本文主要是介绍利用AVX、OpenMP进行矩阵乘加速,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
初学优化,学疏才浅,还请斧正
矩阵乘:(必须满足A矩阵的列数等于B矩阵的行数)
运算方法:A矩阵中每一行中的数字乘以B矩阵中对应的的每一列的数字,把结果相加起来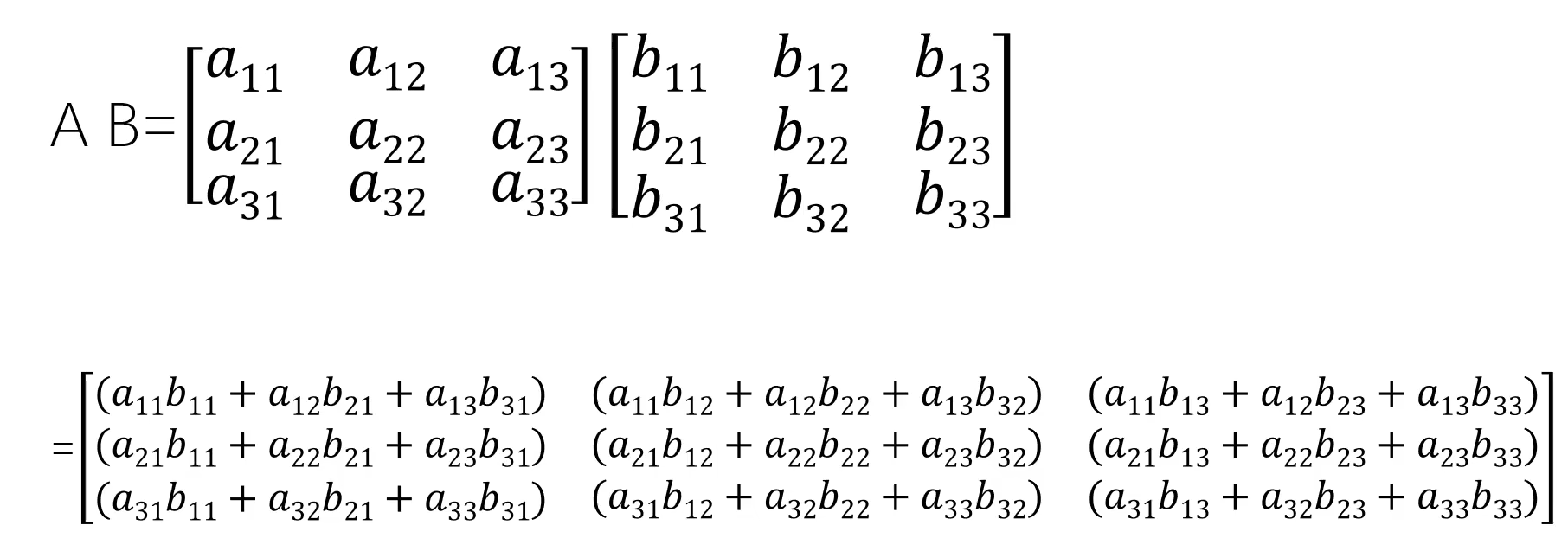 由上述原理可将处理过程描绘为C语言代码:
由上述原理可将处理过程描绘为C语言代码:
#define N 9
float A[N][N],B[N][N],C[N][N];//定义N*N的矩阵A,B,Cfor(int i=0;i<N;i++)for(int j=0;j<N;j++){A[i][j]=(float)rand()/10000;//随机数初始化A、B矩阵B[i][j]=(float)rand()/10000;C[i][j]=0;//初始化C矩阵}
对A、B矩阵进行计算,结果放入C矩阵中:
for(int i=0;i<N;i++)for(int j=0;j<N;j++)for(int k=0;k<N;k++)C[i][j] += A[i][k]*B[k][j];
这样的代码最后计算结果是正确的,但是数据量较大的时候,运算速度就会非常缓慢。
在存储访问结构中,行优先存储访问速度是优于列优先的,但B矩阵的访问是以列优先读取的,所以可以考虑将B矩阵存储改为行优先存储。
B[j][i] = (float)rand()/1000;
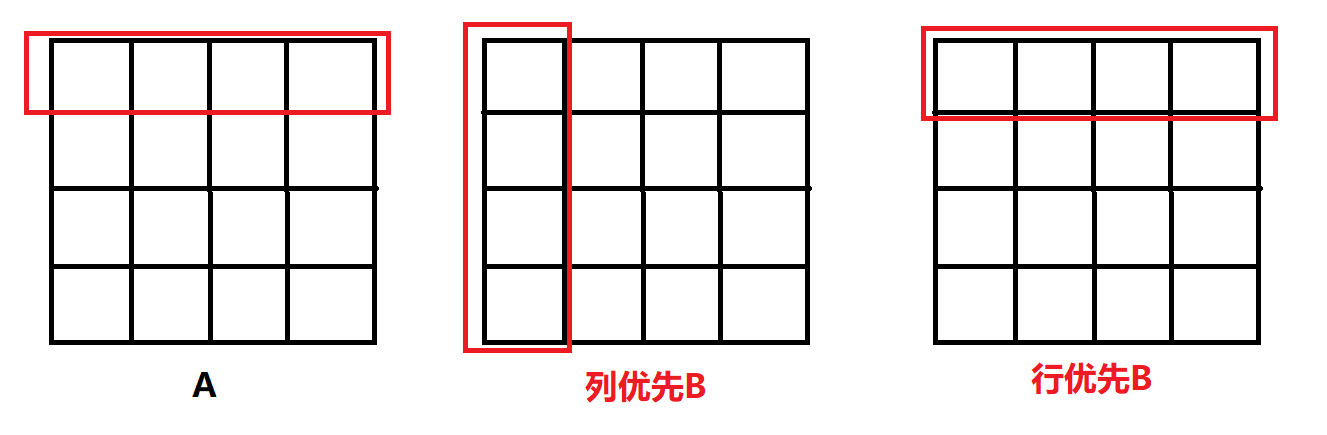
这样计算就是A的每一行与其B的对应行相乘并相加。
处理代码也要发生相应的改变
for(int i=0;i<N;i++)for(int j=0;j<N;j++)for(int k=0;k<N;k++)C[i][j] += A[i][k]*B[j][k]; //改变在这里
这里三个for循环,时间复杂度为O(n^3)
这里我们先用AVX对内部进行处理
int k=0, temp = N%8;for(;k<N-temp;k+=8){ v0 = _mm256_loadu_ps(&a[i][k]);v1 = _mm256_loadu_ps(&b[j][k]);v2 = _mm256_mul_ps(v0,v1);//同时对8个浮点数进行计算c[i][j]+=(v2[0]+v2[1]+v2[2]+v2[3]+v2[4]+v2[5]+v2[6]+v2[7]);//规约}for(;k<N;k++)c[i][j]+=a[i][k]*b[j][k];//对剩余的部分数据进行处理
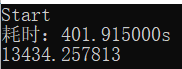
处理前(N为5000):
处理后:
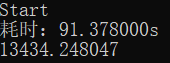
速度得到了很大提升,但是可以看到,我们数据结果出现了误差,这是由于数据量比较大,我们只用的是float类型,造成了精度问题(可以用double类型或者用其他高精度方法解决)。
