本文主要是介绍实现目标检测中的数据格式自由(labelme json、voc、coco、yolo格式的相互转换),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在进行目标检测任务中,存在labelme json、voc、coco、yolo等格式。labelme json是由anylabeling、labelme等软件生成的标注格式、voc是通用目标检测框(mmdetection、paddledetection)所支持的格式,coco是通用目标检测框(mmdetection、paddledetection)所支持的格式,yolo格式是yolo系列项目中所支持的格式。在进行实际项目中,通常不会局限于一个检测框架,故而数据格式也不会局限于一种。为此博主整理了互联网上相关的数据格式转换代码,方便各位的使用。
1、json格式转yolo
这里是指将json格式转yolo格式,具体包括目标检测、关键点检测、实例分割,旋转框检测等(最新的yolov8项目支持以上任务)。具体代码如下所示,其可以将json格式转为yolo格式,在json文件同目录下生成yolo格式的txt文件
import json
import numpy as np
import os,cv2
#把json格式的标注转换为yolo格式
def json2yolo(path,cls_dict,types="bbox"):# 打开文件,r是读取,encoding是指定编码格式with open(path ,'r',encoding = 'utf-8') as fp:# load()函数将fp(一个支持.read()的文件类对象,包含一个JSON文档)反序列化为一个Python对象data = json.load(fp)h=data["imageHeight"]w=data["imageWidth"]shapes=data["shapes"]all_lines=""for shape in shapes:if True:#转成np数组,为了方便将绝对数值转换为相对数值points=np.array(shape["points"]) #把二维list强制转换np数组 shape为n,2#print(points)#[[x1,y1],[x2,y2]]if types=="bbox":print(len(points))x, y, wi, hi = cv2.boundingRect(points.reshape((-1,1,2)).astype(np.float32))cx,cy=x+wi/2,y+hi/2cx,cy,wi,hi=cx/w,cy/h,wi/w,hi/hmsg="%.2f %.2f %.2f %.2f"%(cx,cy,wi,hi)else:points[:,0]=points[:,0]/w #n,2数组的第0列除以wpoints[:,1]=points[:,1]/h #n,2数组的第1列除以h#把np数组转换为yolo格式的strpoints=points.reshape(-1)points=list(points)points=['%.4f'%x for x in points]#把float型的list转换为str型的listmsg=" ".join(points)l=shape['label'].lower()line=str(cls_dict[l])+" "+msg+"\n"all_lines+=lineprint(all_lines)filename=path.replace('json','txt')fh = open(filename, 'w', encoding='utf-8')fh.write(all_lines)fh.close()
#定义文件路径
path="labelme-data"
path_list=os.listdir(path)
cls_dict={'cls0':0,'cls1': 1, 'cls2': 2, 'cls3': 3}
path_list2=[x for x in path_list if ".json" in x]
for p in path_list2:json2yolo(path+"/"+p,cls_dict)
2、yolo格式转voc
参考博客:python工具方法 41 对VOC|YOLO格式的数据进行resize操作(VOC与YOLO数据相互转换) 中2.2节的内容,可以实现将yolo格式转voc格式。yolo格式数据转换为voc数据后,可以使用mmdetecion、paddledetection等框架进行训练。
需要注意的是,yolo数据以id描述类别,而voc数据以name描述类别,故而需要设置cls_dict来描述id与name的对应关系

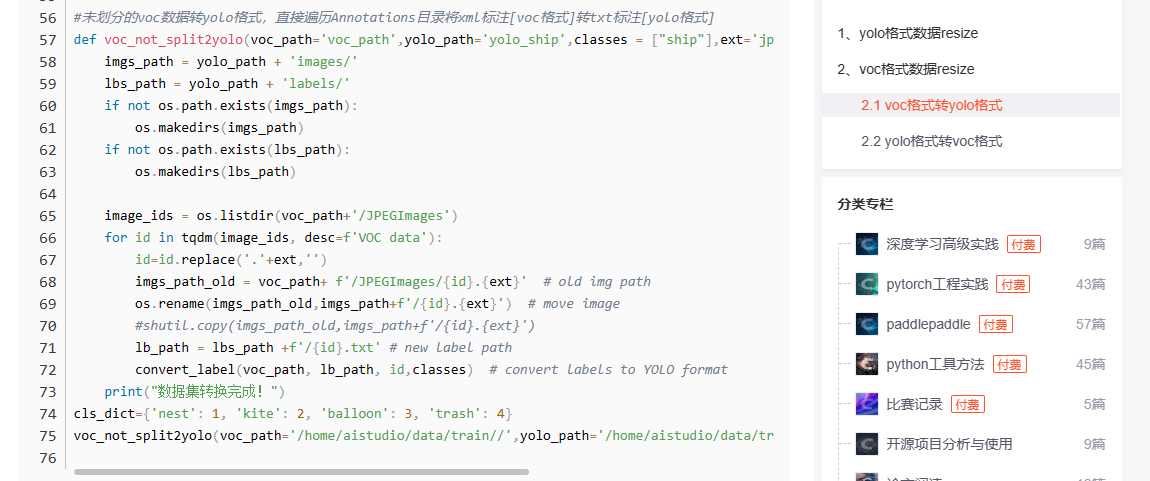
3、voc格式转yolo
