avx专题

Tensorflow针对CPU的编译优化加速-解决Not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
本文介绍Tensorlfow 针对 CPU SSE4.1 SSE4.2 AVX AVX2 FMA 的编译优化,以提升Tensorflow在CPU上的计算速度,实测可以提升两倍以上的速度。 1、问题 在用 pip 安装tensorflow的CPU版本后,在运行的时候通常会出现如下提示:Your CPU supports instructions that this TensorFlow bina
tensorflow | Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX
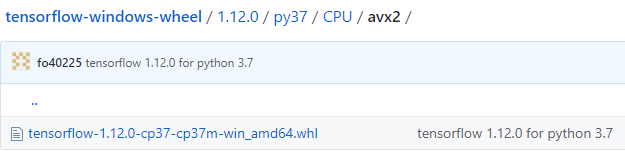
报错: Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2 解决: 1.重新安装python3.7.2 2.打开 https://github.com/fo40225/tensorflow-windows-wheel 在里面找到对应的.whl文件 报错提示

【整理】SIMD、MMX、SSE、AVX、3D Now!、neon——指令集大全
http://blog.csdn.net/conowen/article/details/7255920 SIMD SIMD单指令流多数据流(SingleInstruction Multiple Data,SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是

一个简单求和函数的C-》SSE-》AVX的实现过程
这篇文章写的非常好,特别是文中的链接也要仔细浏览。 ====================================== (转)Intrinsic—使用SSE、AVX指令集处理单精度浮点数组求和(支持vc、gcc,兼容Win、Linux、Mac) (2013-01-14 10:45:16) 转载▼ 标签: 杂谈 分类: 汇编
利用AVX、OpenMP进行矩阵乘加速
初学优化,学疏才浅,还请斧正 矩阵乘:(必须满足A矩阵的列数等于B矩阵的行数) 运算方法:A矩阵中每一行中的数字乘以B矩阵中对应的的每一列的数字,把结果相加起来由上述原理可将处理过程描绘为C语言代码: #define N 9float A[N][N],B[N][N],C[N][N];//定义N*N的矩阵A,B,Cfor(int i=0;i<N;i++)for(int j=0;j<N;
【整理】SIMD、MMX、SSE、AVX、3D Now!、neon
原文: http://blog.csdn.net/conowen/article/details/7255920 另外还有一个C++的参考:https://software.intel.com/zh-cn/articles/using-avx-without-writing-avx-code 解释得蛮清楚的。 SIMD SIMD单指令流多数据流(SingleInstruction
![[ubuntu]查看自己电脑硬件是否支持avx指令集](/front/images/it_default.gif)
[ubuntu]查看自己电脑硬件是否支持avx指令集
有时候paddlepaddle或者其他深度学习框架明显需要avx支持才能正常使用,因此知道电脑硬件是否支持avx很重要,那么怎么查看自己电脑是否支持avx指令集呢,很简单输入下面命令即可 grep -o -e sse4_2 -e avx -e sse4a -e avx2 /proc/cpuinfo
![[ubuntu]查看自己电脑硬件是否支持avx指令集](/front/images/it_default2.jpg)
[ubuntu]查看自己电脑硬件是否支持avx指令集
有时候paddlepaddle或者其他深度学习框架明显需要avx支持才能正常使用,因此知道电脑硬件是否支持avx很重要,那么怎么查看自己电脑是否支持avx指令集呢,很简单输入下面命令即可 grep -o -e sse4_2 -e avx -e sse4a -e avx2 /proc/cpuinfo
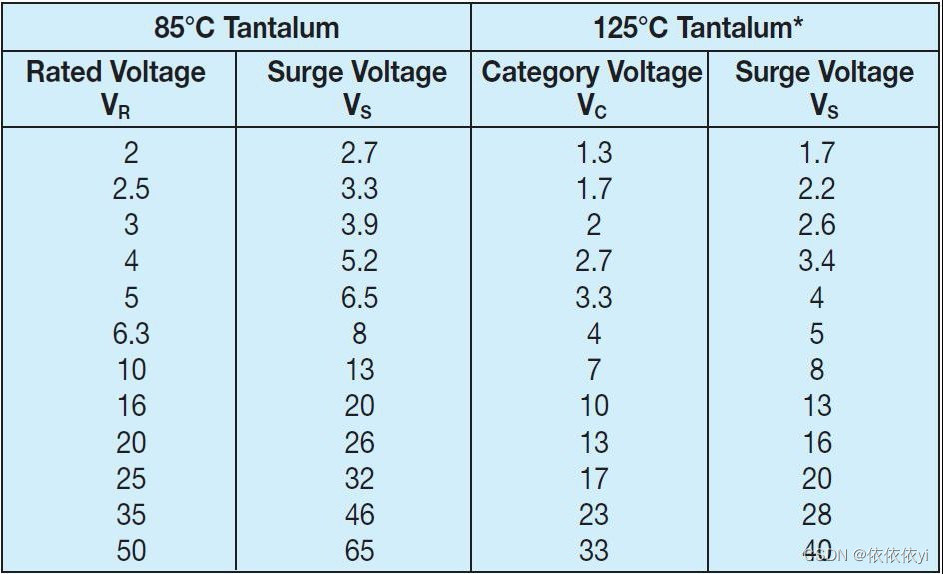
AVX 贴片钽电容的频率特性分析
在介绍 AVX 钽电容的温度特性曲线前,我们必需对以下两个基本概念有所认识: 额定容量(CR) 这是额定 电容。对于钽OxICap?电容器的电容测量是在25° C 时等效串联电路使用测量电桥提供一个0.5V RMS120Hz 的正弦信号,谐波与2.2Vd.c. 电容公差 这是实际值的允许偏差电容额定值。 AVX 钽电容的温度特征。 钽电容器的电容随温度变化而发生变化。这种变化本身就是一个小的程度上
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX 警告说你的tensorflow不能使用SSE4.1 SSE4.2 AVX AVX2 FMA这些CPU矢量运算的指令码进行编译。 为了提升CPU计算速度的。若你有支持cuda的GPU,则可以忽略这个问题,因为安装SSE4

SIMD 编程的优势与SIMD指令:SSE/AVX 与编程demo
资源:https://download.csdn.net/download/Rong_Toa/18745608 《Benefits of SIMD Programming | SIMD的优势》 目录 SIMD指令编程demo 正常代码 一次循环计算4次 使用SSE指令 使用AVX指令 性能对比 更多参考 SIMD指令编程demo 本文更新于 2018.10.24 本

MMX, SSE(XMM,MXCSR,FXSAVE),SSE2,SSE3,AVX,AVX-512
摘自《Intel® 64 and IA-32 Architectures Software Developer’s Manual Combined Volumes1, 2A, 2B, 2C, 2D, 3A, 3B, 3C, 3D and 4》 《Benefits of SIMD Programming | SIMD的优势》 资源:https://download.csdn.net/downlo