本文主要是介绍NLP论文阅读记录 - 2022 WOS | 语义提取文本摘要的新方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 1.1目标问题
- 1.2相关的尝试
- 1.3本文贡献
- 二.背景
- 三.本文方法
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 4.6 细粒度分析
- 五 总结
- 思考
前言

A Novel Approach for Semantic Extractive Text Summarization(22)
0、论文摘要
文本摘要是一种缩短或精简长文本或文档的技术。当有人需要快速准确地总结很长的内容时,这一点就变得至关重要。手动文本摘要可能既昂贵又耗时。在总结时,一些重要的内容,例如文档的信息、概念和特征,可能会丢失;因此,包含信息丰富的句子的保留率会丢失,如果添加更多信息,则可以生成冗长的文本,从而提高压缩率。因此,需要在两个比率(压缩和保留)之间进行权衡。该模型通过仅采用长句子并删除压缩率较小的短句子来保留或收集所有信息丰富的句子。它试图通过避免文本冗余来平衡保留率,并通过删除异常值来过滤文本中的不相关信息。它按照原始文档中提到的句子的时间顺序生成句子。它还使用启发式方法来选择最佳集群或组,其中包含摘要最上面句子中存在的更有意义的句子。我们提出的模型提取摘要器克服了这些缺陷,并尝试在压缩率和保留率之间取得平衡。
一、Introduction
1.1目标问题
提取文本摘要是以简洁的形式从文档中提取最相关、信息丰富且有意义的句子的过程。它基于统计和语言特征,根据频率、提示短语、句子提取等选择最相关的特征[1]。为了通过使用不同的技术产生有效且高效的文本提取摘要,已经进行了大量的研究;然而,“压缩率”和“保留率”的问题在所有研究中都是相同的,以至于没有人针对所有提取摘要者面临的上述问题做出努力。下面描述了“压缩率”和“保留率”:“文本摘要器应生成整个文档文本的三分之一,但在压缩过程中保留或保留其有意义的信息”[2]。大多数研究人员已经开发了提取文本摘要器,但是当他们在压缩过程中缩小文档或文本的大小时,文本的保留会变得混乱,并且大多数情况下,摘要器会丢失非常有意义的信息。其中一些失去了特征、内容、概念、信息等。
所提出的提取摘要器通过有效删除任何“异常值”来保留上述标准,这些“异常值”会在摘要中产生不相关的信息,并以日期事件的形式维护事实和数字[3]。首先,它将输入文档或文件作为用户的源文件,并获取表单中的所有信息通过借助句子标记化方法分割文档来收集句子的集合。第二步包括预处理步骤,其中通过删除标点符号、停止“is”、“am”、“are”等单词来执行文本规范化,并通过获取每个单词的词根含义来执行词形还原[4]。第三步,系统通过采用频繁项模式并选择最频繁的项来对句子进行评分,然后计算每个标记或单词的相似度。为了保留其领域约束手段,任何包含不相关信息的单词的部分都不被包括在内;因此,根据最重要的相似性标准,仅选择过滤的域词或信息词[5]。第四步,系统根据文档中过滤最频繁的单词提取句子。最后,通过保留时间顺序并生成摘要来组装所有句子。
自动文本摘要的一般步骤如图1所示:
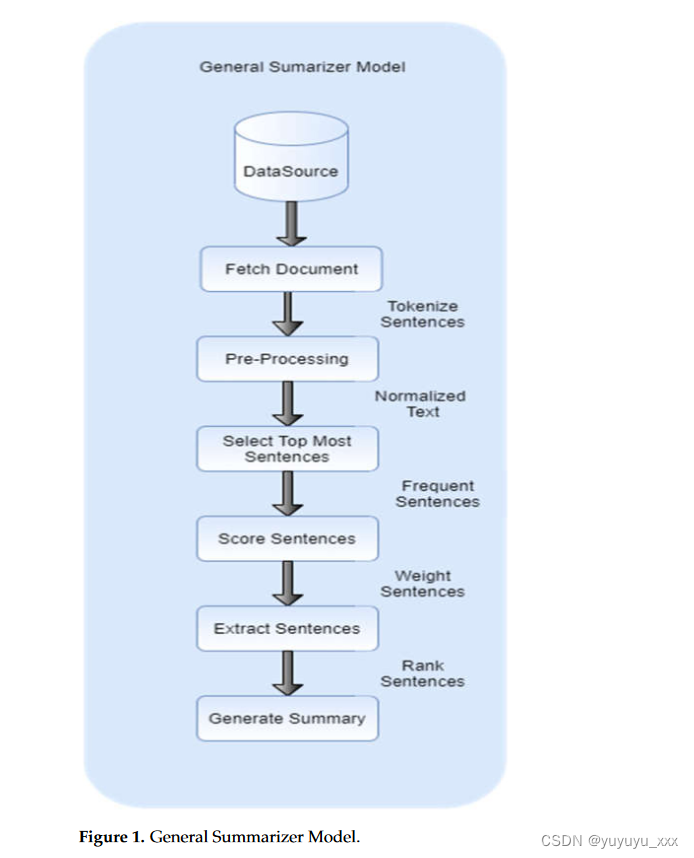
1.2相关的尝试
提取文本摘要模型是根据文本排名和频率开发的,并且是基于单词和基于特征的,在过去几十年中还开发了许多其他进步[6]。然而,所有这些总结者都根据最高排名或功能的选择标准,以及何时选择最高的标准,他们遗漏了一些重要事件,例如重要日期,这些事件显示了与标题和主题非常相关的信息。其次,当我们缩小任何提取摘要器的大小或压缩比时,它会丢失内容、特征、概念和其他重要信息[7]。现有模型的主要局限性之一是它们产生的精度较低且准确度较低,而所提出的模型是试图克服现有文本摘要模型的现有局限性。
