本文主要是介绍R语言JAGS贝叶斯回归模型分析博士生延期毕业完成论文时间,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被客户要求撰写关于贝叶斯回归的研究报告,包括一些图形和统计输出。
本文为读者提供了如何进行贝叶斯回归的基本教程。包括完成导入数据文件、探索汇总统计和回归分析。
视频:线性回归中的贝叶斯推断与R语言预测工人工资数据案例
贝叶斯推断线性回归与R语言预测工人工资数据
,时长09:58
在本文中,我们首先使用软件的默认先验设置。在第二步中,我们将应用用户指定的先验,对自己的数据使用贝叶斯。
准备工作
本教程要求:
- 已安装的JAGS
- 安装R软件。
- 假设检验的基本知识
- 相关性和回归的基本知识
- 贝叶斯推理的基本知识
- R语言编码的基本知识
数据实例
我们在这个练习中使用的数据是基于一项关于预测博士生完成论文时间的研究(Van de Schoot, Yerkes, Mouw and Sonneveld 2013)。研究人员询问了博士生完成他们的博士论文需要多长时间(n=333)。结果显示,博士学位获得者平均花了59.8个月(5年4个月)来完成他们的博士学位。变量B3衡量计划和实际项目时间之间的差异,以月为单位(平均=9.97,最小=-31,最大=91,sd=14.43)。
对于目前的工作,我们感兴趣的问题是,博士学位获得者的年龄(M=31.7,SD=6.86)是否与他们项目的延期有关。
预计完成时间和年龄之间的关系是非线性的。这可能是由于在人生的某个阶段(即三十多岁),家庭生活比你在二十多岁时或年长时占用了你更多的时间。
因此,在我们的模型中,差距(B3)是因变量,年龄和年龄平方是预测因素。
问题:请写出零假设和备择假设。 写下代表这个问题的无效假设和备选假设。你认为哪个假设更有可能?
回答:
H0:年龄与博士项目的延期无关。
H1: 年龄与博士项目的延期有关。
H0:age2与博士项目的延期无关。
H1:age2与博士项目的延期有关。
准备--导入和探索数据
数据是一个.csv文件,但你可以使用以下语法直接将其加载到R中。
一旦你加载了你的数据,建议你检查一下你的数据导入是否顺利。因此,首先看看你的数据的汇总统计。你可以使用describe()函数。
问题: 你所有的数据都被正确地载入了吗?也就是说,所有的数据点都有实质性的意义吗?
回答:
describe(data)
描述性统计有意义。
差异。平均值(9.97),SE(0.79)。
年龄。平均值(31.68),SE(0.38)。
age2。平均值(1050.22),SE(35.97)。
绘图
在继续分析数据之前,我们还可以绘制期望的关系。
plot(aes(x = age,y = diff))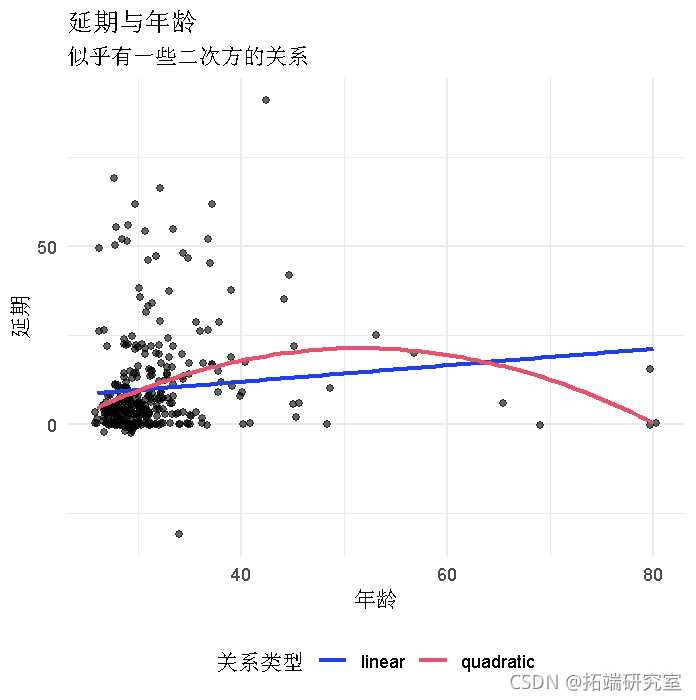
回归
在这个练习中,你将研究博士生的年龄和age2对他们的项目时间延期的影响,这作为结果变量使用回归分析。
如你所知,贝叶斯推理包括将先验分布与从数据中获得的似然性相结合。指定先验分布是贝叶斯推断中最关键的一点,应该受到高度重视(例如Van de Schoot等人,2017)。在本教程中,我们将首先依赖默认的先验设置。
要用运行多元回归,首先要指定模型,然后拟合模型,最后获得总结。模型的指定方法如下。
- 我们想要预测的因变量。
- "~",我们用它来表示我们现在给其他感兴趣的变量。(相当于回归方程的"=")。
- 用求和符号'+'分隔的不同自变量。
- 最后,我们插入因变量有一个方差,有一个截距。
下面的代码是如何指定回归模型的。
