本文主要是介绍【大厂算法面试冲刺班】day0:数据范围反推时间复杂度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
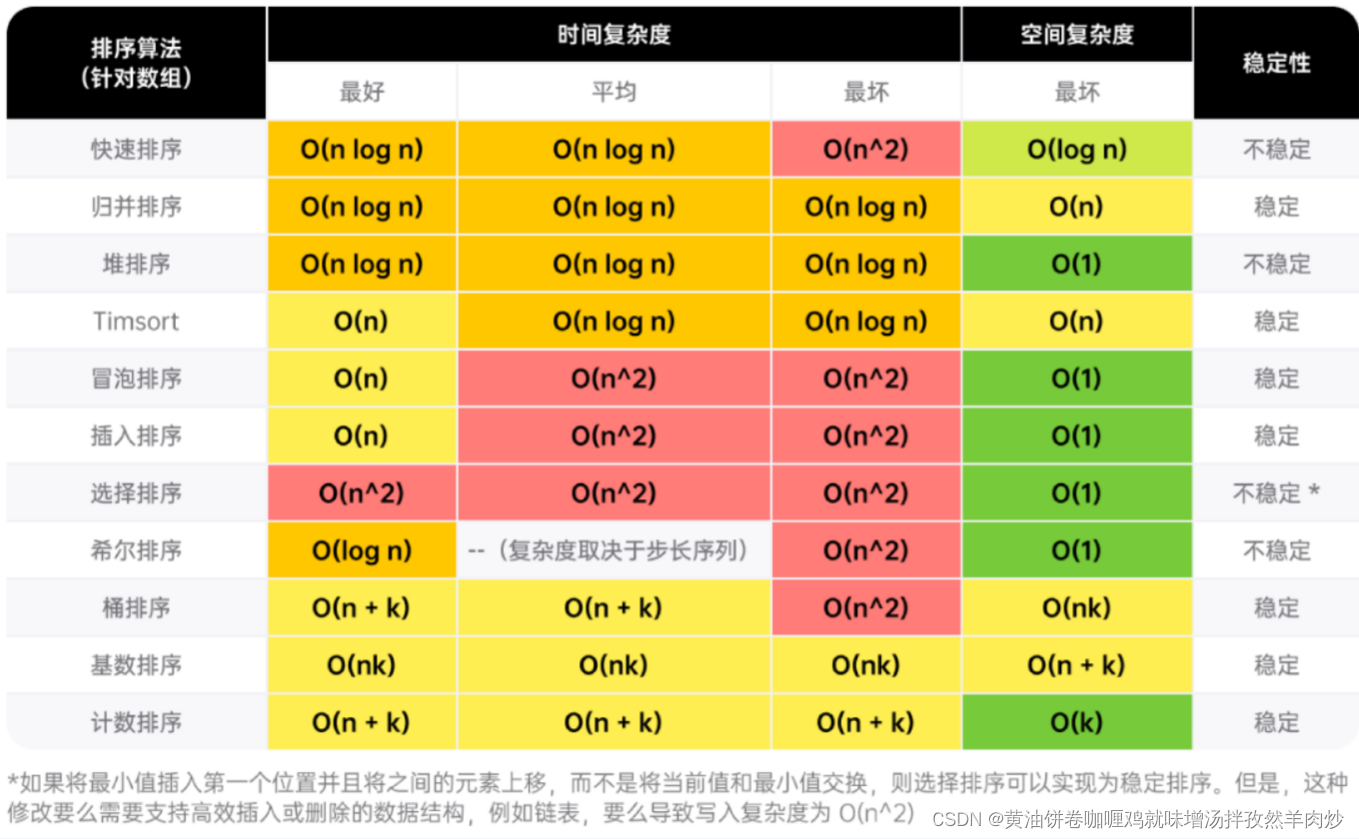
常见算法的时间复杂度
规定n是数组的长度/树或图的节点数
二分查找:O(logn)
双指针/滑动窗口:O(n)
DFS/BFS:O(n)
构建前缀和:O(n)
查找前缀和:O(1)
一维动态规划:O(n)
二维动态规划:O(n^2)
回溯:O(2^n)/O(n!)