我们分析了现有算法的不同缺点,解释如下: Luhn 模型取决于频繁单词的数量除以单词总数。但是,它不适用于单词的最大频率或最小频率。简而言之,它没有语义技术;它只是在 tf-idf 频率上工作。埃德蒙森取决于提示方法、句子位置等。它考虑了大多数包含文档标题或标题的句子。它还借助句子位置来考虑句子的第一段和最后一段,但它没有语义技术。它无法判断句子正文中给出的信息有多重要。 LSA工作于分布语义,计算关键词与剩余文本之间的余弦相似度,并根据最高相似度得分,给出相似度最高的句子;然而,它无法过滤不相关的文本,该模型的主要缺点之一是它无法过滤重复的句子。因此,它产生了冗余。重要事件以日期形式保留在文档中。 LexRank的算法基于特征向量中心性,句子被放置在图的顶点,同时根据语义相似度分配权重,计算句子之间的余弦相似度。在句子重叠期间,还会检索冗余句子,必须将其删除。 TextRank的算法基于特征向量中心性,将句子放置在图的顶点,并根据词汇相似度分配权重。该模型的主要缺点之一是句子重叠,这显示出冗余。在KL散度中,冗余只会降低算法的效率,因为添加冗余句子会影响单词的一元分布,并增加与源文档集的散度。表1显示了基于算法缺点的比较。

这里,符号4表示“允许”,符号×表示“不允许”。第一列显示了不同文本摘要器的特征,包括本文提出的文本摘要器。第二列到第七列显示了它们之间基于第一列中显示的选定特征的比较。如表所示,LexRank的算法允许冗余,而本文提出的算法不允许。其余功能遵循相同的标准,例如不同的算法允许某些功能,而有些则不允许其他功能。从表中可以清楚地看出,所提出的模型的主要优点之一是与其他算法相比,它允许所有特征并排除冗余。所提出算法的详细结果显示在结果部分
本文包含五个部分。第1节介绍了本文所开展的研究工作。第 2 节描述了与文本摘要技术相关的相关工作。第 3 节描述了该方法的实施以及实验所用的数据集。第 4 节介绍了所进行的实验的结果。第五节介绍了结论和未来的工作。
1.3本文贡献
总之,我们的贡献如下:
二.背景
文本摘要系统由 Luhn 和 Baxendle 于 20 世纪 50 年代初开始,采用表面级方法,其中词频和词位置属性用于技术文章的单文档文本摘要 [8,9]。 Lehn 的算法适用于词袋模型。它统计文档中的单词数,并根据主题单词压缩文本文档。文档的主题词显示了该词在文档中的重要性。它的重要性可以根据单词的频率或单词在文档中重复的次数来计算。
在 20 世纪 60 年代,其他属性(例如提示词和提示短语)与 Edmonson 在单文档文本摘要的表面级方法上使用的先前属性相结合 [10]。 1995 年,使用机器学习技术开发了可训练的文档摘要器 [11]。在这种类型的技术中,摘要的多个样本作为摘要系统的输入给出;它找到句子与其标题或文档之间的关系,并决定是否包含摘要句子。 1997年,Barzilay和Elhadad提出了词汇链模型,提供句子的语义结构。词汇链是使用一些包含名词及其各种关联的知识库构建的[12]。 NER 和信息提取技术被应用于新闻文章,其中问题中同时出现的单词数量被提取[13]。剪切和粘贴系统是利用统计技术开发的;他们保持文本的连贯结构,并创建一个从头到尾在结构和含义上逻辑流畅的文本[7]。 Swesum (Herculuslianis) 开发了特定领域的统计摘要器,用于总结新闻文章 [14]。 Conroy J.M. 和 O’Leary, D.P.开发了单级词汇摘要器,它总结文章并生成词汇相关的句子 [2]。还开发了基于图形的摘要器[15]。基于 LSA 的摘要器被开发出来,它提取语义相关的句子 [16]。 Abdullah Fattah Omar 还使用相同的方法 (LSA) 进行文本摘要,以生成连贯的摘要 [17]。
