相关文章

Kotlin 作用域函数apply、let、run、with、also使用指南
《Kotlin作用域函数apply、let、run、with、also使用指南》在Kotlin开发中,作用域函数(ScopeFunctions)是一组能让代码更简洁、更函数式的高阶函数,本文将... 目录一、引言:为什么需要作用域函数?二、作用域函China编程数详解1. apply:对象配置的 “流式构建器”最
![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)
[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs
引言 今天带来LoRA的量化版论文笔记——QLoRA: Efficient Finetuning of Quantized LLMs 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 我们提出了QLoRA,一种高效的微调方法,它在减少内存使用的同时,能够在单个48GB GPU上对65B参数的模型进行微调,同时保持16位微调任务的完整性能。QLoRA通过一个冻结的4位量化预

ACL22--基于CLIP的非代表性新闻图像的多模态检测
摘要 这项研究调查了假新闻如何使用新闻文章的缩略图,重点关注新闻文章的缩略图是否正确代表了新闻内容。在社交媒体环境中,如果一篇新闻文章与一个不相关的缩略图一起分享,可能会误导读者对问题产生错误的印象,尤其是用户不太可能点击链接并消费整个内容的情况下。我们提议使用预训练的CLIP(Contrastive Language-Image Pretraining)表示来捕捉多模态关系中语义不一致的程度。

《Efficient Batch Processing for Multiple Keyword Queries on Graph Data》——论文笔记
ABSTRACT 目前的关键词查询只关注单个查询。对于查询系统来说,短时间内会接受大批量的关键词查询,往往不同查询包含相同的关键词。 因此本文研究图数据多关键词查询的批处理。为多查询和单个查询找到最优查询计划都是非常复杂的。我们首先提出两个启发式的方法使关键词的重叠最大并优先处理规模小的关键词。然后设计了一个同时考虑了数据统计信息和搜索语义的基于cardinality的成本估计模型。 1.

《The Power of Scale for Parameter-Efficient Prompt Tuning》论文学习
系列文章目录 文章目录 系列文章目录一、这篇文章主要讲了什么?二、摘要中T5是什么1、2、3、 三、1、2、3、 四、1、2、3、 五、1、2、3、 六、1、2、3、 七、1、2、3、 八、1、2、3、 一、这篇文章主要讲了什么? The article “The Power of Scale for Parameter-Efficient Prompt Tuning

Command line is too long. Shorten command line for IhswfldWebApplication or also for Spring Boot ..
工作中,使用idea启动服务时报错如下图: 解决方法:打开启动配置页,选择 JAR mainfest, 点击 Apply, 点击 OK. 再次启动项目

利用clip模型实现text2draw
参考论文 实践 有数据增强的代码 import mathimport collectionsimport CLIP_.clip as clipimport torchimport torch.nn as nnfrom torchvision import models, transformsimport numpy as npimport webpfrom PIL impor
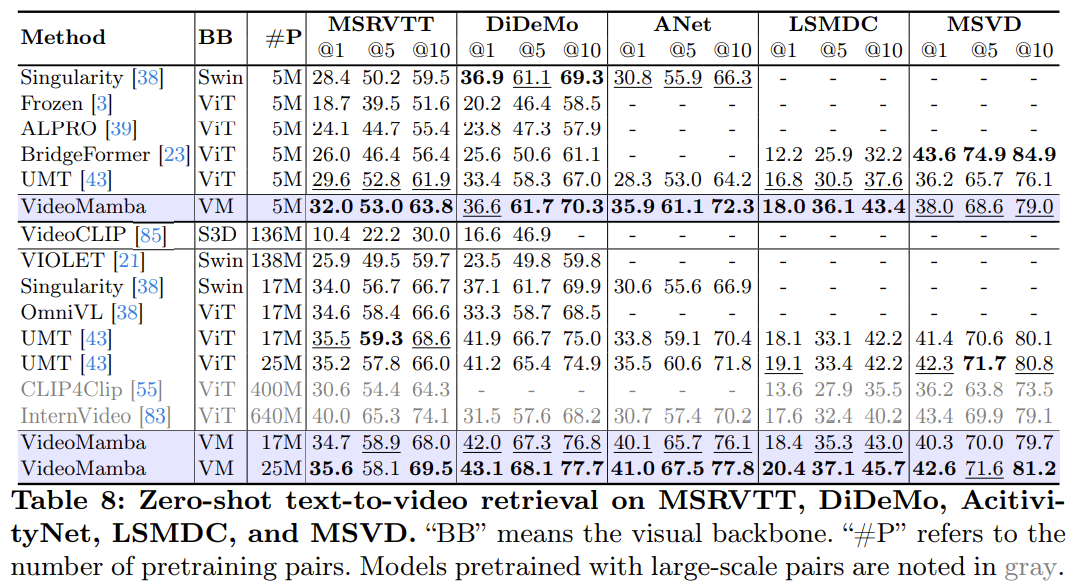
论文阅读:VideoMamba: State Space Model for Efficient Video Understanding
论文地址:arxiv 摘要 为了解决视频理解中的局部冗余与全局依赖性的双重挑战。作者将 Mamba 模型应用于视频领域。所提出的 VideoMamba 克服了现有的 3D 卷积神经网络与视频 Transformer 的局限性。 经过广泛的评估提示了 VideoMamba 的能力: 在视觉领域有可扩展性,无需大规模数据集来预训练。对于短期动作也有敏感性,即使是细微的动作差异也可以识别到在长期视

