本文主要是介绍Personalizing EEG-based Affective Models with Transfer Learning 阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
提出了个体到个体的两种方法
1)源域和目标域共享结构(TCA、KPCA)
2)训练多个个体的分类器,对分类器参数进行迁移。
基本方法:组合所有个体可用的数据作为训练数据,训练一个基类分类器线性SVM。
数据特征维度:62*310(导联*特征维度)
TCA和KPCA:源域:14个个体中随机选取5000个样本,核选用线性核,分类器选用one vs one 策略。目标域剩余的一个人
Transductive Parameter Transfer(TPT)

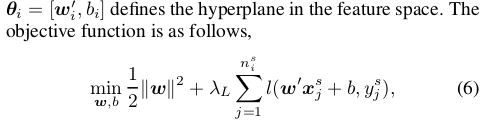
density estimation kernel:相似性度量
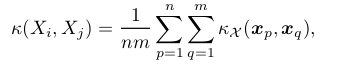

这篇关于Personalizing EEG-based Affective Models with Transfer Learning 阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









