本文主要是介绍Differentially Private Federated Learning: A Client Level Perspective,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
我们的目标并不是只保护数据。相反,我们希望确保一个学习模型不会显示客户是否参与了分散的培训。这意味着客户机的整个数据集受到保护,不受来自其他客户机的差异攻击。
我们的主要贡献:首先,我们展示了在联合学习中保持较高的模型性能时,客户机的参与是可以隐藏的。我们证明了我们提出的算法可以在模型性能损失很小的情况下实现客户级差异隐私。与此同时发表的一项独立研究[6]提出了一个类似的客户级dp程序。然而,实验设置不同,[6]还包括元素级隐私措施。其次,我们提出在分散训练中动态调整保留dp的机制。实证研究表明,模型性能是通过这种方式提高的。与集中式学习相比,联合学习中的梯度对整个训练过程中的噪音和批量大小表现出不同的敏感性。
背景
联邦学习
在联合学习[5]中,管理者和客户之间的通信可能是有限的(例如移动电话)和/或容易被拦截。联邦优化的挑战是学习一个客户端和管理员之间的信息开销最小的模型。此外,客户的数据可能是非iid的、不平衡的和大规模分布的。[5]最近提出的“联邦平均”算法解决了这些挑战。在策展人与客户的多轮沟通中,对中心模型进行培训。在每一轮交流中,管理者将当前的中心模型分发给一小部分客户。然后客户端执行局部优化。为了最小化通信,客户端可能在单个通信轮中采取几个小批量梯度下降步骤。然后,将优化的模型返回给管理员,管理员将它们聚合(例如平均)以分配一个新的中心模型。根据新中心模型的表现,要么停止培训,要么开始新一轮的沟通。在联合学习中,客户机从不共享数据,只共享模型参数。
DP
在模型集中学习的情况下,数据层的数据保护问题已经做了大量的研究。这可以通过将保留dp的随机机制(如高斯机制)合并到学习过程中来实现。
https://blog.csdn.net/Ano_onA/article/details/100550926
https://blog.csdn.net/houzhizhen/article/details/78327217
https://www.zhihu.com/question/47492648/answer/194047182
https://ieeexplore.ieee.org/document/7911185/metrics#metrics
差分隐私的核心思想:对于差别只有一条记录的两个数据集,查询它们获得相同值的概率非常非常的接近。
如何做到差分隐私:在查询结果里加入随机性。最常用的方法是在结果上加满足某种分布的噪音,使查询结果随机化。
1.Laplace机制 :在查询结果里加入Laplace分布的噪音,适用于数值型输出。例如:zhihu里有多少人是985大学毕业的? 假如结果是2000人,那么每一次查询得到的结果都会稍稍有些区别,比如有很高的概率输出2001,也有较高概率输出2010, 较低概率输出1990,等等。
2.指数机制:在查询结果里用指数分布来调整概率,适用于非数值型输出。例如:中国top 3大学是哪一所。很高概率输出 浙江大学,较高概率输出上海交大,较低概率输出武汉大学,很低概率输出蓝翔技校,等等。
例子:早上查询了流感病人500人。我朋友A早上去医院看病。下午我一查,流感病人501人,那么我推测A很大可能患病。另要真正保护病人隐私,医院不能每次都公布准确数字,而应该在准确数字上加个噪声。要让这个查询满足DP,只要:医院公布的流感人数=精确人数+Laplace噪声。
直观地说,这意味着一旦学习模型显示某个数据点是否属于训练集的一部分的概率超过某个阈值,训练就会停止。
方法
在联邦优化[5]框架中,中心策展人在每一轮通信之后对客户端模型(即权重矩阵)进行平均。在我们提出的算法中,我们将使用随机机制来改变和近似这个平均值。这样做是为了将单个客户机的贡献隐藏在聚合中,从而隐藏在整个分散学习过程中。
我们用来近似平均值的随机机制包括两个步骤:
- 随机子抽样:设K为客户总数。在每一轮通信中采样一个大小为mt≤K的随机子集Zt。然后策展人将中心模型wt分发给这些客户。中心模型由客户对其数据进行优化。Zt中的客户端现在拥有不同的本地模型
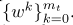
优化后的局部模型与中心模型之间的差异称为客户端k的更新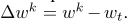 。在每一轮交流结束时,更新信息会被发送回中心策展人。
。在每一轮交流结束时,更新信息会被发送回中心策展人。 - 扭曲:高斯机制用于扭曲所有更新的总和。这需要了解集合对求和操作的敏感性。我们可以加强一定的敏感性,使用缩放版本,而不是真正的更新:
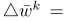
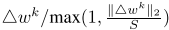
缩放确保第二个规范是有限的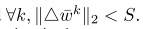
因此,相对于求和操作,缩放更新的灵敏度上限为s。GM现在将噪声(按灵敏度S调整)添加到所有按比例调整的更新的总和中。s将GM的输出除以mt,得到所有客户更新的真实平均值的近似值,同时防止泄露关于个人的重要信息。
在现有的中心模型wt的基础上,加入该近似,分配新的中心模型wt+1。