# 1) 指定模型'#回归模型diff ~ age + age2#显示因变量有方差diff ~~ diff#有一个截距diff ~~ 1'然后,我们需要使用以下代码来拟合模型。我们指定target = "jags "来使用Jags而不是Stan编译器。
fitbayes(model, data, target = "jags", test = "none", seed = c(12,34,56) )# test="none "的输入停止了一些后验的计算,我们现在不需要,加快了计算过程。
# 种子命令只是为了保证在多次运行采样器时有相同的准确结果。你不需要设置这个。当使用Jags时,你需要设置尽可能多的种子链(默认)。
现在我们用summary(fit.bayes)来看看总结。
显示输出

频率主义模型与贝叶斯分析模型所提供的结果确实不同。
贝叶斯统计推断和频率主义统计方法之间的关键区别在于估计的未知参数的性质。在频率主义框架中,一个感兴趣的参数被假定为未知的,但却是固定的。也就是说,假设在人口中只有一个真实的人口参数,例如,一个真实的平均值或一个真实的回归系数。在贝叶斯的主观概率观中,所有的未知参数都被视为不确定的,因此要用一个概率分布来描述。每个参数都是未知的,而所有未知的东西都会得到一个分布。
这就是为什么在频率推断中,你主要得到的是一个未知但固定的群体参数的点估计。这是一个参数值,考虑到数据,它最有可能出现在人群中。附带的置信区间试图让你进一步了解这个估计值的不确定性。重要的是要认识到,置信区间只是构成一个模拟量。在从人口中抽取的无限多的样本中,构建(95%)置信区间的程序将使其在95%的时间内包含真实的人口值。这并没有为你提供任何信息,即人口参数位于你所分析的非常具体和唯一的样本中的置信区间边界内的可能性有多大。
在贝叶斯分析中,你推断的关键是感兴趣的参数的后验分布。它满足了概率分布的每一个属性,并量化了人口参数位于某些区域的概率。一方面,你可以通过它的模式来描述后验的特点。这是一个参数值,考虑到数据和它的先验概率,它在人群中是最有可能的。另外,你也可以使用后验的平均数或中位数。使用相同的分布,你可以构建一个95%的置信区间,与频率主义统计中的置信区间相对应。除了置信区间之外,贝叶斯的对应区间直接量化了人口值在一定范围内的概率。所关注的参数值有95%的概率位于95%置信区间的边界内。与置信区间不同,这不仅仅是一个模拟量,而是一个简明直观的概率声明。
问题:解释估计效果、其区间和后验分布
答案:年龄似乎是预测博士延期的一个相关因素,后验平均回归系数为2.317,95%HPD(可信区间)[1.194 3.417]。另外,age2似乎也是预测博士延期的一个相关因素,后验平均值为-0.022,95%可信区间为[-0.033-0.01]。95%的HPD显示,人口中的这些回归系数有95%的概率位于相应的区间内,也请看下面的数字中的后验分布。由于0不包含在可信区间内,我们可以相当肯定存在影响。
问题: 每个贝叶斯模型都使用一个先验分布。描述一下回归系数的先验分布的形状。
回答:
检查使用了哪些默认的先验。

(Jags)利用一个非常宽的正态分布来得出这个无信息的先验。默认情况下,平均值为0,标准差为10(精度为0.01)。
回归--用户指定的先验
你也可以手动指定你的先验分布。理论上,你可以使用你喜欢的任何一种分布来指定你的先验知识。然而,如果你的先验分布不遵循与你的似然相同的参数形式,计算模型可能会很麻烦。 共轭先验避免了这个问题,因为它们采用了你构建的模型的函数形式。对于你的正态线性回归模型,如果你的回归参数的预设是用正态分布来指定的,就可以达到共轭性(残差得到一个反伽马分布,这里忽略不计)。你可以很灵活地指定信息性先验。