此时速度还是不够理想,现在就使用OpenMP进行优化了,
三重for循环之间并不存在依赖,可以直接用#pragma omp parallel for进行并行操作
#pragma omp parallel for num_threads(16)for(int i=0;i<N;i++){__m256 v0,v1,v2;for(int j=0;j<N;j++){int k=0,temp = N%8;for(;k<N-temp;k+=8){ v0 = _mm256_loadu_ps(&a[i][k]);v1 = _mm256_loadu_ps(&b[j][k]);v2 = _mm256_mul_ps(v0,v1);c[i][j]+=(v2[0]+v2[1]+v2[2]+v2[3]+v2[4]+v2[5]+v2[6]+v2[7]);}for(;k<N;k++){c[i][j]+=a[i][k]*b[j][k];}
处理结果:
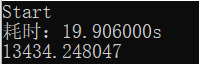
最后开了-O3,最终优化结果:
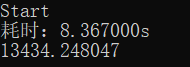
附赠MPI+OpenMP+AVX,效果不是很好
#include <immintrin.h>
#include <stdio.h>
#include <time.h>
#include <mpi.h>
#include <algorithm>
#include <cstring>
#define N 5000
using namespace std;
float a[N][N],b[N][N],c[N][N],buffer1[N],buffer2[N];
int main()
{int rank,numprocs;MPI_Status status;MPI_Init(NULL,NULL);MPI_Comm_size(MPI_COMM_WORLD,&numprocs);MPI_Comm_rank(MPI_COMM_WORLD,&rank);if(rank==0){for(int i=0;i<N;i++)for(int j=0;j<N;j++){a[i][j]=(float)rand()/1e6;b[j][i]=(float)rand()/1e6;c[i][j]=0;}double st = MPI_Wtime();
// for(int i=1;i<numprocs;i++)
// MPI_Send(b,sizeof(b)/sizeof(float),MPI_FLOAT,i,0,MPI_COMM_WORLD);MPI_Bcast(b,sizeof(b)/sizeof(float),MPI_FLOAT,0,MPI_COMM_WORLD);int num_flag=0;while(num_flag<N){for(int i=0;i < min(N-num_flag,numprocs-1);i++){memcpy(buffer1,a[num_flag],sizeof(a[num_flag]));MPI_Send(buffer1,sizeof(buffer1)/sizeof(float),MPI_FLOAT,i+1,num_flag,MPI_COMM_WORLD);num_flag++;}}for(int