参考博客:python工具方法 41 对VOC|YOLO格式的数据进行resize操作(VOC与YOLO数据相互转换) 中2.1节的内容,可以实现将voc格式转yolo格式。voc格式数据转换为yolo后,可以对图像进行resize操作,以训练模型提升图像加载速度。
需要注意的是,yolo数据以id描述类别,而voc数据以name描述类别,故而需要设置cls_dict来描述id与name的对应关系
4、voc数据转json
代码摘抄自互联网。其空将xml描述的voc数据转换为json格式,使得我们可以利用labelme等软件对标签进行可视化与调整
"""Author:DamonZhengFunction:xml2json(for labelme)Edition:1.0Date:2022.2.21
"""import argparse
import glob
import os
import xml.etree.ElementTree as ET
import json
from tqdm import tqdmdef parse_args():"""参数配置"""parser = argparse.ArgumentParser(description='xml2json')parser.add_argument('--raw_label_dir', help='the path of raw label', default=r'el-voc2/Annotations')parser.add_argument('--pic_dir', help='the path of picture', default=r'el-voc2/JPEGImages')parser.add_argument('--save_dir', help='the path of new label', default=r'el-voc2/Jsons')args = parser.parse_args()return argsdef read_xml_gtbox_and_label(xml_path):"""读取xml内容"""tree = ET.parse(xml_path)root = tree.getroot()size = root.find('size')width = int(size.find('width').text)height = int(size.find('height').text)depth = int(size.find('depth').text)points = []for obj in root.iter('object'):cls = obj.find('name').text#pose = obj.find('pose').textxmlbox = obj.find('bndbox')xmin = float(xmlbox.find('xmin').text)xmax = float(xmlbox.find('xmax').text)ymin = float(xmlbox.find('ymin').text)ymax = float(xmlbox.find('ymax').text)box = [xmin, ymin, xmax, ymax]point = [cls, box]points.append(point)return points, width, heightdef main():"""主函数"""args = parse_args()labels = glob.glob(args.raw_label_dir + '/*.xml')for i, label_abs in tqdm(enumerate(labels), total=len(labels)):_, label = os.path.split(label_abs)label_name = label.rstrip('.xml')img_path = os.path.join(args.pic_dir, label_name + '.jpg')points, width, height = read_xml_gtbox_and_label(label_abs)json_str = {}json_str['version'] = '4.5.6'json_str['flags'] = {}shapes = []for i in range(len(points)):shape = {}shape['label'] = points[i][0]shape['points'] = [[points[i][1][0], points[i][1][1]], [points[i][1][0], points[i][1][3]], [points[i][1][2], points[i][1][3]],[points[i][1][2], points[i][1][1]]]shape['group_id'] = Noneshape['shape_type'] = 