下面重点来辣
数据范围反推时间复杂度
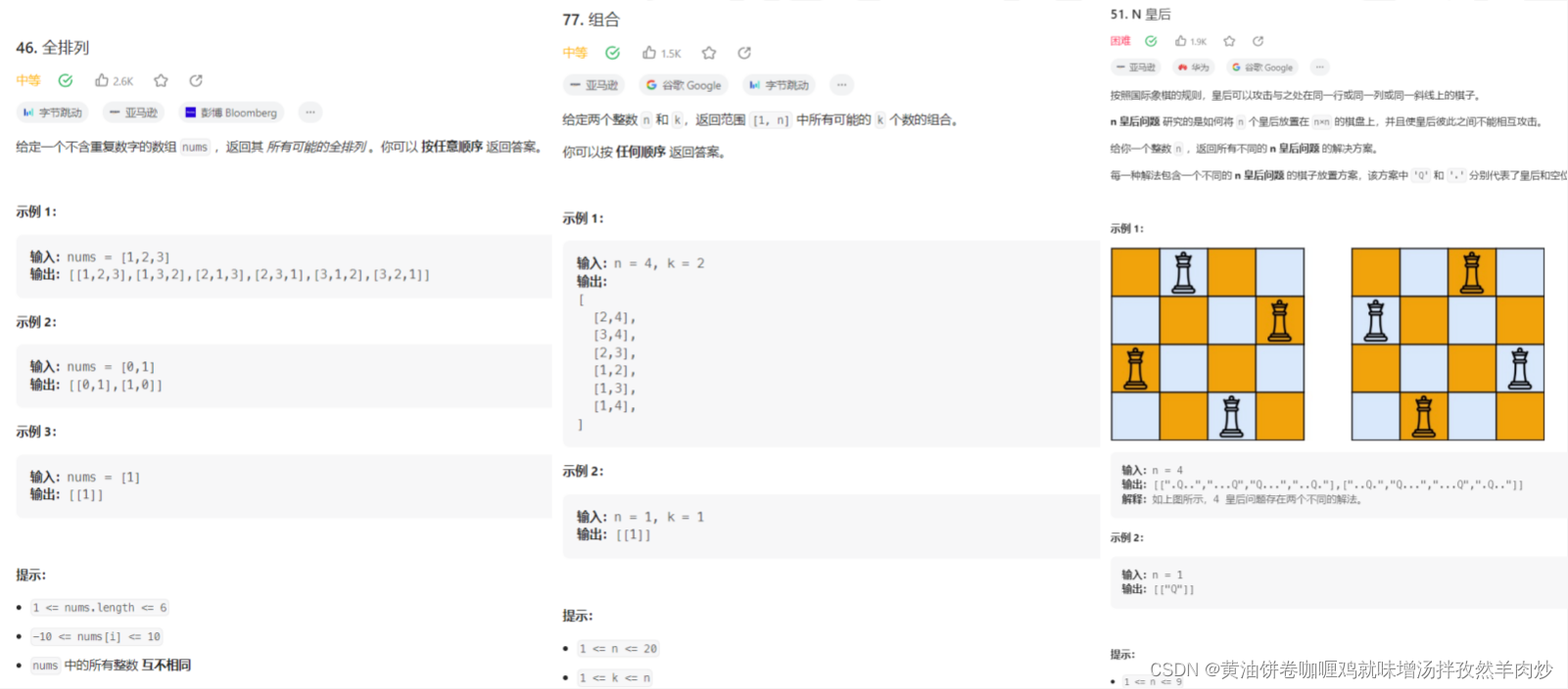
数据范围:n~100
O(n!)/O(2^n)的时间复杂度
应该考虑回溯或任何蛮力式的递归算法
如:全排列、组合、N皇后
数据范围:n~1,000
O(n^2)的时间复杂度
通常涉及双重循环,内层循环可能涉及双指针、dp等等
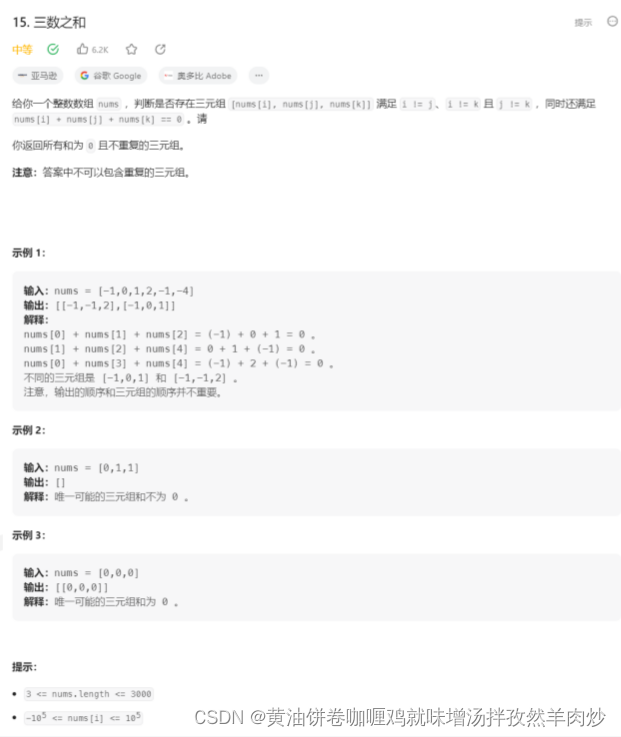