让我们用共轭先验来重新指定上面练习的回归模型。我们暂时不涉及截距和残差的预设。关于你的回归参数,你需要指定其正态分布的超参数,即均值和方差。平均值表示你认为哪一个参数值最有可能。方差表示你对此的确定程度。我们为β年龄回归系数和β年龄2系数尝试了4种不同的先验规范。
首先,我们使用以下先验。
Age ~ N(3,0.4)
Age2 ~ N(0,0.1)
先验指标是在模型制定步骤中设置的。请注意,精度而不是正态分布的方差。精度是方差的倒数,所以方差为0.1对应的精度为10,方差为0.4对应的精度为2.5。
先验参数在代码中呈现如下。
'#带有priors的回归模型
prior("dnorm(3,2.5)")*age + prior("dnorm(0,10)")*age2现在拟合模型并提供汇总统计。
回答:
summary(fit)
问题 在下表中填写结果。
| 年龄 | 默认情况下 先验 | N(3,.4) | N(3,1000) | N(20,.4) | N(20,1000) |
|---|---|---|---|---|---|
| 后验平均值 | 2.317 | ||||
| 后验标准差 | 0.568 |
| 年龄2 | 默认情况下 先验 | N(0,.1) | N(0,1000) | N(20,.1) | N(20,1000) |
|---|---|---|---|---|---|
| 后验平均值 | -0.022 | ||||
| 后验标准差 | 0.006 |
回答:
| 年龄 | 默认情况下 先验 | N(3,.4) | N(3,1000) | N(20,.4) | N(20,1000) |
|---|---|---|---|---|---|
| 后验平均值 | 2.317 | 2.625 | |||
| 后验标准差 | 0.568 | 0.408 |
| 年龄2 | 默认情况下 先验 | N(0,.1) | N(0,1000) | N(20,.1) | N(20,1000) |
|---|---|---|---|---|---|
| 后验平均值 | -0.022 | -0.026 | |||
| 后验标准差 | 0.006 | 0.004 |
下一步,尝试改编代码,使用其他列的先验规范,然后完成该表。
回答:
'#有priors的回归模型~ prior("dnorm(3,0.001)")*age + prior("dnorm(0,0.001)")*age2summary(prior2)
summary(prior3)
summary(prior4)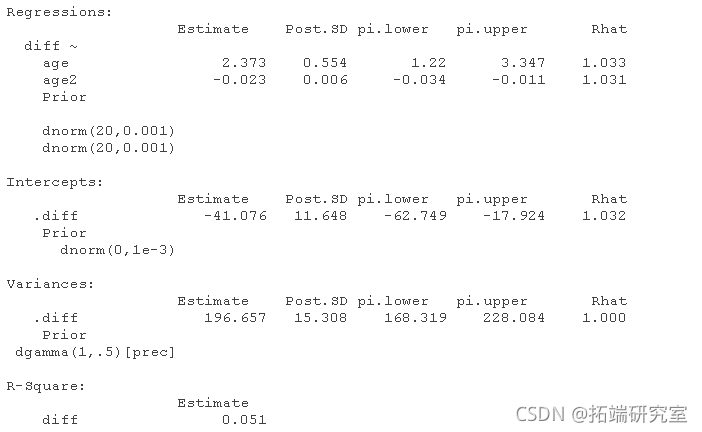
| 年龄 | 默认情况下 先验 | N(3,.4) | N(3,1000) | N(20,.4) | N(20,1000) |
|---|---|---|---|---|---|
| 后验平均值 | 2.317 | 2.625 | 2.422 | 11.143 | 2.457 |
| 后验标准差 | 0.568 | 0.408 | 0.502 | 0.536 | 0.576 |
| 年龄2 | 默认情况下 先验 | N(0,.1) | N(0,1000) | N(20,.1) | N(20,1000) |
|---|---|---|---|---|---|
| 后验平均值 | -0.022 | -0.026 | -0.023 | -0.113 | -0.024 |
| 后验标准差 | 0.006 | 0.004 | 0.005 | 0.006 | 0.006 |
问题:比较不同先验的结果。结果是否与默认模型有可比性?
问题:使用不同的先验,我们最终的结论是否相似?
