本文主要是介绍Python——2020爬取猫眼电影Top100(一系列分析和小白版正则小技巧),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python——2020爬取猫眼电影Top100(详解)
小白我在学习python的过程中看见买的书和csdn上的各位大佬都爬取过猫眼电影Top100当作练习,基本都是用正则表达式进行的爬取,那么我也用正则表达式进行爬取,并说一下正则表达式在编写的时候的一些小技巧,当然更方便的爬取也可以用xpath和pyquery中的类似于css选择器的语法进行爬取更为简单。
首先用谷歌浏览器打开目标网页,F12查看各类响应进行分析,主要看请求头和响应头的内容。(上图!)
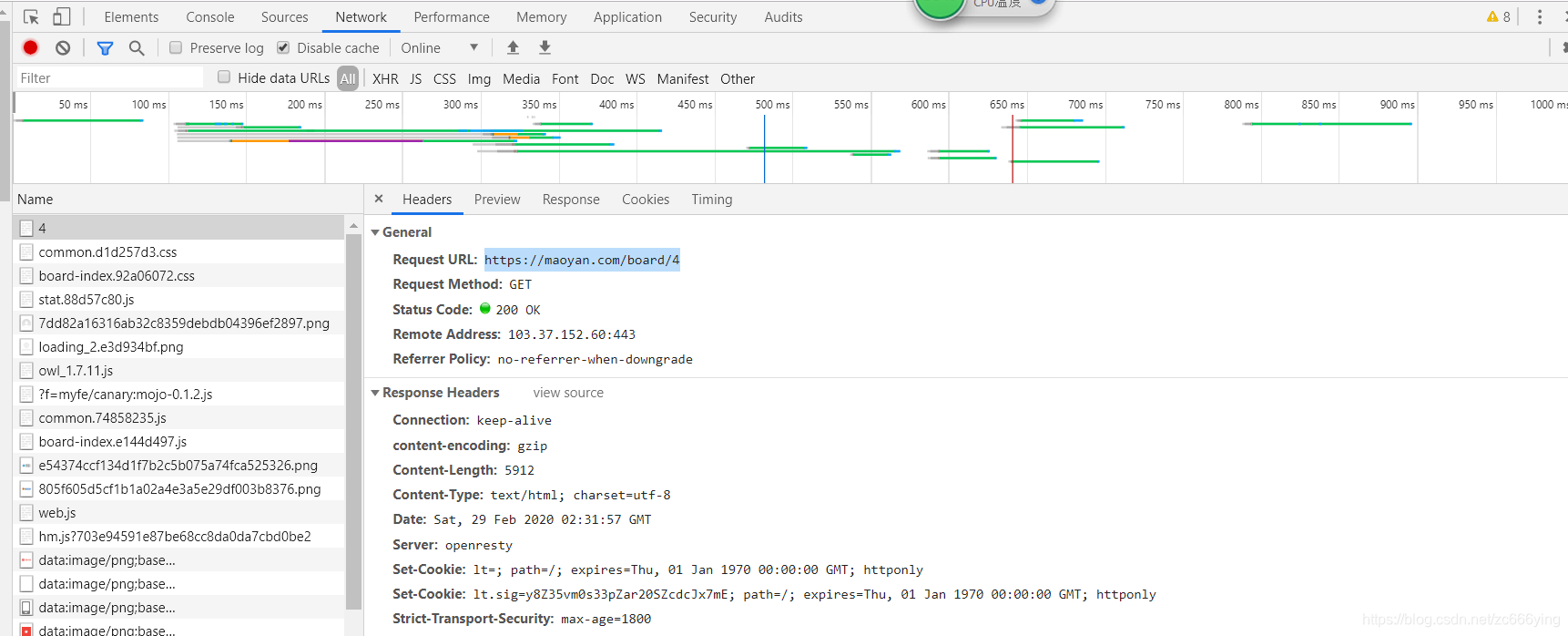
我看的是名为4的请求响应,该就是包括了网页源码的请求响应,进行分析后可以看看其响应的展示(Preview)和返回内容(Response)。从中可以或多很多信息:
在General中:
我们可以得到网页的请求URL链接,请求方式get,返回响应码(200),以及远程服务器的地址和端口,在这它增加了Reffer Policy:Referrer判别策略,那么我们就简单介绍一些这个策略,这也是我在大佬博客中看到的。。
'''
no referrer when downgrade的意思:降级时不推荐。
从一个网站链接到另外一个网站会产生新的http请求,referrer是http请求中表示来源的字段。
no-referrer-when-downgrade表示从https协议降为http协议时不发送referrer给跳转网站的服务器。
在页面引入图片、JS 等资源,或者从一个页面跳到另一个页面,都会产生新的 HTTP 请求,浏览器一般都会给这些请求头加上表示来源的 Referrer 字段。Referrer 在分析用户来源时很有用,有着广泛的使用。但 URL 可能包含用户敏感信息,如果被第三方网站拿到很不安全。
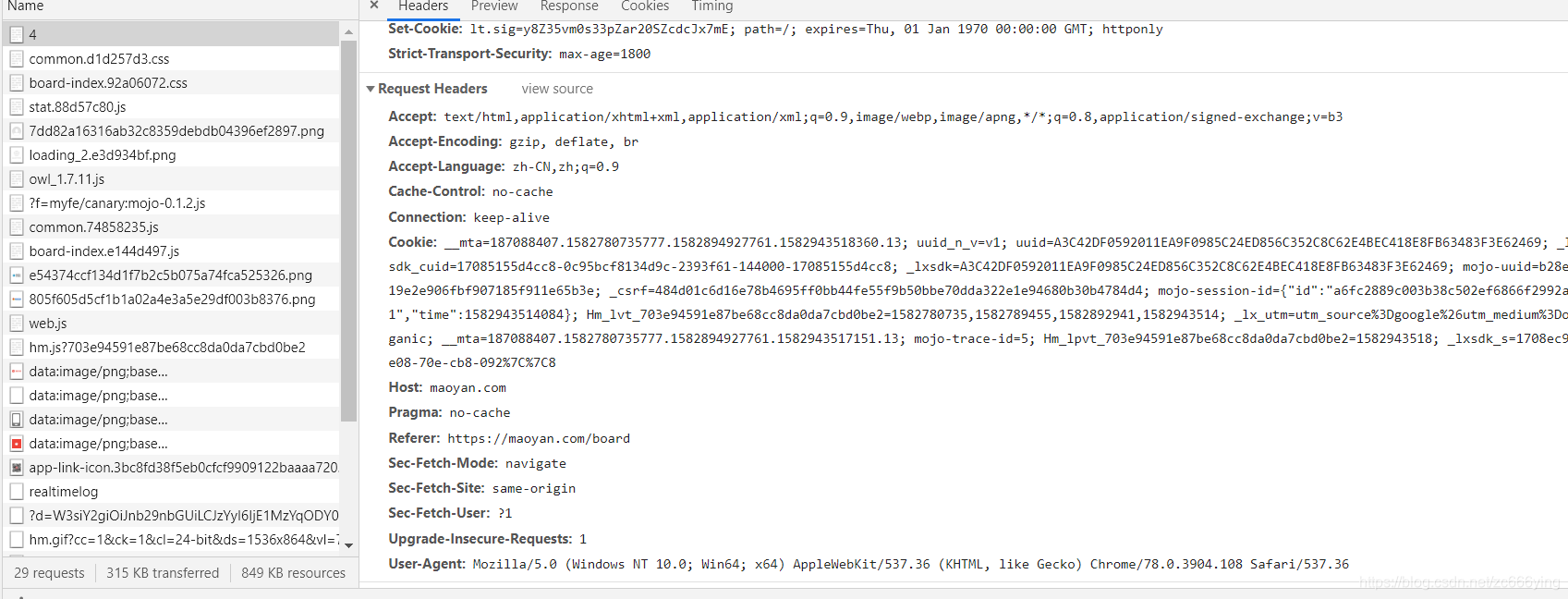
'''在Response Headers 中我主要关心的是 Content-Type:文档类型,指出返回的数据类型是什么。在这里返回的是 text/html ,也就是网页源码,也就是我想要的东西。
在Resquest Headers中,我最关心的是User-Agent,Cookies,Referer,Accept,这几个内容,一般在自己构造头请求的时候,一定会设置的是User-Agent,其次是Referer,Accept,最后还请求不成功的话,会使用session来保持会话,获得cookies,用带有cookies再去请求,一般就会解决,这个在我另一篇微博中有详细的说明哟!给出其链接。。。
