本文主要是介绍优化器(一)torch.optim.SGD-随机梯度下降法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
torch.optim.SGD-随机梯度下降法
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(1024, 64),nn.Linear(64, 10))def forward(self, x):x = self.model1(x)return xtudui = Tudui()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
for epoch in range(20):running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)result_loss = loss(outputs, targets)optim.zero_grad()result_loss.backward()optim.step()running_loss += result_lossprint(running_loss)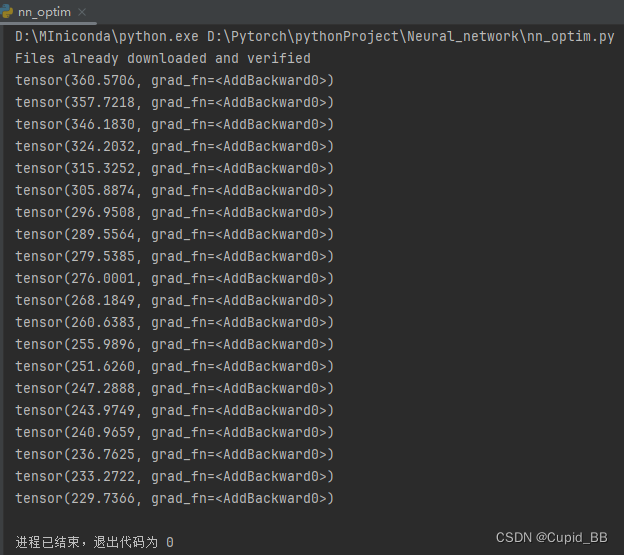
这篇关于优化器(一)torch.optim.SGD-随机梯度下降法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