'polygon'shape['flags'] = {}shapes.append(shape)json_str['shapes'] = shapesjson_str['imagePath'] = label_name + '.JPG'json_str['imageData'] = Nonejson_str['imageHeight'] = heightjson_str['imageWidth'] = widthwith open(os.path.join(args.save_dir, label_name + '.json'), 'w') as f:json.dump(json_str, f, indent=2)if __name__ == '__main__':main()5、voc数据转coco
coco格式也基于json文件描述标注的,在paddledetection中使用voc格式训练时输出的指标是map50,而使用coco格式数据训练时输出的指标是coco map。基于map50是看不出最佳模型的性能差异,而基于coco map5095 则可以明显的看出各个模型性能的差异。
这里主要描述基于paddledetection将voc格式的数据转换为coco格式。现有数据格式如下,在Annotations中存储的是xml,在JPEGImages存储的是图片。

基于以下代码可以进行voc数据的格式化(进行输出划分),
#数据集划分
import os
voc_path='dataset/el-voc/'
root=voc_path+'JPEGImages'
# 遍历训练集
name = [name for name in os.listdir(root) if name.endswith('.jpg')]train_name_list=[]
for i in name:tmp = os.path.splitext(i)train_name_list.append(tmp[0])#读取数据
data_voc=[]
data_paddle=[]
for i in range(len(train_name_list)):line='JPEGImages/'+train_name_list[i]+'.jpg'+" "+"Annotations/"+train_name_list[i]+'.xml' data_voc.append(train_name_list[i])data_paddle.append(line)
#把数据翻10倍
#data_voc=data_voc*10
#data_paddle=data_paddle*10# 构造label.txt
cls_dict={'heipian':0,'heiban': 1, 'yinglie': 2, 'beibuhuashang': 3}
labels=list(cls_dict.keys())
print(data_paddle)
with open(voc_path+"label_list.txt","w") as f:for i in range(len(labels)):line=labels[i]+'\n'f.write(line)# 将数据随机按照eval_percent分为验证集文件和训练集文件
# eval_percent 验证集所占的百分比
import random
eval_percent=0.2
seed=1234
index=list(range(len(data_paddle)))
random.seed(seed)
random.shuffle(index)os.makedirs(voc_path+"ImageSets",exist_ok=True)#--------用于将数据转换为voc格式--------
# 构造验证集文件
cut_point=int(eval_percent*len(data_voc))
with open(voc_path+"ImageSets/test.txt","w") as f:for i in range(cut_point):if i!=0: f.write('\n')line=data_voc[index[i]]f.write(line)# 构造训练集文件
with open(voc_path+"ImageSets/trainval.txt","w") as f:for i in range(cut_point,len(data_voc)):if i!=cut_point: f.write('\n')line=data_voc[index[i]]f.write(line)#--------用于paddle训练--------
# 构造验证集文件
cut_point=int(eval_percent*len(data_paddle))
with open(voc_path+"test.txt","w") as f:for i in range(cut_point):if i!=0: f.write('\n')line=data_paddle[index[i]]f.write(line)
