本文主要是介绍SemEval 2022 | 多语种新闻相似度评测冠军系统简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
每天给你送来NLP技术干货!
来自:哈工大讯飞联合实验室
在前不久落下帷幕的第十六届国际语义评测比赛(The 16th International Workshop on Semantic Evaluation, SemEval 2022)中,哈工大讯飞联合实验室(HFL)在多语种新闻相似度评测任务(Task 8: Multilingual News Article Similarity)上以显著的领先优势斩获冠军。本期我们将对这个任务的夺冠系统进行简要介绍,更多具体细节请参考我们的论文。
论文标题:HFL at SemEval-2022 Task 8: A Linguistics-inspired Regression Model with Data Augmentation for Multilingual News Similarity
论文作者:徐梓航,杨子清,崔一鸣,陈志刚
论文链接:https://arxiv.org/abs/2204.04844
项目地址:https://github.com/GeekDream-x/SemEval2022-Task8-TonyX

任务介绍
SemEval-2022 Task 8是多语种新闻相似度评价任务。任务中给出来自多种语言的新闻篇章对,参赛队伍需要利用模型判定每一对新闻篇章是否描述了同一个事件,并以1至4分的范围为两篇新闻的相似度打分。任务共计覆盖10种语言,包括阿拉伯语、德语、英语、西班牙语、法语、意大利语、波兰语、俄语、土耳其语和中文。与普通的文章相似度任务相比,该评测任务强调考察模型的跨语言理解能力,并要求模型把握文章中描述的具体事件,而不仅是写作风格。

SemEval 2022 Task8 数据样例
系统介绍
我们在语言学特征的启发下,基于多语言预训练模型和回归任务框架,针对当前比赛任务制定了一系列优化策略,最终系统结构如下图所示。整个系统流程包括数据处理、模型训练和预测结果后处理三个阶段:
-
数据处理:从指定网页爬取数据,进行数据清理,对清理后的数据做数据增强;
模型训练:采用基于XLM-R的多语言模型构建的多任务回归打分模型;
后处理:基于任务数据本身特性,对预测得分进行裁剪。
下面将针对部分主要优化技巧进行简要介绍。
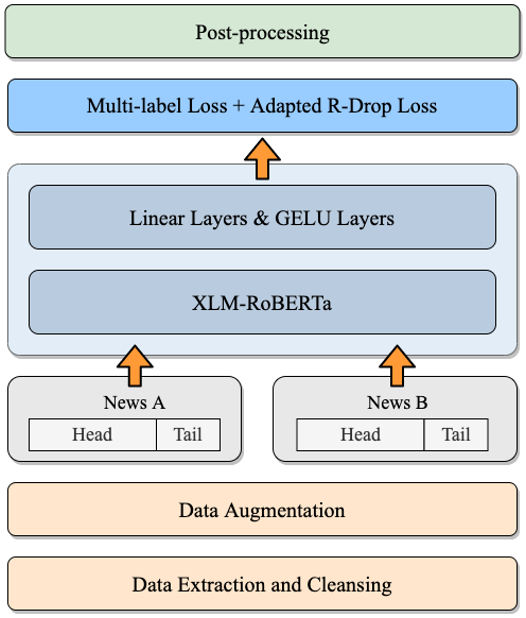
SemEval 2022 Task8 HFL系统结构
1、数据增强
通过对比训练集和测试集数据分布,我们发现测试集多出3种语言及7种跨语言组合且非英语种占比差别巨大,因此,我们基于训练集进行了两阶段数据增强。首先,为了丰富训练集本身的非英语种数据,我们通过回译对所有包含非英语种的样本对进行了翻倍扩充。而后,通过直译对测试集新出现的语言和跨语言组合进行增强。为了保证增强后的数据具有足够强的语义丰富性,我们选用不同的原语言数据进行直译;同时,我们考虑了不同语种间基于语系语族的亲疏关系,设计了不同增强比例,具体方案如下表。对于和英语相近的语言,增强的样本较少(如德-法对新增317条样本);而和英语关系较远的语言,则增强了较多样本(如中-英对新增了800条样本)。
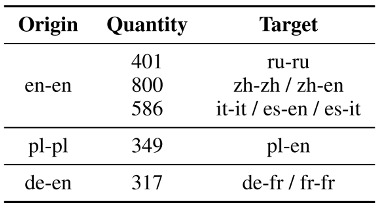
直译数据增强配对表
2、头尾拼接