当将1 / mt分解为高斯机制时,我们注意到平均值的失真由噪声方差S2σ2/ m控制。但是,这种扭曲不应超过一定的限度。否则,过多的次采样平均信息会被添加的噪声破坏,不会对学习有进步。GM和随机子抽样都是随机的机制。(事实上,[1]正是在dp-SGD中使用了这种平均近似。但是,在这里它被用来进行梯度平均,在每次迭代中隐藏单个数据点的梯度)。也因此,σ和m定义隐私损失时随机机制提供了一个平均近似。
(我太难了。。。后面算法看不懂省略。。。)
实验
为了测试我们提出的算法,我们模拟了一个联邦设置。为了便于比较,我们选择了与[5]相似的实验设置。我们将排序后的MNIST集合分成碎片。因此,每个客户端获得两个切分。这样,大多数客户将只有来自两位数的样本。因此,单个客户无法对其数据进行训练,使其对所有10位数字都能达到较高的分类精度。
我们正在研究K∈{100,1000,10000}的场景的联邦设置中的差异隐私。在每个设置中,客户端将获得600个数据点。对于K∈{1000,10000},数据点是重复的。
对于所有三个场景K∈{100,1000,10000},我们对以下参数进行了交叉验证网格搜索:
- 每个客户的批次数量B
- 每个客户端上运行的时间段E
- 参与每轮m的客户端数m
- 通用参数σ
我们把ǫ的值定为8。在培训期间,我们使用隐私会计师跟踪隐私损失。当δ分别达到100、1000和10000个客户的e-3、e-5、e-6时,训练停止。此外,我们还分析了训练过程中客户之间的差异。上述实验的代码可从以下网址获得:
https://github.com/cyrusgeyer/DiffPrivate_FedLearning.

算法1客户端dp联邦优化。
k是参与客户端的数量;b是本地小批量大小,e是本地时间段(参与?)的数量,η是学习率,是GM的方差集。
决定参与每一客户端的数量.
ǫ定义了我们的目标dp。Q是δ的阈值,即ǫ-dp被破坏的概率。T是δ超过q的通信次数。B是保存客户数据的集合,该数据被切成大小为B的批次。
(T is the number of communication rounds after which δ surpasses Q. )

表1:差异性私人联合学习(DP)的实验结果和与非差异性私人联合学习(non-DP)的比较。100、1000和10000个客户的场景,隐私预算ǫ=8。δ′是ǫ-差异隐私被破坏的最高可接受概率。一旦达到δ′,训练就停止。准确度表示为“acc”,通信次数表示为“cr”,通信成本表示为“cc”。
实验结果
在交叉验证网格搜索中,我们寻找那些保持在δ的相应界限以下且达到最高精度的模型。此外,当多个模型达到相同的精度时,首选需要较少通信回合的模型。