研究人员开发了基于联合提取和句法压缩的单文档摘要模型。我们的模型从文档中选择句子,根据选区解析识别可能的压缩,并使用神经模型对这些压缩进行评分以生成最终摘要 [18]。谢尔盖·戈尔巴乔夫还开发了一种经过模糊逻辑修改的神经模型,以产生连贯的摘要[19]。 Siddhant Upasani 开发了基于 TextRank(文本排名算法)的摘要器,该算法是 Google 搜索引擎中用于对网页进行排名的页面排名算法的实现 [20]。基于tf-idf特征开发了一个针对印尼学生英语学习的英语新闻摘要器。根据相似度关键词选择最上面的句子,由于文档长度的限制,只提取相关的最上面的句子。对于总结评估,精度、召回率和 f 测量分数用于总结强度 [21]。迈克尔·乔治(Michael George)开发了基于加粗句子分数的自动文本摘要;它获取具有较高值和密度以及较短长度的句子。该目标增加了句子价值并减少了不必要的单词和长句子,这使得顶部句子列表具有更多价值。随后,该句子得分等于句子术语的出现总数除以句子单词[22]。
开发了一种独立于领域、基于统计的方法,用于单文档提取摘要。使用了二元组技术,它在文本中重复多次,是描述文本内容的好术语,称为最大频繁句子。我们还表明,重复出现的二元词项的频率给出了良好的结果[23]。 Rasim 利用整数线性规划问题技术提出了最大覆盖率和最小冗余文本摘要模型。该模型的优点之一是它可以直接发现给定文档中的关键句子并覆盖原始文档的主要内容[24]。该模型还保证摘要不能是传达相同内容的多个句子信息。所提出的模型非常通用,也可用于在 DUC2005 和 DUC2007 数据集上实现的单文档和多文档摘要 [25]。自动文本摘要的多重替代句子压缩由 Nitin Madnani、David Zajic、Bonnie Dorr、Necip Fazil Ayan 和 Jimmy Lin 提出,是一种摘要模型,其中解析和修剪方法包括过滤、压缩和使用候选选择阶段[26]。过滤过程包含高度相关性和中心性的句子,选择这些句子进行进一步处理。 HMM 生成源句子最可能的压缩。修剪器使用语言驱动的修剪规则从解析树中删除成分[27]。两种方法都将特定于压缩的特征值与可用于候选选择的候选压缩相关联。 Trimmer 通过将每个 Trimmer 规则应用程序的输出视为不同的压缩来生成多个压缩 [28]。 Trimmer 规则的输出是一个解析树和一个关联的表面字符串 [29]。 Alaidine Ben Ayed、Ismaïl Biskri 和 Jean-Guy Meunier 建议对自动生成的文本摘要进行基于向量空间建模的评估。他们提出了 VSMbM,这是一种用于自动生成文本摘要评估的新指标。 VSMbM 基于向量空间建模。它提供了关于生成的摘要中保留率和保真度达到何种程度的见解[30]。所提出的指标的三个变体,即 PCA–VSMbM、ISOMAP–VSMbM 和 tSNE–VSMbM 进行了测试,并与面向回忆的 Gisting 评估 (ROUGE) 进行比较,ROUGE 是用于评估自动生成的摘要的标准指标 [31]。
三.本文方法
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
4.6 细粒度分析
五 总结
表 1 显示了不同总结器与所提出模型的比较。它表明,在从 100% 收缩到 10% 的过程中,基于等级、特征和概念的不同总结器会失去其属性。这就是为什么它们的保留率或信息增益变得更少,而我们提出的模型试图通过尝试维护文档中显示有意义信息的域词来以最小的损失保留最大的信息增益。图6显示了所提出的模型与LDA模型的比较; LDA模型从文档中根据概念提取主题,我们的模型也从同一文档中提取主题,这显示了其主题覆盖率与LDA模型的主题覆盖率几乎相同。在所提出的摘要器中,与原始文档相比,由于其与主题或标题的语义不同而丢失了一些信息,这些信息被视为异常值。为了进一步获得更大或更接近准确的结果,可以尝试统计方法。方差分析技术可用于比较原始数据、总结文档并检查方差。如果其方差较高,则可以调整模型以获得更好的精度和最小的方差。
思考
这篇关于NLP论文阅读记录 - 2022 WOS | 语义提取文本摘要的新方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