由于XLM-RoBERTa所能处理的文本长度有限且数据集中有74%的篇章都长于256个token, 因此考虑对样本进行截取。新闻篇章有鲜明的结构特性,即头部(含标题)和尾部的信息量相对更大,因此我们决定将头尾进行拼接并尝试了不同比例,最终根据对照实验结果,选取头尾长度比例约4:1进行裁剪拼接。
3、多任务学习
如任务介绍部分所示,数据集提供了每个新闻篇章样本从Tone、Narrative等七个维度的相似性打分。尽管最终评测只针对Overall这个整体性维度,但我们认为合理地利用其它六个维度的信息将有助于提升整体性评估的效果,于是我们尝试了多种维度占比方案,发现当Overall权重提高时,模型最终性能有先提升后小幅降低的现象,最终模型选择性能达到峰值所对应的Overall权重范围。
4、Adapted R-Drop
R-Drop被证明是一种简单且有效的基于Dropout的正则化技术,为了更好地适应当前的任务,我们将其中的KL-divergence loss替换为MSE loss,并且通过超参来控制多任务回归学习损失和R-Drop损失的比例。在此基础上,我们还探索了不同forward次数对模型性能的影响。公式如下图所示:
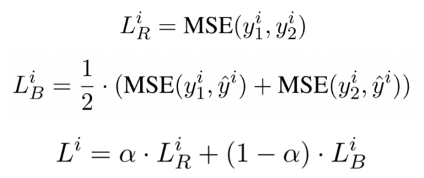
Adapted R-Drop Loss计算公式
其中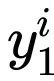 和
和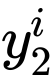 是样本两次forward的预测值,
是样本两次forward的预测值,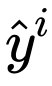 是样本真实值,α控制两种损失的相对强度。
是样本真实值,α控制两种损失的相对强度。
5、其他尝试
除了上述方法,我们还尝试了模型加大增宽、多种获取篇章向量的方案如不同层pooling、基于双塔结构的交互回归框架等,在此任务上这些方法的表现都明显逊色于我们的最终方案。
实验结果
基于多组消融实验,上述提及的五种有效提升方案单独的优化能力如下表所示。
我们针对数据增强做了对照实验(+DA),基于增强集训练得到的模型在测试集上性能提升最为明显,体现了该任务中数据丰富度的重要性。
我们基于非数据增强场景,对其他优化技巧做了对照实验(头尾拼接、多标签、Adapted R-drop、多层分类层等),其中Adapted R-Drop效果最佳。
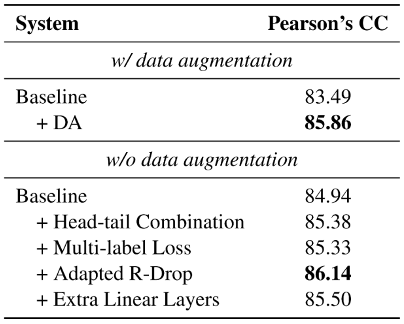
各优化方案实验结果
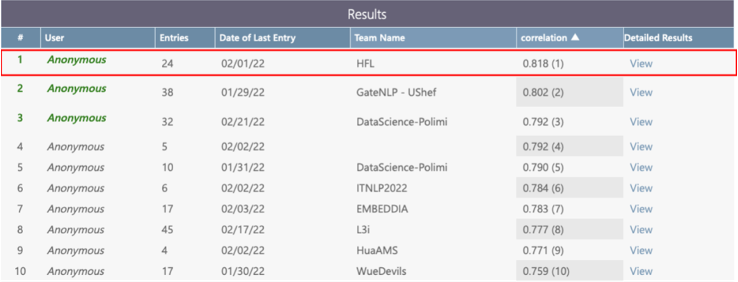
多语种新闻相似度评测任务最终榜单:哈工大讯飞联合实验室排名第一
结论
在三阶段系统框架中,数据处理部分主要使用了两种数据增强的方案,模型训练部分集成了头尾拼接、多任务、Adapted R-Drop和额外线性层等所有有效方案,后处理部分主要进行了打分裁剪和模型融合等工作,最终使得系统整体性能较baseline有较为显著的提升。在多语言新闻相似度场景中,上述优化方案较为充分地挖掘了多语言预训练模型的能力,后续研究工作中,可以尝试添加各语言规则相关特征来进一步提升系统在低资源语言上的表现。
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing,非常简单且有效尤其在数据不足的情况下
这篇关于SemEval 2022 | 多语种新闻相似度评测冠军系统简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