Efficient LoFTR论文阅读(特征匹配)
Efficient LoFTR论文阅读(特征匹配) 摘要1. 引言2. 相关工作基于检测器的图像匹配无检测器图像匹配 3. 方法3.1. 局部特征提取3.2. 高效的局部特征变换3.3. 准备工作3.4. 聚合注意力机制3.5 粗级匹配模块有效推理策略子像素级细化模块有效的精细特征提取两阶段相关细化 3.6 损失函数粗级匹配监督精细级匹配监督 4. 实验4.1. 实施细节4.2. 相对姿态
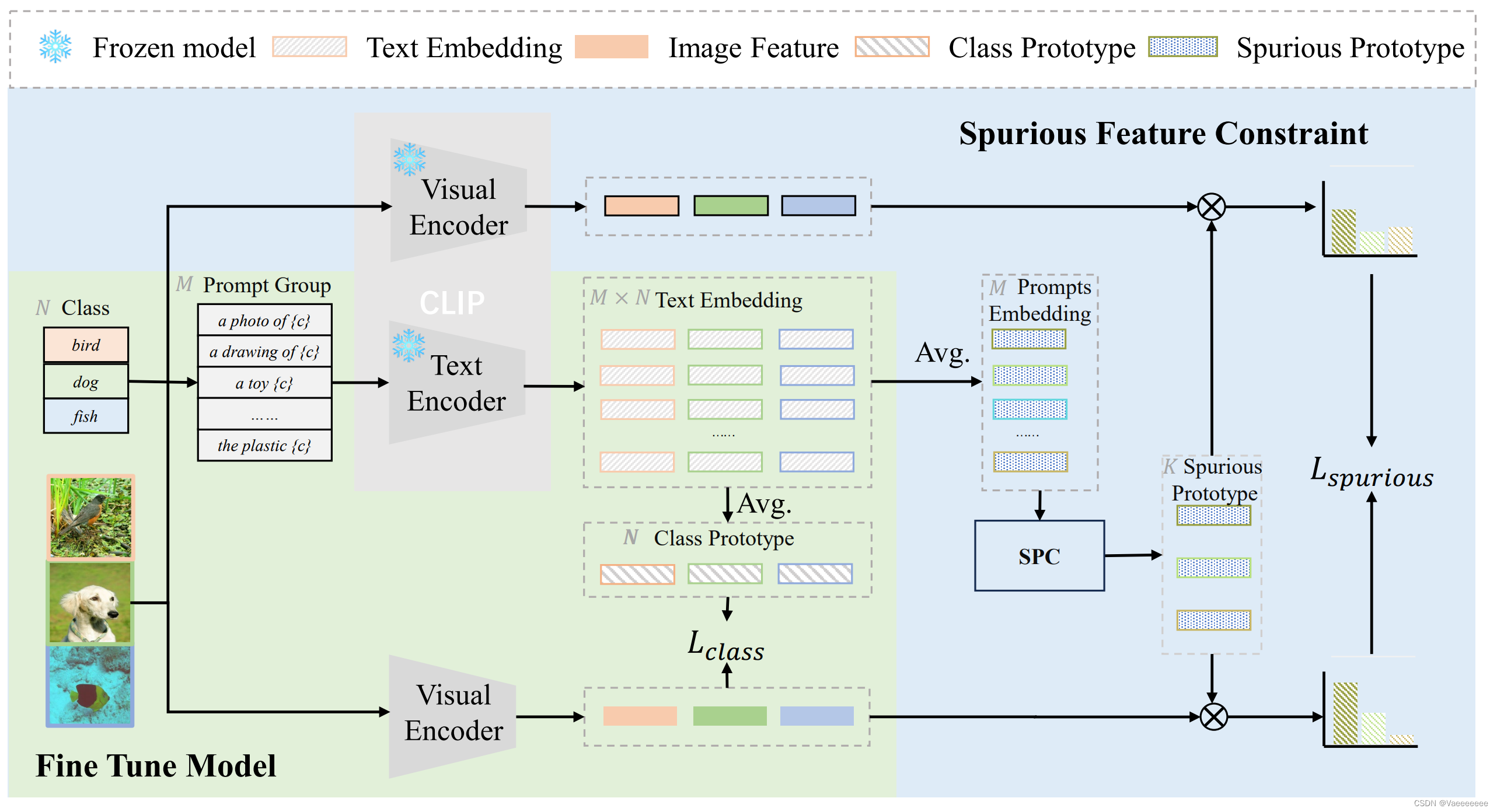
CLIP微调方法总结
文章目录 前言1️⃣ Tip-Adapter论文和源码原理介绍 2️⃣Cross-modal Adaptation(跨模态适应)论文和源码原理介绍 3️⃣ FD-Align(Feature Discrimination Alignment,特征判别对齐)论文和源码原理介绍 总结 前言 本文主要介绍和总结了三种不错的 C L I P CLIP CLIP微调方法,包括原理和思