要回答这些问题,请按以下步骤进行。我们可以计算出相对偏差来表示这种差异。我们将只计算两个回归系数的偏差,比较默认(无信息)模型和使用N(20,.4)和N(20,.1)先验的模型。
#1)减去MCMC链的内容
fitbayes( what = "mcmc")#2) 绑定不同的链,计算回归系数的平均值(估计值)。colMeans(as.matrix(mcmc.list)#3) 计算偏差
100*((estimat-estimat)/estimat)![]()
beta[1,2,1]和beta[1,3,1]指数分别代表了βage和βage2。Beta[x,x,x]是回归系数(按照我们在模型中指定的顺序,所以首先是age,然后是age2),alpha[x,x,x]是截距,psi[x,x,x]是方差,def[x,x,x]是间接效应(如果你的模型中有这些)。它们的排列顺序与summary()输出中的顺序相同。因此,首先是回归系数,然后是截距,然后是协方差,然后是间接效应。
我们还可以通过绘制我们运行的五个不同模型的后验和先验来绘制这些差异。在这个例子中,我们只绘制年龄βage的回归系数。
首先我们提取5个不同模型的MCMC链,只针对这一个参数(βage=beta[1,2,1])。
binrows(posterior1.5, prior1.5)然后,我们可以通过使用以下代码绘制不同的后验和前验。
qplot(data = post,)+density(size = 1)+scale_x_continuous(limit )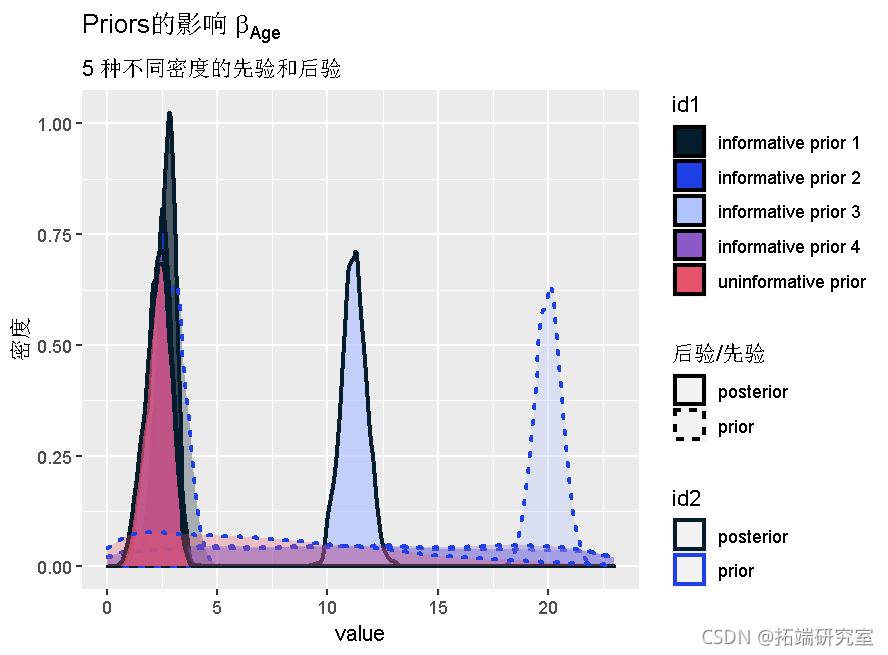
现在,根据表格中的信息、偏差估计和图表,你可以回答关于先验因素对结果的影响的两个问题。
答案
#1)减去MCMC链
fit.bayes(what = "mcmc")#2) 绑定不同的链,计算回归系数的平均值(估计值)。
colMeans(as.matrix(mcmc.list)#3) 计算偏差
100*((imstim-estima)/estimat)## beta[1,2,1] beta[1,3,1].
## 374.55 397.31![]()
我们看到,这种高信息量先验的影响对两个回归系数的影响分别为375%和397%左右。这是一个很大的差异,因此我们肯定不会得出类似的结论。
不同的先验,结果会发生变化,但仍具有可比性。只有对年龄使用N(20,.4),才会产生真正不同的系数,因为这个先验均值离数据的均值很远,而其方差却相当确定。然而,一般来说,其他的结果是可以比较的。因为我们使用了一个大的数据集,先验的影响相对较小。如果使用一个较小的数据集,先验的影响就会更大。为了检查这一点,你可以所有案例的大约20%进行抽样,然后重新进行同样的分析。结果当然会不同,因为我们使用的案例少了很多。使用这段代码。
indices <- sample.int(333, 60)
smalldata <- data[indices,]我们做了一个新的数据集,从原始数据集的333个观测值中随机选择了60个。用同样的代码重复分析,只改变数据集的名称,以观察先验因素对较小数据集的影响。用这个新的数据集运行priors2模型
fit.bayes(model = priors2,smalldata)
summary(fit)参考文献
Benjamin, D. J., Berger, J., Johannesson, M., Nosek, B. A., Wagenmakers, E.,… Johnson, V. (2017, July 22). Redefine statistical significance. Retrieved from psyarxiv.com/mky9j
Greenland, S., Senn, S. J., Rothman, K. J., Carlin, J. B., Poole, C., Goodman, S. N. Altman, D. G. (2016). Statistical tests, P values, confidence intervals, and power: a guide to misinterpretations. European Journal of Epidemiology 31 (4). Statistical tests, P values, confidence intervals, and power: a guide to misinterpretations | SpringerLink _ _
van de Schoot R, Yerkes MA, Mouw JM, Sonneveld H (2013) What Took Them So Long? Explaining PhD Delays among Doctoral Candidates. PLoS ONE 8(7): e68839. What Took Them So Long? Explaining PhD Delays among Doctoral Candidates | PLOS ONE

这篇关于R语言JAGS贝叶斯回归模型分析博士生延期毕业完成论文时间的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