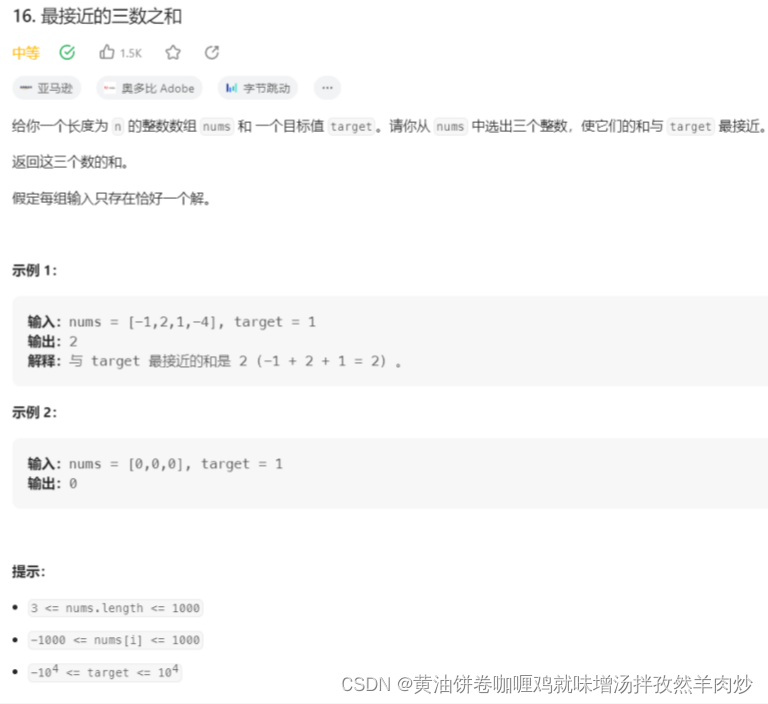
如:三数之和、最接近的三数之和
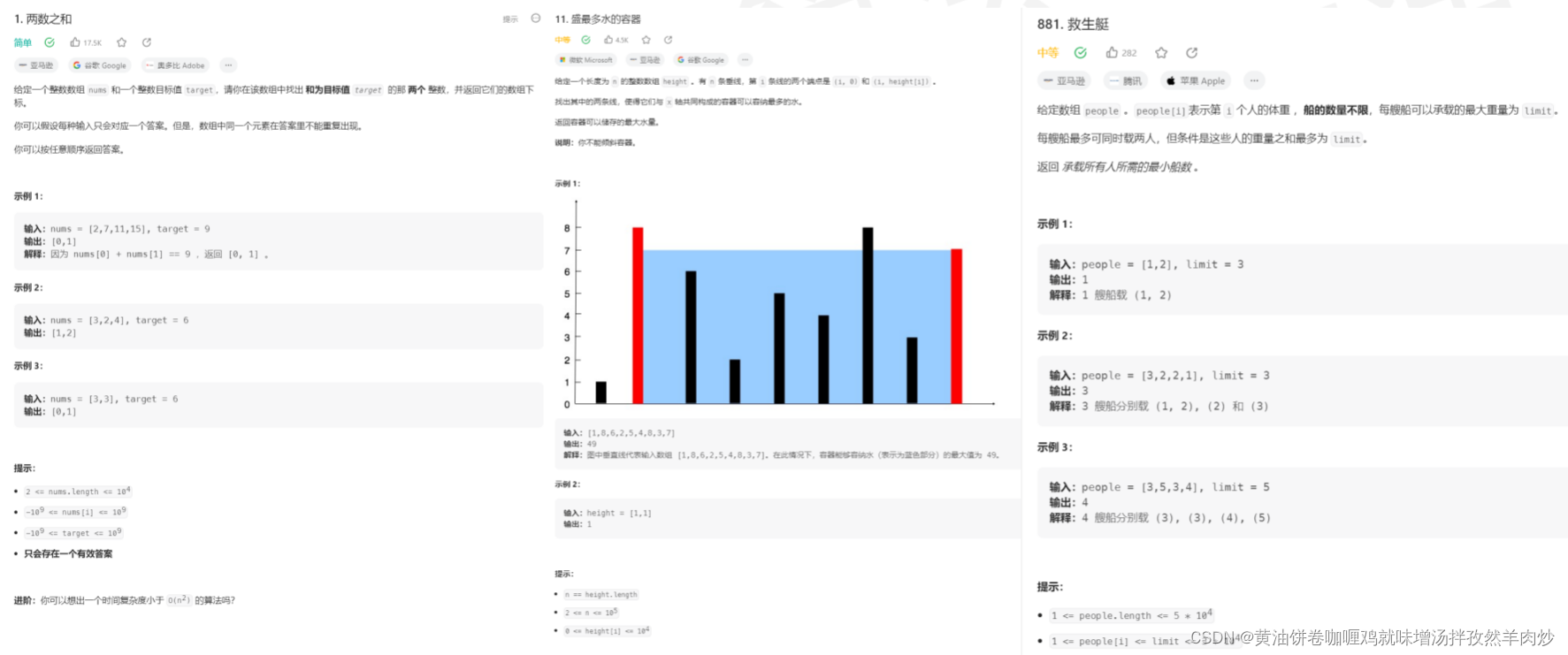
数据范围:n~100,000
O(logn)/O(n)/O(nlogn)的时间复杂度
双重循环无法通过,但可以接受直接遍历,很多贪心/双指针的问题
如:两数之和、盛最多水的容器、救生艇
数据范围:n~1,000,000