HTTP请求过程——Chrome浏览器Network详解
在进行分析完成之后就可以进行正式的爬取,首先来看源码,来分析自己想获取的内容所在的各种标签,这里我看源码的时候,并不是直接用Elements选择卡直接产看对应的源码,因为那里的源码可能经过JavaScript操作而于原始请求不同,我选择再刚才 name 为 4 的请求中查看源码,如图:
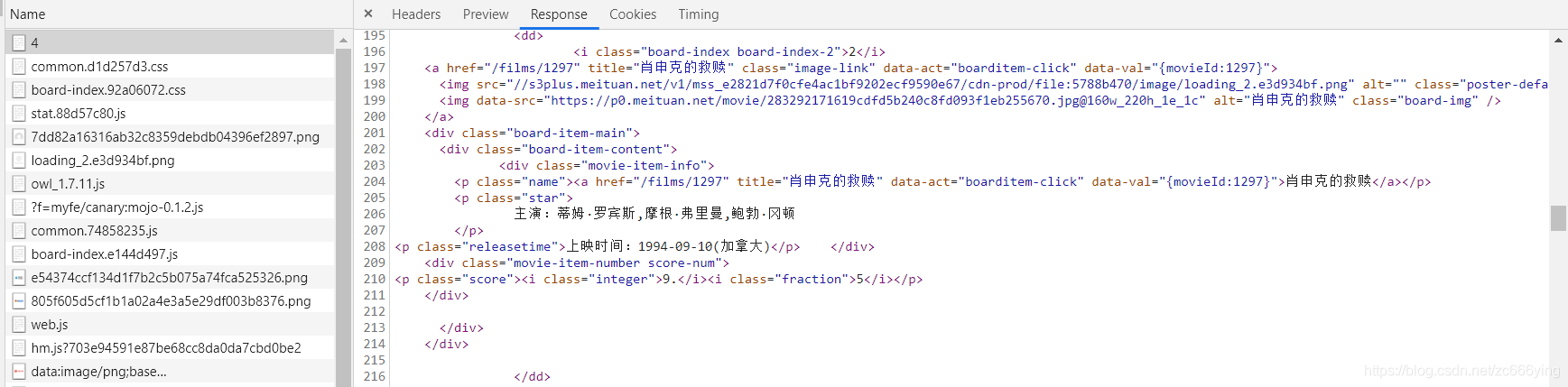
在这里源码就是最原始的请求获得的源码,那么我们来对其 进行一些分析:
可以看出关于一部完整的信息全部封装在 dd 节点当中,然后便会看到它的排名,在 i 标签当中,其 class 为 board-index board-index-2,在用正则表达对其进行提取时,首先我们可以写出一个标志位,就好像这里的 board-index ,其余的代码用万能公式来代替 .? 非贪婪匹配,自己想获得信息用()括起来,如(.?),这样在返回的时候就只会返回括号当中的内容,所以对于排名的正则表达式如下:
<dd>.*?board-index.*?>(.*?)</i>接着看电影封面图片,其链接在 img 标签当中,尝试后得出我们想要的时第二个 img 标签当中的链接,选取标志位 data-src ,那么正则表达式便可以变为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)"以此类推,下面还可以得到电影的演员,上映时间等信息,最后的正则表达式为:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>然后分析网页链接的特点,十分简单,直接复制两个观察,太容易看出了:
#https://maoyan.com/board/4?offset=10
#https://maoyan.com/board/4?offset=90接下来就直接进行爬取了,由于难的正则表达式和构造头部信息已经分析过,那么我就直接上代码啦:
import requests
import time
import reheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36','Referer': 'https://maoyan.com/board'}def getHTMLTest(url):try:r = requests.get(url,headers = headers,timeout = 2)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:print('请求网页错误')return ''def extract_information(text):#将正则表达式编译以可以重复使用pattern = re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star.