图1:分散培训过程中客户持有的非IID MNIST数据的数字分类精度。对于dp联邦优化,精度曲线末端的点表示达到了δ-阈值,因此训练停止。
表1保存了K∈{100,1000,10000}找到的最佳模型。我们列出了准确性(ACC),所需的沟通轮数(CR)和产生的沟通成本(CC)。
通信成本定义为客户在培训过程中发送模型的次数,例如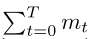 。
。

图2:100个客户机的场景,非DP:在联邦优化过程中,客户机之间的差异和更新规模的准确性
在图2中,再次描述了k=100的非dp联邦优化的准确性,以及训练过程中的客户间方差和更新规模。
实验结果讨论
参与客户的数量对实现的模型性能有很大的影响。对于100和1000个客户机,模型精度不收敛,并且显著低于非dp情况。然而,对于K∈{100,1000},78%和92%的准确率仍然比客户仅根据自己的数据进行训练所能达到的任何结果都要好得多。在K所处的这个数量级的领域中,dp是最重要的,这样的模型仍然会极大地使参与的客户受益。这种领域的一个例子是医院。几百人可以联合学习一个模型,而关于特定医院的信息则被隐藏起来。此外,联合学习模型可以作为进一步客户端培训的初始化。
对于k=10000,dp模型几乎达到了非dp模型的精度。这表明,对于涉及多方的场景(移动电话和其他消费设备),dp几乎不影响模型性能。
在交叉验证网格搜索中,我们还发现,在训练过程中提高Mt可以提高模型性能。观察一个早期的沟通回合,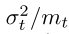 保持不变,降低Mt和σt,几乎不会影响该回合的增益精度。几乎不会影响这一轮的精度。然而,当两个参数都降低时,隐私损失就减少了。这意味着,在隐私预算耗尽之前,可以在训练中进行更多的沟通。在随后的通信回合中,获得较大的Mt才能获得准确性,并且必须考虑更高的隐私成本才能改善模型。
保持不变,降低Mt和σt,几乎不会影响该回合的增益精度。几乎不会影响这一轮的精度。然而,当两个参数都降低时,隐私损失就减少了。这意味着,在隐私预算耗尽之前,可以在训练中进行更多的沟通。在随后的通信回合中,获得较大的Mt才能获得准确性,并且必须考虑更高的隐私成本才能改善模型。
这一发现可以与信息论在学习算法方面的最新进展联系起来。
从图2中可以看出,Shwartz-Ziv和Tishby[8]提出,我们可以将训练分为两个不同的阶段:label fitting(标签拟合)和data fitting (数据拟合)阶段。
在标签拟合阶段,客户端更新相似,因此Vc较低,如图2所示。然而,在这个初始阶段,Uc是高的,因为对随机初始化的权重执行了大的更新。在数据拟合阶段,Vc的值上升。单个更新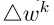 看起来不相似,因为每个客户都对自己的数据集进行了优化。
看起来不相似,因为每个客户都对自己的数据集进行了优化。
然而,当接近全局模型的局部最优值时,Uc却急剧缩小,精度收敛,贡献在一定程度上相互抵消。图2显示了Vc和Uc的依赖关系。
我们可以得出这样的结论:
- 通信回合的早期阶段,小的客户子集可能是代表真实数据分布的平均更新△wt的原因之一。
- 通信回合的后期阶段,需要一个平衡的(更大的)客户端比例,来达到一定代表性的更新。At later stages a balanced (and therefore bigger) fraction of clients is needed to reach a certain representativity for an update.
- Uc为高值时,使得早期更新不易受到噪声的影响。
结论
研究表明,在客户级别上实行dp是可行的,当涉及足够多的参与者时,可以达到较高的模型精度。
此外,仔细调查数据和更新分布可以优化隐私预算。
对于未来的工作,我们计划根据通信回合,数据代表性和客户端之间的方差来得出信噪比方面的最佳界限,并进一步研究与信息论的联系。
这篇关于Differentially Private Federated Learning: A Client Level Perspective的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








