本文主要是介绍模型汇总15 领域适应性Domain Adaptation、One-shot/zero-shot Learning概述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
几乎所有希望在实际应用中使用机器学习算法的人都会遇到领域适应性(Domain Adaptation)的问题:我们在固定的source domain建立了模型,但希望把我们的模型部署到另外一个或几个不同的target domain中。领域的适应性问题在机器学习实际应用的各个领域都非常常见。
获取最新消息链接:获取最新消息快速通道 - lqfarmer的博客 - 博客频道 - CSDN.NET
比如,语音识别中。一个大规模的语音识别系统,需要对各种带有噪声或口音的语音,都能很好的识别。比如图1中描述的,不同人说话,有不同的口音和语速。
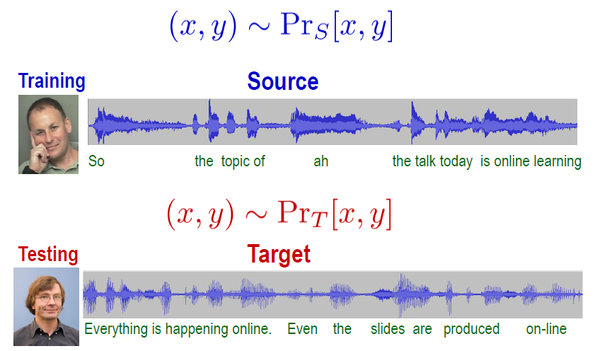
图1 语音识别中的domain adaptation问题
文本处理系统,基于新闻(news)训练的模型,我们希望该模型对于博客(Blog)或论坛(forum)也同样适用。

图2 NLP领域中的domain adaptation问题
图像识别领域,我们从亚马逊的网站上得到了很多没有背景的物体的图片来训练我们的模型,然后希望把训练好的模型用于识别实际生活中存在背景的物体图片。

图3 图像识别领域的domain adaptation问题
这都牵扯到领域适应性(Domain Adaptation)的问题。因此,本文主要介绍下什么是domain adaptation问题,有哪些方法用于解决domain adaptation问题。最后再介绍下domain adaptation / Transfer learning中两个特例,单例学习(one-shot learning)和零例学习(zero-shot learning)
1、领域适应性(Domain adaptation)定义
获取最新消息链接:获取最新消息快速通道 - lqfarmer的博客 - 博客频道 - CSDN.NET
Domain Adaptation是迁移学习(Transfer Learning)中的一种,在之前讲迁移学习分类的时候,我们提到过。在很多机器学习任务中,模型在训练(training)时所采用的样本和模型在测试(testing)时所采用的样本分布(domain adaptation)不一致,导致了领域适应性问题(Problem of Domain Adaptation)。Domain Adaptation尝试去建立一个在training和Testing都适用的模型,用概率统计表示成如下形式:
P(X)不等于P(X’);P(Y|X)约等于P(Y|X’)
2、领域自适应相关基本概念和基本算法
1)、基本概念
协移(Covariate Shift):
Ps(y|x) = Pt(y|x)
Source domain中,基于观测样本x的输出y的条件概率Ps(y|x),与Target Domain中,jiyuguance样本x的输出y的条件概率Pt(y|x),是相同的,即模型不管输入的x是来自于那个分布,他们的输入标签为y的概率是一样的,这种情况成为协方差偏移。
Single Good Hypothesis:
一定存在一个最后的模型或者假设H*,使source domain中关于H*的误差Es(H*)和target domain中关于H*的误差Et(H*)都很小。
领域的差异与误差(Domain discrepancy and Error):
source domain和target domain要有一定大的重叠的交集。如图4所示。
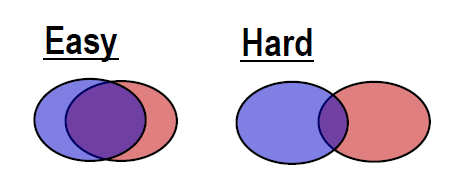
图4 领域的差异与误差问题
2)、domain adaptation算法分类
(1)、按是否有监督与domain adaptation相关的算法分类:
半监督适应性算法(Semi-supervised Adaptation):基于Covariate Shift的方法和基于共享表示(shared representation)学习的方法。
监督适应性算法(Supervised Adaptation):基于特征的方法(Feature-Based Approaches)和基于参数的方法(Parameter-Based Approach)。
(2)、基于原理分类
基于实例或权值重写的方法(Reweighting/Inastance-based methods):通过重写source domain的标签数据的权重(weight)来矫正样本偏差(sample bias),使source domain的样本与target domain的样本尽可能靠近。
图5 基于实例或权值重写的domain adaptation方法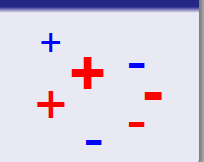 图5 基于实例或权值重写的domain adaptation方法
图5 基于实例或权值重写的domain adaptation方法 基于特征的方法(Feature-based methods):在source domain和target domain靠近的地方,寻找一个新的、常见的(common)表示空间(representation space)(projection,新的特征等等)
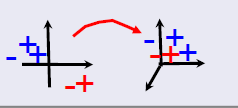
图6 基于特征的domain adaptation方法
基于迭代/调整的方法(Adjustment/Iterative methods):通过向模型中加入一些带标签的伪数据来修改模型。
图7 基于迭代/调整的domain adaptation方法
3、单例学习(One-Shot Learning)
单例学习是迁移学习/Domain Adaptation的一个特例。模型在source domain训练好之后,迁移到target domain,target domain只用一个标记样本去训练模型的参数就可以了。

图8 平衡车单例识别
比如识别平衡车。训练时,source domain有大量标记样本,比如自行车、独行车、摩托车和轿车等类别,模型可以从source domain学到表示车的有效特征,比如有轮子、轮子尺寸大小、有踏板、方向盘或龙头等。测试时,在target domian,只需要一个或很少一些target domain的标记样本,比如只需要在模型可以准确识别车的条件下,给模型一张平衡车的标记图片就可以了。
获取最新消息链接:获取最新消息快速通道 - lqfarmer的博客 - 博客频道 - CSDN.NET
4、零例学习(Zero-Shot Learning)或零数据学习(Zero-data Learning)
零例学习是迁移学习/Domain Adaptation的一个特例。source domain存在带标签的数据,模型在source domain训练好之后,因为在第一阶段的学习已经可以很好分离类别,模型迁移到target domain直接可以使用,不需要任务target domain的标记样本去调整模型参数。source domain 和target domain共享信息。

图9 美国金丝雀的零例识别
比如美国金丝雀的识别。训练时,source domain有大量关于金丝雀的带标记的图片,以及关于图片的额外先验知识(属性,图片的描述,....),我们可以通过训练把先验知识加入到图片识别中去。测试时,模型可以准确识别出金丝雀,通过关于图片额外描述信息知道这是美国的的金丝雀,这样很容易把模型推广到新的类别,在测试集上,把见过的和未见过的图像类别合并起来。
往期精彩内容推荐
模型汇总-14 多任务学习-Multitask Learning概述<纯干货-5>Deep Reinforcement Learning深度强化学习_论文大集合
《纯干货-6》Stanford University 2017年最新《Tensorflow与深度学习实战》视频课程分享
<深度学习优化策略-4> 基于Gate Mechanism的激活单元GTU、GLU
<视频教程-2>生成对抗网络GAN视频教程part6-完整版
这篇关于模型汇总15 领域适应性Domain Adaptation、One-shot/zero-shot Learning概述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