i=0;i<N;i++){MPI_Recv(buffer2,sizeof(buffer2)/sizeof(float),MPI_FLOAT,MPI_ANY_SOURCE,MPI_ANY_TAG,MPI_COMM_WORLD,&status);int tag = status.MPI_TAG;memcpy(c[tag],buffer2,sizeof(buffer2));}double ed = MPI_Wtime();for(int i=1;i<numprocs;i++){MPI_Send(buffer1,sizeof(buffer1)/sizeof(float),MPI_FLOAT,i,N+1,MPI_COMM_WORLD);}printf("allright!耗时:%lfs\n",ed-st);printf("c[0][0] = %f\n",c[0][0]);}else{printf("%d is running\n",rank);
// MPI_Recv(b,sizeof(b)/sizeof(float),MPI_FLOAT,0,0,MPI_COMM_WORLD,&status);MPI_Bcast(b,sizeof(b)/sizeof(float),MPI_FLOAT,0,MPI_COMM_WORLD);while(1){MPI_Recv(buffer1,sizeof(buffer1)/sizeof(float),MPI_FLOAT,0,MPI_ANY_TAG,MPI_COMM_WORLD,&status);if(status.MPI_TAG == N+1) break;#pragma omp parallel forfor(int i = 0; i < N;i++){ __m256 v0,v1,v2;int temp = N%8,j=0;for(;j < N-temp;j+=8){v0 = _mm256_loadu_ps(&buffer1[j]);v1 = _mm256_loadu_ps(&b[i][j]);v2 = _mm256_mul_ps(v0,v1);buffer2[i]+=(v2[0]+v2[1]+v2[2]+v2[3]+v2[4]+v2[5]+v2[6]+v2[7]);
// buffer2[i] += buffer1[j] * b[i][j];}for(;j<N;j++){buffer2[i]+=buffer1[j]*b[i][j];}}MPI_Send(buffer2,sizeof(buffer2)/sizeof(float),MPI_FLOAT,0,status.MPI_TAG,MPI_COMM_WORLD);}}MPI_Finalize();return 0;
}
这篇关于利用AVX、OpenMP进行矩阵乘加速的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