*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>',re.S)information = re.findall(pattern,text)return information'''
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
'''
def output(information):for item in information:yield {'index':item[0],'image_url':item[1],'name':item[2],'actor':item[3].strip(),'time':item[4],'score':item[5].strip() + item[6].strip()}if __name__ == '__main__':#该URL用于测试url = 'https://maoyan.com/board/4?offset=0'url_list = []#构造猫眼电影排行榜所有网页URL链接for i in range(10):i = str(i*10)url_list.append('https://maoyan.com/board/4?offset='+ i)text = getHTMLTest(url)time.sleep(4)#print(text)information = extract_information(text)#print(information)for i in output(information):print(i)这里还需要说明的时在处理正则返回的时候,因为返回的内容会出现空格符,在这里直接用字符串的 strip()函数进行处理,Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
在进行爬取的时候,设置等待时间,这个也很重要,因为当进行大规模爬取的时候,请求响应速度过快,网站便会发现,封了你的Ip地址,当然应对次反爬,可以设置IP池,更换IP,我感觉刚开始的时候还是用time.sleep()方法直接设置时间吧。
还有就是将数据用yield的方法采用字典的方式返回,方便与以后保存,后台的执行结果如下图:

这样我们就完成啦,虽然很简单,但对我来说可以每一次爬取都是一次练习,分析,大家有什么意见和看法的时候可以评论私信,兄弟们一起成长!
这篇关于Python——2020爬取猫眼电影Top100(一系列分析和小白版正则小技巧)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




