本文主要是介绍系分笔记数据库反规范化、SQL语句和大数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、概要
- 2、反规范化
- 3、大数据
- 4、SQL语句
- 5、总结
1、概要
数据库设计是考试重点,常考和必考内容,本篇主要记录了知识点:反规范化、SQL语句及大数据。
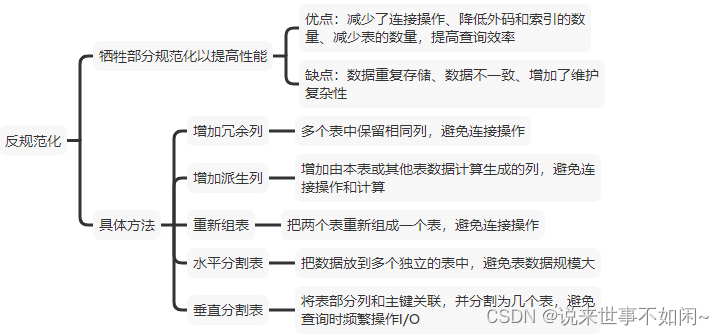
2、反规范化
数据库遵循范式的设计,使得多表查询和连接表查询较多的时候性能不太好,反规范化的思想就是牺牲部分规范化以提高性能,具体方法包括增加冗余列、增加派生列、水平分割、垂直分割和重新组表。
3、大数据
大数据的知识点,其特点:大量化、多样化、快速、价值密度低,数量级PB级或以上,一般使用集成的平台处理大数据(也就是大数据处理系统)。

4、SQL语句
数据库SQL语句,常考的知识点,基本是关键字的运用,如增删改查等。

5、总结
本篇知识点笔记中,选择题型常考内容有大数据的特点和SQL语句。
这篇关于系分笔记数据库反规范化、SQL语句和大数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






