本文主要是介绍Affect-LM: A Neural Language Model for Customizable Affective Text Generation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原先的LSTM求下一个单词的概率公式:
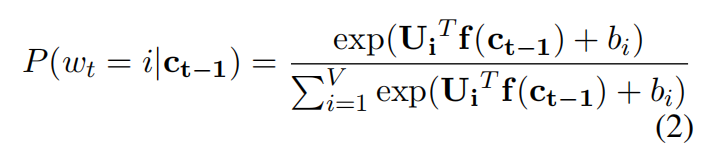
其中,f(.)是LSTM的输出结果。现在更改(加入情感能量项)如下:

β表示情感强度,可以从0(中性,基线模型)到β=∞(生成的句子只由情感色彩的单词组成,没有语法结构)
e t − 1 e_{t-1} et−1表示从上文学到的词向量,g( e t − 1 e_{t-1} et−1)表示属于哪种情感,例[1,0,1,1,0]
V i T V{^T_i} ViT表示第i个词和g( e t − 1 e_{t-1} et−1)的相似度,g( e t − 1 e_{t-1} et−1) * V i T V{^T_i} ViT如果大说明第i个词跟g( e t − 1 e_{t-1} et−1)情感一致,故p( W t = i ∣ C t − 1 , e t − 1 W_t=i|C_{t-1},e_{t-1} Wt=i∣Ct−1,et−1)的值大。
e t − 1 e_{t-1} et−1怎么学到的?
LIWC而来
which is obtained by binary thresholding of the features extracted from LIWC
The affect category et 1 is
processed by a multi-layer perceptron with a single hidden layer of 100 neurons and sigmoid activation function to yield g(et 1).
g( e t − 1 e_{t-1} et−1)函数是什么?
感知机训练而来
g(.) is the output of a network operating on e t − 1 e_{t-1} et−1。
V i T V{^T_i} ViT怎么得到?
训练而来
V i T V{^T_i} ViT is an embedding learnt by the model for the i-th word in the vocabulary
矩阵Vi的每一行是第i个词在词汇中的情感上有意义的词向量
Vi是由模型学习的词汇中的第i个词的词向量,预期会对有区别的表达每个单词的情感信息。
Affect-LM学习权重矩阵V,其捕获预测词wt与影响类别et-1之间的相关性。
模型(自己画的):

代码参考:https://github.com/gupett/Re-implementation-of-Affect-LM
这篇关于Affect-LM: A Neural Language Model for Customizable Affective Text Generation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