# 构造训练集文件
with open(voc_path+"trainval.txt","w") as f:for i in range(cut_point,len(data_paddle)):if i!=cut_point: f.write('\n')line=data_paddle[index[i]]f.write(line)
同以上代码后生成的数据文件如下所示,其中绿框中的数据用于paddledetection训练,红框中的数用于格式转换,其是严格的voc格式。

绿框中的数据如下所示:
JPEGImages/A03-NB07-01-13_aug1.jpg Annotations/A03-NB07-01-13_aug1.xml
JPEGImages/A06-NB13-01-01_aug0.jpg Annotations/A06-NB13-01-01_aug0.xml
JPEGImages/A02-NB16-09-21_aug1.jpg Annotations/A02-NB16-09-21_aug1.xml
JPEGImages/A03-NB01-01-28_aug0.jpg Annotations/A03-NB01-01-28_aug0.xml
JPEGImages/A05-NB08-04-26_aug1.jpg Annotations/A05-NB08-04-26_aug1.xml
红框中的数据如下所示:
A03-NB07-01-13_aug1
A06-NB13-01-01_aug0
A02-NB16-09-21_aug1
A03-NB01-01-28_aug0
A05-NB08-04-26_aug1
基于现有的数据格式,可以使用paddledetection提供的工具将voc数据转换为coco格式。其中输出目录为--output_dir=dataset/el-coco/annotations
python tools/x2coco.py --dataset_type voc --voc_anno_dir dataset\el-voc\Annotations --voc_anno_list dataset\el-voc/ImageSets/trainval.txt --voc_label_list dataset/el-voc/label_list.txt --voc_out_name instances_train2017.json --output_dir dataset/el-coco/annotationspython tools/x2coco.py --dataset_type voc --voc_anno_dir dataset\el-voc\Annotations --voc_anno_list dataset\el-voc/ImageSets/test.txt --voc_label_list dataset/el-voc/label_list.txt --voc_out_name instances_val2017.json --output_dir dataset/el-coco/annotations
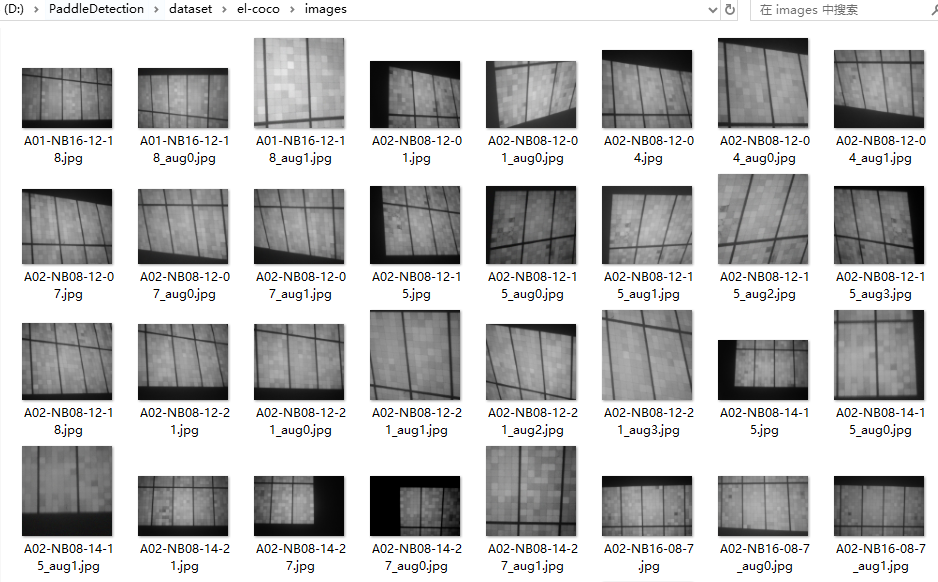
然后在dataset/el-coco/中创建images目录,将voc数据中的jpg图片拷贝到images目录中,具体如下所示:
在训练时,yml文件的数据配置写法如下所示:
metric: COCO
num_classes: 4
TrainDataset:name: COCODataSetimage_dir: imagesanno_path: annotations/instances_train2017.jsondataset_dir: dataset/el-cocodata_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']EvalDataset:name: COCODataSetimage_dir: imagesanno_path: annotations/instances_val2017.jsondataset_dir: dataset/el-cocoallow_empty: trueTestDataset:name: ImageFolderanno_path: annotations/instances_val2017.json # also support txt (like VOC's label_list.txt)dataset_dir: dataset/el-coco # if set, anno_path will be 'dataset_dir/anno_path'
这篇关于实现目标检测中的数据格式自由(labelme json、voc、coco、yolo格式的相互转换)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




