本文主要是介绍利用历元间数据计算伪距变化率验证多普勒数值正确与否,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
因为在做公司项目的时候,遇到一些接收机吐出来的多普勒数据存在异常的情况,后面咨询各个大佬需求验证方法,大佬耐心回了句“利用历元间伪距数据计算伪距变化率,然后将伪距变化率转成多普勒比对即可”,听到大佬的回答,我是一脸懵逼的,一通百度找到具体的换算方法,故而博文记录,用于备忘。
注意:
这是一个纯GNSS小白的博文记录,大佬出门左转哈
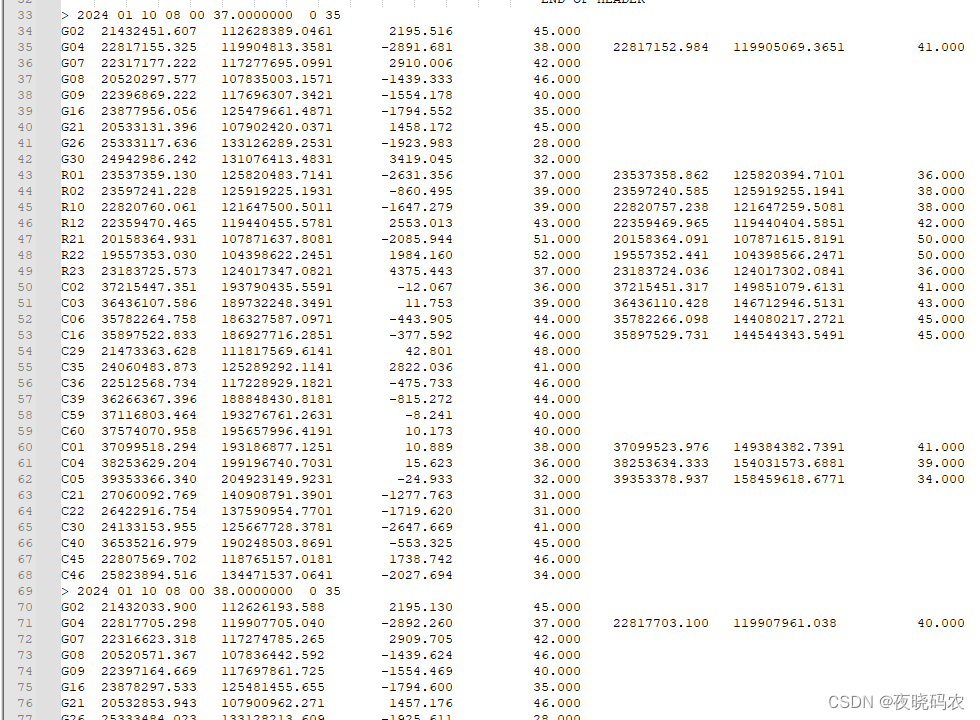
数据
计算方法
计算公式(非科学严谨版本)
(当前历元伪距 - 上一历元伪距)/ 历元时间间隔 * 频点频率 / 光速 * -1(这个-1,在参考链接文档有说明) ≈ RINEX文件中的多普勒观测值
以G02举例(图里前四列是L1频点的数据)
(21432033.9 - 21432451.607) / 1.0 * 1575420000 / 299792458 * -1 = 2195.0651
该方法加上阈值可以用来验证多普勒数据是否存在异常。反过来,也可以利用多普勒观测值去验证伪距数据是否有错。具体公式如下:
当前历元伪距 ≈ 上一历元伪距 + RINEX文件中的多普勒观测值 * -1 * 光速 / 频点频率 * 历元时间间隔
链接
伪距率计算公式
北斗接收机伪距与伪距率的计算及其误差补偿
这篇关于利用历元间数据计算伪距变化率验证多普勒数值正确与否的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