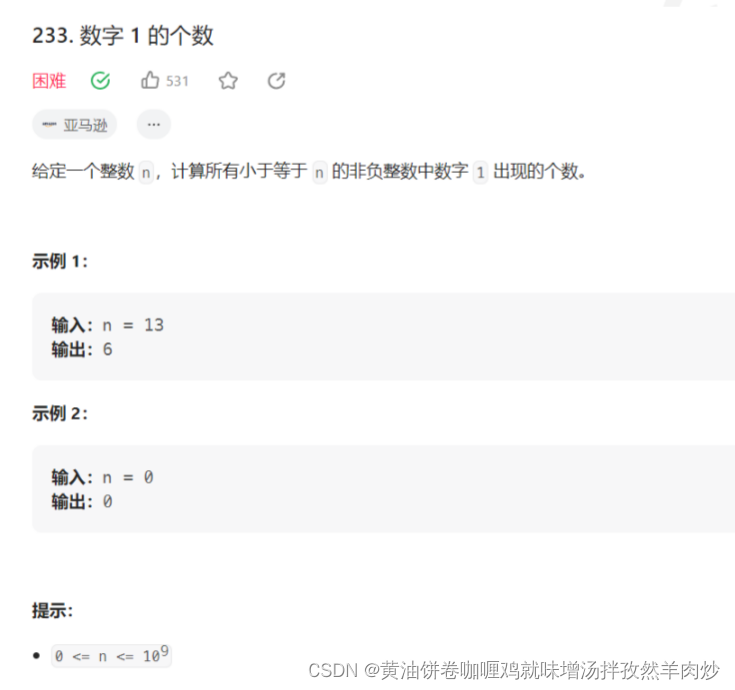
O(1)/O(logn)的时间复杂度
涉及二分查找或数学解法
如:数字1的个数、猜数字大小

程序运行时间和什么有关
数据量大小
算法的好坏
这篇关于【大厂算法面试冲刺班】day0:数据范围反推时间复杂度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



