本文主要是介绍python实战 | 爬取贝壳房源总数据价格提取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取贝壳房源总数据(楼盘,地址,价格,户型,面积)
第二章,房源价格爬取
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容,了解python爬虫。
今天带来的是爬取贝壳房源总数据的第二小节,房源价格的爬取
以下是本篇文章正文内容,代码可供参考
一、爬虫是什么?
在进行大数据分析或者进行数据挖掘的时候,数据源可以从某些提供数据统计的网站获得,也可以从某些文献或内部资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大。此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,从而进行更深层次的数据分析,并获得更多有价值的信息。
在使用爬虫前首先要了解爬虫所需的库,因为今天爬取的房源的价格所以除了(requests)库还有(bs4)函数。
二、使用步骤
1.引入库与函数
代码如下(示例):
import requests
from bs4 import BeautifulSoup
2.读入数据
代码如下(示例):
# 明确爬取的网站
response = requests.get("https://cd.fang.ke.com/loupan")# 提取文件
html = response.text# 使用bs4 把html文件构造成树,使用默认的解析器
soup = BeautifulSoup(html)# 使用函数 find_all() 在树上查找span节点
result = soup.find_all("span", class_="number")
print(result)# 提取span里的数据
for i in result:print(i.string)
该处使用bs4把html文件构造成一棵树,再用函数find_all()查找树上的span节点。
3.运行代码如下
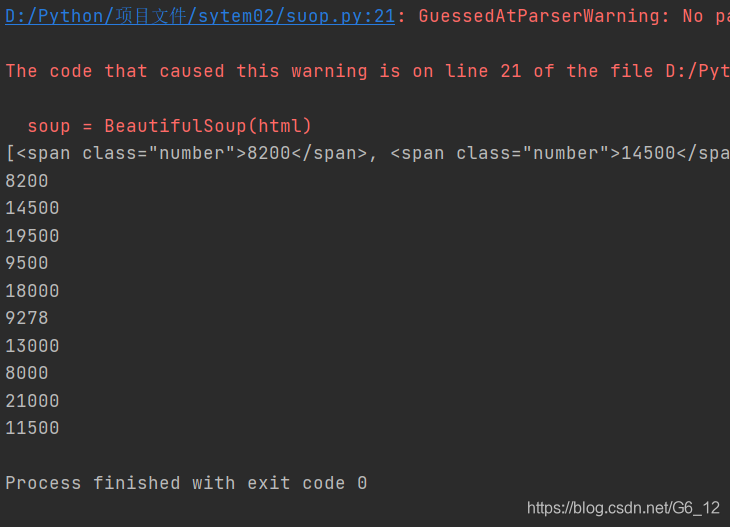
代码运行无报错
总结
这里对文章进行总结:今天分析这波代码目的是为了让大家清晰明亮的了解python爬虫的运作,和大家一起学习
以上就是今天要讲的内容,本文仅仅简单介绍了函数bs4的使用,而requests提供了大量能使我们快速便捷地爬取数据。
小郭锅在此希望对你的编程之旅有所帮助,记得点赞关注哦
如果有哪些地方写得不对还请大佬留言提出
源代码文件已经放入资源里面需要的可以自行提取
这篇关于python实战 | 爬取贝壳房源总数据价格提取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




