAC)】 https://www.bilibili.com/video/BV12MW2e4Ebx/?share_source=copy_web&v

C#下WinForm多语种切换
这是应一个网友要求写的,希望对你有所帮助。本文将介绍如何在一个WinForm应用程序中实现多语种切换。通过一个简单的示例,你将了解到如何使用资源文件管理不同语言的文本,并通过用户界面实现语言切换。 创建WinForm项目 打开Visual Studio,创建一个新的WinForm项目。 在项目创建向导中,选择合适的模板并填写项目名称。 添加资源文件 在Solution Explor

全球首个多语种手语视频生成模型诞生:SignLLM
近日,一项名为 SignLLM 的新型 AI 技术取得了突破性进展,或将彻底改变听障人士的沟通方式。作为全球首个多语种手语生成模型,SignLLM 能够将输入的文本或语音指令,实时转化为对应的手语手势视频,为打破语言障碍、促进信息无障碍传播带来了革命性希望。 全球首个文本转多语种手语视频模型生成视频 长期以来,由于手语本身的复杂性和多样性,以及缺乏高质量数据的支持,手语翻译一直

开源大型语言模型概览:多语种支持与中文专注
开源大型语言模型概览:多语种支持与中文专注 开源大型语言模型概览:多语种支持与中文专注什么是大型语言模型如何工作大型语言模型的发展应用领域 开源大语言模型概览支持多种语言的开源LLMsLLaMA(由Meta开发)BERT(由Google开发) 支持中文的开源LLMsYAYI 2Baichuan-13BChinese GPT (由THUNLP开发)MOSS 其他重要的开源LLMsMistral

提供多语种客户服务的正确方法:让你更接近全球客户
优质的客户支持是任何成功企业的核心。每位客户都希望得到全天候的及时响应。事实上,根据《哈佛商业评论》的研究报告,快速响应会促使人们在未来支付更多的费用。此外,在与全球客户打交道时,您的沟通必须超越语言障碍。用客户的语言与他们交流可以帮助您在购买周期的各个阶段建立信任,包括售后支持。 如果您打算尝试提供多语种客户支持,以下四种方法可以帮助您制定正确的多语种支持策略。 1、聘用会为多种语言的客户支
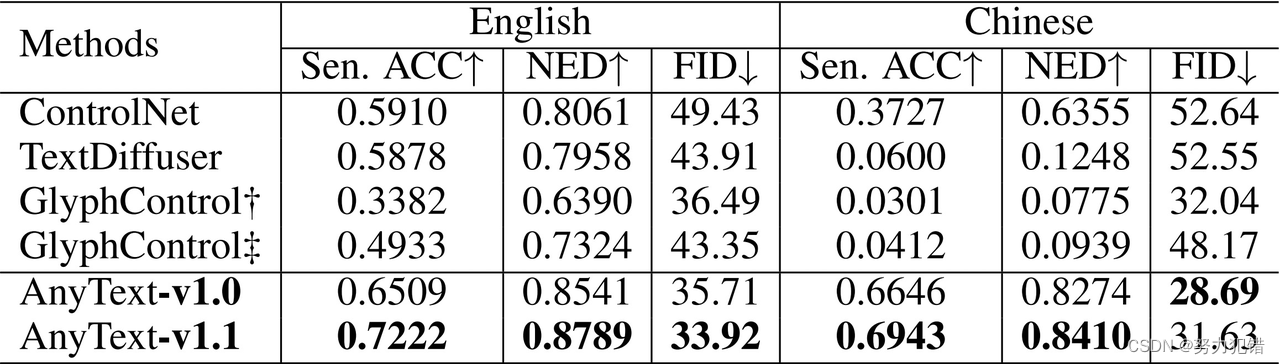
阿里AnyText:多语种图像文字嵌入的突破
模型简介 随着Midjourney、Stable Difusion等产品的兴起,文生图像技术迅速发展。然而,在图像中生成或嵌入精准文本一直是一个挑战,尤其是对中文的支持。阿里巴巴的研究人员开发了AnyText,这是一个多语言视觉文字生成与编辑模型,旨在解决这些难题。 Github:https://github.com/tyxsspa/AnyText AI快站模型免费加速下载:https:/
SemEval 2022 | 多语种新闻相似度评测冠军系统简介
每天给你送来NLP技术干货! 来自:哈工大讯飞联合实验室 在前不久落下帷幕的第十六届国际语义评测比赛(The 16th International Workshop on Semantic Evaluation, SemEval 2022)中,哈工大讯飞联合实验室(HFL)在多语种新闻相似度评测任务(Task 8: Multilingual News Article Similarity)上以
【Coggle 】汽车领域多语种迁移学习挑战赛
文章目录 活动背景一、赛题介绍二、打卡任务任务1:比赛报名步骤1:报名比赛步骤2:下载比赛数据(点击比赛页面的赛题数据)步骤3:解压比赛数据,并使用pandas进行读取;步骤4:查看训练集和测试集字段类型,并将数据读取代码写到博客; 活动背景 Coggle 组织了一次竞赛训练营活动,希望能够帮助大家入门数据竞赛。下载比赛数据(点击比赛页面的赛题数据)为其中的一个挑战项目,
ACL 2020 | 面向序列标注任务的“集百家所长”多语种模型来了!
上海科技大学和阿里巴巴发布了一篇被ACL2020收录的论文《Structure-Level Knowledge Distillation For Multilingual Sequence Labeling》,论文针对在自然语言处理中的序列标注任务中,多语种模型的表现不及各个语种单独的模型做出了改进,通过知识蒸馏的手段,从各个单语种模型中学习到结构层级的知识,训练一个新的多语种模型,缩短了多语种模

【数据挖掘竞赛】——汽车领域多语种迁移学习挑战赛(科大讯飞)
🤵♂️ 个人主页:@Lingxw_w的个人主页 ✍🏻作者简介:计算机科学与技术研究生在读 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+ 目录 一、赛事背景 二、赛事任务