本文主要是介绍谓词-量词、主析取、主和取范式、前束范式、推理证明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这部分内容,主要需要掌握谓词推理,而前提是掌握将自然语言符号化为谓词、用量词来限定辖域,量词的消去、剩下就是推理过程。还需要掌握的是主析取、主和取范式和前束范式。
存在量词∃:至少有一个
全称量词∀:全都是,所有
前束范式:通过逻辑计算,将量词放到整个式子的最前面
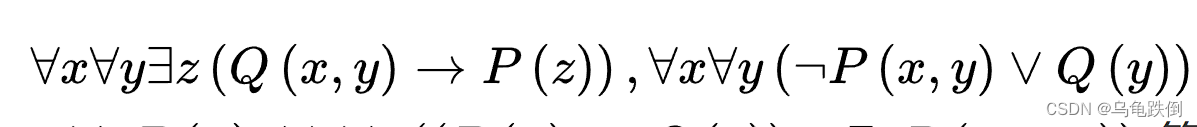
注意:主析取范式括号内的叫做小项,当对其编码时,真值为1;
主合取范式括号内的叫做大项,当对其编码时,真值为0
主析取范式:将式子化为如下模式:
(__∧__ )v(__∧__ )v(__∧__ )
主和取范式:将式子化为如下模式:
(__v__ )∧(__v__ )∧(__v__ )
对于推理证明来说,照着逻辑推就是,但是注意如果是全称量词∀,那么就可以取任何值,但是要注意存在量词∃就不能去所有值而是某个特例。
这篇关于谓词-量词、主析取、主和取范式、前束范式、推理证明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!